Materiály k predmetu Tvorba informačných systémov
0. Úvod
Tento dokument slúži ako doplnkový sumarizujúci text s informáciami, ktoré boli pokryté v kurze. Nemal by byť
jedinou náhradou štúdijnej literatúry. V jednotlivých odporúčaných publikáciách pôvodní autori uvádzajú
informácie rozpísané podrobnejšie a čitateľovi odporúčame sa im nevyhnúť. Tej-ktorej príslušnej špecializácii
sa daní autori venujú dlhodobo a zozbierali svoje skúsenosti a poznatky do učebnicového formátu. Tento dokument
teda iba zoskupuje materiál z rôznych zdrojov do jedného celku, tak ako sme ho postupne na prednáškach
preberali a ako sa na neho budeme odkazovať aj v záverečnom teste.
Informatika ako disciplína sa delí na mnoho podoblastí. Jej rozdelenie by sme mohli urobiť podľa rozličných
uhlov pohľadu. Či sa ale dívame na základy informatiky ako vedy alebo na jej množstvo aplikácií, jedno
podstatné kritérium rozdeľuje informatikov na dve kategórie ľudí:
- výskumníkov, čiže ľudí, ktorí sa zaoberajú novými metódami, algoritmami, reprezentáciou dát, programovacími
jazykmi, ... teda tých, ktorí rozširujú poznanie ľudstva o automatickom spracovávaní informácií na počítačoch;
- tvorcov reálnych systémov nasadených do prevádzky, ktorí spravidla používajú už overené - často
štandardizované postupy, nástroje, metódy a technológie na to, aby v organizovanom procese vytvorili dielo
podľa potreby praxe.
Tak ako žiadne iné, ani toto rozdelenie nie je čierno-biele a nájdeme výskumníkov, ktorí vytvárajú informačné
systémy a naopak inžinierov, ktorí pri tvorbe systémov prispievajú aj k pokroku informatických vied a rozvoju
nových technológií.
Uvedené rozdelenie budeme považovať za naše východisko a v celom tomto predmete sa zameriame na druhý typ
aktivity, čiže budovanie rozsiahlejších informačných systémov podľa konkrétnej požiadavky praxe. Hoci štúdium
na FMFI UK je väčšinou orientované na získavanie poznatkov pre vykonávanie prvého typu aktivity, každý
informatik by mal mať dobrý prehľad o informatike aj z hľadiska "inžinierskeho" - čiže z hľadiska zaužívaných
efektívnych postupov pri budovaní systémov. Alternatívny názov nášho predmetu by teda mohol byť "Úvod do
softvérového inžinierstva". Softvérové inžinierstvo má veľa spoločného s inými inžinierskymi odvetviami -
proces vývoja nového výrobku, diela, má svoje pravidlá - tak ako stavbár nemôže začať stavať múr bez toho, aby
mu najskôr architekt nenavrhol plány celej stavby a statik nespočítal, či stavba vydrží očakávanú záťaž, tak
ani informatik nemôže začať písať program bez toho, aby najskôr so zákazníkom poriadne nedohodol, čo ten naozaj
potrebuje a poriadne si neuvedomil ako bude výsledok vyzerať, z akých častí bude zložený, aké budu medzi
časťami závislosti a rozhrania.
Na druhej strane, preložiť kus zdrojového kódu z miesta na miesto je oveľa jednoduchšie ako preložiť vymurovanú
stenu, to však nemení nič na tom, že čím viac o výslednom systéme na začiatku vieme, tým menej bolestný
následný vývoj bude. Napriek tomu situáciu informatikov nepríjemne ovplyvňujú viaceré faktory: Rozvoj
informačných technológií je veľmi rýchly. Podmienky, v ktorých bude vyvíjaný systém pracovať, sa priveľmi
rýchlo menia a pri dodaní systému môže platiť už niečo celkom iné ako na začiatku vývoja. V porovnaní s inými
oblasťami je vývoj hotových systémov veľmi lacný. Pred začiatkom "murovania steny" často nie je možné
"nakresliť" a prediskutovať kompletný výsledný "obraz" pripravovaného systému. Naviac, vývojári si niekedy sami
nie sú istí, ako sa systém, ktorý plánujú vyvinúť, bude v praxi správať, koľko námahy a času si vývoj vyžiada.
Preto sa dnes softvérové inžinierstvo snaží reagovať na tieto javy vytváraním flexibilnejších postupov a
súborov odporúčaní ako takýto chaos zvládnuť.
Pri uvažovaní nad celkom nám v informatike veľmi často pomáha abstrakcia. Umožňuje nevšímať si detaily na
nižšej úrovni, zamerať sa na konkrétny problém bez straty kontroly nad celkom a vysporiadať sa tak s obrovskou
zložitosťou celého systému. Abstrakcia je jeden z najužitočnejších mechanizmov v informatike vôbec a cvičenia,
pri ktorých si uvedomíme, čo presne abstrakcia prináša, napr. písanie programov s viacvrstvovou hierarchickou
architektúrou alebo práca s abstraktnými kolekciami vo vyšších programovacích jazykoch ako Python a Java by už
pre nás mali byť známe veci, na ktorých môžeme stavať.
Text je rozdelený do 11 kapitol podľa tém prednášok takto: V prvej kapitole sa venujeme vývoju IS z hľadiska
atribútov kvality, zadefinujeme viaceré pojmy softvérového inžinierstva, fázy vývoja a hlavne vysvetlíme
rozličné modely vývoja softvéru. Hoci sa modely skoro nikde nepoužívajú vo svojej presnej podobe, tento prehľad
stále patrí do povinných základov softvérového inžinierstva. V druhej kapitole podrobne rozoberieme fázu
špecifikácie, ktorej kvalita je pre úspešnosť výsledného diela najdôležitejšia. Vývojári pri špecifikovaní a
navrhovaní zobrazujú štruktúru, vzťahy, správanie jednotlivých častí systémov graficky - v názorných obrázkoch.
Aby po sebe navzájom tieto obrázky dokázali čítať, zaužíval sa jednotný štandard na tvorbu diagramov - UML. V
tretej kapitole sa zoznámime s najviac používanými druhmi diagramov UML. V štvrtej kapitole sa venujeme
architektúre a návrhu softvérového systému - časť na ktorej dôsledné vypracovanie v praxi kvôli obmedzeným
zdrojom často bohužiaľ nedochádza. Každý systém ale nakoniec nejakú architektúru a návrh má a je užitočné
poznať ciele a prostriedky pri tvorbe "ideálneho" návrhu systému. Piata kapitola je prehľadom najpoužívanejších
návrhových vzorov - čiže ustálených postupov pri tvorbe architektúry a návrhu, ktoré vývojári využívajú
opakovane v rozličných informačných systémoch. Poznanie týchto (mohli by sme povedať štandardných) postupov
urýchľuje a skvalitňuje vývoj. V súčasnosti nie je žiaden informačný systém izolovaný od zvyšku sveta - nejakým
spôsobom si s okolím a ostatnými aplikáciami vymieňa údaje, nadväzuje na ich funkcionalitu. Šiesta kapitola sa
venuje otázkam vzájomného prepájania aplikácií do väčších celkov, čiže integrácii aplikácií. Ukážka jednej z
mnohých technológií, ktorá je používaná najmä v rozsiahlych aplikáciách vytvorených na platforme Java EE -
technológie anotácií v zdrojových kódoch, je stručne uvedená v siedmej kapitole. Vo fáze implementácie
informačného systému - teda samotného naprogramovania jeho častí - vývojári musia v praxi používať zásady
písania čistého kódu. Inak by sa vytvorené systémy veľmi skoro stali neudržiavateľné, ak by vôbec niekedy
vznikli. Zásadám čistého kódu podľa knihy A.C. Martina sa venuje ôsma kapitola. Záverečné tri kapitoly sú
stručnejšie a vychádzajú z pozvaných prednášok hostí. Deviata kapitola objasňuje zásady a odporúčania dnes tak
populárneho agilného vývoja pomocou metódy SCRUM. Desiata kapitola je o mäkkých zručnostiach (soft skills) -
čiže osobnostných spoločenských vlastnostiach a zručnostiach, ktoré si môžeme systematicky budovať s cieľom
dosahovania efektívnejšej spolupráce, vzájomného porozumenia pri práci na vývoji systémov i vôbec a
zamedzovaniu zbytočných konfliktov. Posledná kapitola uvádza prehľad základných faktov o informatizácií štátnej
správy v Slovenskej Republike, ktorá je podmienkou efektívneho fungovania spoločnosti v dnešnej dobe.
1. Uvedenie pojmov softvérového inžinierstva a modely vývoja informačných systémov
1.1. Kategórie SW
Vyvíjaný softvér môžeme rozdeliť do dvoch kategórií:
Krabicový softvér, ktorý je vytváraný pre veľkú skupinu zákazníkov, dodáva alebo predáva sa vo veľkých
nákladoch, je určený na všeobecné použitie - čiže typicky pokrýva viacero rôznych používateľských scenárov,
poskytuje množstvo funkcií, pričom väčšina používateľov využíva len malú časť z nich. Príkladmi sú známe
operačné systémy, textové alebo grafické editory, počítačové hry, výukové programy, programy na vytváranie
alebo prehrávanie multimédií, antivíry, zálohovací softvér a podobne. Niekedy sa označuje aj termínom COTS
(Commercial off the shelf), hoci sem patrí aj nekomerčný open-source softvér vyvíjaný širokou komunitou
vývojárov dobrovoľníkov. V prípade krabicového softvéru používatelia majú len malý a zväčša nepriamy vplyv na
proces vývoja SW.
Softvér na mieru - vytvorený pre jedného, alebo úzku skupinu zákazníkov "na mieru" pokrývajúc ich konkrétne
potreby. V takomto prípade používateľ využíva takmer všetku funkcionalitu softvéru a aktívne vstupuje do
procesu vývoja. Príkladmi môže byť softvér pre kuriérsku doručovaciu službu, telekomunikačného operátora,
kníhkupectvo, alebo transfúznu stanicu.
1.2. Štandardy a atribúty kvality
Medzinárodná organizácia pre štandardizáciu (ISO), ktorú rešpektuje aj Hospodárska rada OSN, prijala koncom 80.
rokov rodinu štandardov ISO 9000, ktoré špecifikujú požiadavky na systémy riadenia kvality výroby (nielen
softvéru). Ak spoločnosť postupuje podľa uvedených štandardov, malo by to zákazníkovi zaručiť, že jeho
očakávania na kvalitu výrobku budú splnené. Spoločnosť, ktorá požadované štandardy na kvalitu výrobného procesu
dodržiava, môže požiadať o vydanie certifikátu. Vtedy prebehne tzv. certifikačný audit, ktorý môže vykonať iba
spoločnosť, ktorá je na tento účel akreditovaná (tento typ povolania sa ľudovo niekedy označuje "kvalitár"). Od
prvej verzie bola rodina štandardov ISO 9000 štyrikrát novelizovaná, naposledy v septembri 2015 a organizácie majú tri roky, aby svoje postupy zosúladili s novými štandardami.
Aplikovanie štandardov ISO 9000 na oblasť softvérového inžinierstva upravuje samostatný štandard ISO 90003.
Z hľadiska kvality softvéru ako takého (čiže nie kvality procesu vývoja, ale kvality výsledného produktu)
existuje iný štandard ISO, konkrétne ISO/IEC 25010 (čo je nová verzia ISO 9126). Tento štandard definuje sadu
atribútov kvality, ktoré môžeme využiť pri zbieraní a kontrole požiadaviek na systém, stanovovaní cieľov
návrhu, testovaní, alebo hodnotení výsledného systému, či má požadované vlastnosti.
Pôvodný štandard rozdeľoval atribúty kvality na externé, interné a atribúty kvality pri používaní systému.
Externé atribúty sú také, ktoré môžeme pozorovať "zvonku" - sú určené správaním sa systému, príkladom takéhoto
atribútu je výkon - t.j. napr. ako rýchlo nám systém na dotaz zobrazí odpoveď pri zaťažení paralelnými dotazmi
od rozličných používateľov.
Interné atribúty naopak vieme posúdiť až pri pohľade "dovnútra" systému - a udávajú kvalitu návrhu, zdrojového
kódu, čiže napr. či je softvér flexibilný vzhľadom na zmenu požiadaviek, modulárny, obsahuje minimum závislostí
a podobne.
Atribúty kvality pri používaní systému sú určené až pri reálnom nasadení systému do prevádzky a vyplývajú z
konkrétnych interakcií používateľov so systémom.
Novší štandard rozlišuje len atribúty typu "Product quality" a atribúty typu "Quality in Use", sú znázornené na
obrázku 1.

Obr. 1: Atribúty kvality výrobku, podľa ISO/IEC 25010.

Obr. 2: Atribúty kvality pri používaní, podľa ISO/IEC 25010.
Prečítajme si spolu tento zoznam atribútov a zamyslime sa nad tým, čo jednotlivé atribúty označujú:
A Kvalita výsledného systému
Functional suitability - či vyvinutý softvér robí všetko, čo má robiť (kompletnosť), či to robí správne
(correctness) a primeraným spôsobom (appropriateness), čiže ani priveľmi nezjednodušuje ani príliš zbytočne
nekomplikuje.
Reliability - celková spoľahlivosť systému, t.j. systém je odladený, bez chýb a nepadá (maturity), vždy, keď má
byť k dispozícii tak k dispozícii je (availability), výpadok nejakého komponentu má minimálny vplyv na jeho
prevádzkyschopnosť (fault tolerance), a ak k prerušeniu prevádzky predsa len dôjde, systém je schopný sa
spamätať a uviesť do bezchybného chodu (recoverability).
Performance efficiency - využívanie zdrojov, čiže dobrá práca s časom - žiadne zbytočné čakania, prestávky a
odstávky (time behavior), optimálne využitie ostatných zdrojov - pamäť, disk, procesor, papier, prenos údajov
po sieti (resource utilization) a kapacita, čiže vyčísliteľné výkonnostné hranice systému ako napr. maximálny
počet používateľov, maximálny počet záznamov, ktoré systém zvládne efektívne spracovať alebo evidovať,
maximálny počet súčasne uskutočňovaných transakcií a podobne (capacity).
Usability - sa týka skúsenosti používateľa, ktorú pri práci so systémom získava - primeranosť (appropriatness),
zrozumiteľnosť (recognisability), dobrá podpora pre rýchle naučenie sa práce so systémom - či si používateľ naň
zvykne ľahko (learnability), efektívnosť ovládania - požadovanú funkcionalitu docielime jasne, prehľadne a
jednoducho (operability), odolnosť voči nesprávnym vstupom alebo správaniu používateľa - systém nás upozorní
pred tým ako sa nám niečo podarí poškodiť (user error protection), úhľadnosť (aesthetics), a možnosť
prispôsobenia sa používateľského rozhrania handicapovaným používateľom (accessibility).
Maintainability - čiže udržiavateľnosť systému je veľmi dôležitý interný atribút kvality, hovoríme tu o
modularite, čiže členení systému na nezávislé komponenty - moduly, ktoré možno do systému ľahko pridať alebo
odobrať a vytvárať tak bez zložitých úprav rozličné konfigurácie pre rozličných používateľov jednoduchým
zapájaním modulov do výsledného celku (modularity), možnosť využiť časti systému aj v iných systémoch
(reusability), čím automaticky získavame dobre navrhnuté rozhrania medzi modulmi, minimálnosť týchto rozhraní a
väčšiu nezávislosť modulov, schopnosť ľahkého náhľadu do útrob systému počas jeho činnosti - čo môže veľmi
zrýchliť a zjednodušiť hľadanie poruchy, chyby alebo anomálie v systéme(analysability), jednoduchá
modifikovateľnosť, možnosť úprav funkcionality (modifiability) a ľahká otestovateľnosť - čiže štruktúrovanosť
aplikácie do samostatných modulov, pre ktoré máme možnosť napísať nezávislé jednotkové testy a jednoznačná a
prehľadná architektúra, jasné vstupné a výstupné formáty údajov, všetko, čo nám dovolí napísať čo
najspoľahlivejšie testy (testability).
Security - čiže bezpečnosť z hľadiska ochrany údajov a prístupu k nim, treba mať na pamäti, že slovenské slovo
bezpečnosť môže vyjadrovať aj iný typ bezpečnosti - bezpečnosť práce/neohrozenia zdravia - vtedy hovoríme v
angličtine o safety. Security zahŕňa nevyzradenie utajovaných údajov (confidentiality), zabezpečenie
neporušiteľnosti údajov a komunikačných kanálov (integrity), nezapierateľnosť autora podpisu alebo autorizácie
(non-repudiation), jednoznačná vyvoditeľnosť zodpovednosti za každú akciu (accountability), overiteľná
nefalšovanosť informácií, autentickosť (authenticity).
Compatibility - vo svojej základnej forme predstavuje možnosť spoločného prevádzkovania rozličných systémov
súčasne vedľa seba (co-existence), v rozšírenej forme sú systémy súčinné, vymieňajú si údaje, alebo aktívne
zdieľajú zodpovednosť za jednotlivé úlohy, ktoré plnia (interoperability).
Portability - alebo prenositeľnosť systému na inú softvérovú alebo hardvérovú platformu: schopnosť
prispôsobenia sa špecifikám tej-ktorej platformy (adaptability), možnosť prevádzky na príslušnej platforme
(installability). V prípade jednotlivých komponentov systému sa prenositeľnosť vzťahuje aj na vymeniteľnosť
jednotlivých komponentov aplikácie bez toho, aby to ovplyvnilo funkcionalitu - napr. výmena databázového
ovládača alebo GUI knižnice (replaceability).
B Kvalita systému v prevádzke
Satisfaction - celková spokojnosť používateľa so systémom - užitočnosť (usefulness), dôveryhodnosť (trust),
uspokojenie (pleasure), pohodlie (comfort).
Effectivness - jednoduchá dosiahnuteľnosť želaných cieľov pri práci s programom, systém robí správne veci, aby
dosiahol želaný výsledok.
Freedom from risk - obmedzenie rizík neželaných výsledkov pri práci so systémom zahŕňa zamedzenie akcií s
neželanými dopadmi na hospodárenie používateľa (economic risk mitigation), ochrana zdravia (health and safety
risk mitigation), ochrana životného prostredia (environmental risk mitigation).
Efficiency - úspornosť, program dosahuje želané ciele minimalizovaním použítých zdrojov, úsporne.
Context coverage - schopnosť systému fungovať vo všetkých možných situáciách / kontextoch, ktoré boli
špecifikované (context completeness) i tých, ktoré špecifikované priamo neboli (flexibility).
Atribúty kvality softvéru sa často používajú pri špecifikovaní tzv. non-functional requirements, čiže
požiadaviek, ktoré sa nevzťahujú na funkcionalitu. Sú to požiadavky, ktoré sa netýkajú priamo toho ČO má
vyvíjaný systém robiť, ale AKO KVALITNE to má robiť.
1.3. Štruktúra nákladov na vývoj softvéru, úspešnosť SW projektov a stakeholderi
Pre typické projekty vytvárané na zákazku platí, že celkové náklady po odovzdaní prvej kompletnej a funkčnej
verzie do používania sú ešte 2-3-krát väčšie ako náklady potrebné na vývoj. Je to fáza evolúcie softvérového
diela, počas ktorej je potrebná oprava zistených nedostatkov, doplnenie funkcionality podľa dodatočných
požiadaviek zákazníka, udržiavanie rozličných verzií, ktoré boli nasadené do jednotlivých prevádzok.
Fáza vývoja systému po okamih jeho odovzdania si spravidla vyžiada veľmi veľkú časť nákladov na testovanie
(okolo 40%).
V 90-tych rokoch a v prvej dekáde nového milénia sa uskutočnilo viacero plošných prieskumov úspešnosti
softvérových projektov. Výsledky ukazujú, že približne štvrtina projektov vývoja softvéru bola celkom
neúspešná. Ďalších približne 50% nedopadlo podľa očakávaní a len zhruba štvrtina projektov uspela bez výhrad. O
čom tieto čísla hovoria? Dokazujú, že vývoj informačných systémov je veľmi zložitý a krehký proces, účastníci
kontraktov a ani vývojári nemajú realistické očakávania, neexistujú spoľahlivé postupy práce, chýbajú
skúsenosti s odhadovaním rozsahu prác, manažéri nevedia nastaviť vhodné pravidlá práce na projektoch a pružne
reagovať na vznikajúce ťažkosti počas vývoja a komunikácia medzi všetkými zainteresovanými účastníkmi je
nedostatočná a zlá.
Termín stakeholder pochádza z anglického "stake" - čo v základnom význame označuje najaký stĺp ale v prenesenom
nejaký podiel (predstavme si skupinu ľudí, každý drží jeden stĺp, na ktorom spočíva nejaká rozsiahlejšia stavba - povedzme most,
každý z nich má svoj podiel na tom, že stavba drží - a pochopiteľne tým pádom má do celej stavby čo rozprávať a
prípadne chce mať svoj podiel na vyberanom mýte od každého, kto prejde po moste).
Stake je teda určitý podiel a stakeholder je držiteľ nejakého podielu.
V kontexte vývoja informačných systémov je stakeholderom každý, kto akýmkoľvek spôsobom zasahuje do vývoja alebo
ho ovplyvňuje. Medzi hlavných stakeholderov patria:
- zadávateľ, zákazník alebo klient - čiže objednávateľ softvéroveho diela
- riešiteľ, dodávateľ, alebo vývojár, ktorý systém vyvinie a dodá
- používateľ, čiže osoba, ktorá bude so systémom pracovať
iné typické roly sú:
- prevádzkovateľ, čiže subjekt alebo osoba zodpovedná za udržiavanie systému v chode
- manažment - čiže riadiaci pracovníci, ktorí sa starajú o to, aby bol systém dodaný v požadovanom čase,
kvalite a funkcionalite, hoci sa priamo na vývoji nepodieľajú
- regulačné úrady v zastúpení firemných právnikov, alebo technológov z domény informačného systému,
ktorí dohliadajú na to, aby vyvinutý systém neporušoval žiadnu legislatívu, vnútorné pravidlá firmy, alebo
stanovené technologické postupy
- experti z domény informačného systému, ktorí ostatným definujú význam pojmov, entít, závislostí,
vstupov, výstupov, rozhraní a procesov v doméne, pre ktorú je IS vyvíjaný
- ekonómovia, ktorí sa starajú o návratnosť, realizovateľnosť a náklady projektu a ďalší.
1.4. Fázy vývoja informačného systému
Vývoj každého systému je iný a má svoje špecifiká, napriek tomu v každom z nich môžeme identifikovať činnosti
podobného charakteru, ktoré sa vykonávajú viac-menej v nasledujúcom poradí:
- Špecifikácia požiadaviek: jej cieľom je vytvorenie uceleného dokumentu označovaného ako Requirements
Document, alebo Katalóg požiadaviek (niekedy Špecifikácia požiadaviek), ktorý obsahuje zoznam jednotlivých
požiadaviek zadávateľa na funkcionalitu i výslednú kvalitu vyvíjaného softvéru. Špecifikácia by mala byť
písomnou dohodou medzi zadávateľom a riešiteľom, ktorá je pre obe strany záväzná. Špecifikácia odpovedá na
základnú otázku "ČO má systém robiť?"
- Návrh systému: v tejto fáze vývojári zanalyzujú zozbierané požiadavky, vyberú vhodné technológie, navrhnú
architektúru systému, rozdelenie na moduly, ich vzájomné rozhrania, rozhrania aplikácie navonok vrátane
používateľského rozhrania, perzistentnú vrstvu - dátový model databázy a formáty súborov, komunikačné
protokoly, pripravia si testovacie scenáre pre validačné a akceptačné testy, podrobne navrhnú vnútornú
štruktúru komponentov, modelujú správanie a interakciu častí systému. Výsledkom by v ideálnom prípade mal byť
dokument s názvom Software Design Description, alebo jednoducho Návrh systému. Dokument by mal obsahovať podrobný
návod pre vývojárov, ako majú systém vyvinúť, pričom by mal byť natoľko dôsledný a podrobný, aby dve nezávislé
vývojárske skupiny, ktoré podľa návrhu budú postupovať, vyvinuli softvér s ekvivalentnou funkcionalitou a
vlastnosťami. V praxi sa stretávame aj s tým, že skupina vývojárov, ktorá vypracuje návrh, je iná ako tá, ktorá
systém implementuje. V iných spoločnostiach, ktoré postupujú pri vývoji softvéru viac živelne, často návrh ako
taký nevzniká a tím sa snaží držať krok len s dokumentom popisujúcim špecifikáciu. To je možné iba v menších
tímoch a na menších projektoch. Návrh odpovedá na základnú otázku "AKO sa bude systém implementovať?"
- Implementácia: vytvára sa zdrojový kód jednotlivých modulov podľa návrhu. Jednotlivé elementy sa hneď
testujú jednotkovými testami. Do zdrojového kódu sa píšu dokumentačné komentáre.
- Verifikácia a validácia: overenie, že systém spĺňa špecifikované požiadavky (verifikácia) a že spĺňa
očakávania používateľa (validácia). Túto kontrolu vývojári musia vykonávať v celom procese vývoja, avšak
najviac prostriedkov sa na ňu vynakladá po implementácii.
- Evolúcia: nastáva po odovzdaní prvej plne funkčnej verzie systému. Systém sa opravuje a upravuje podľa
dodatočných požiadaviek alebo zistení zadávateľa a používateľov. Nastáva pri každom vývoji informačného systému
a väčšinou pohltí veľké množstvo nákladov, s ktorými treba vopred počítať.
1.5. Priebežné procesy pri vývoji IS
Počas všetkých fáz vývoja informačného systému prebiehajú viaceré procesy, ktorým musí byť venovaná potrebná
pozornosť. Ide predovšetkým o:
Odhadovanie - čiže stanovovanie nákladov, rozsahu prác a potrebných zdrojov - personálnych i materiálnych.
Plánovanie - čiže rozdeľovanie úloh, práce a zdrojov do časových harmonogramov, určovanie míľnikov,
stanovovanie postupností a nadväzností úloh a ich vzájomnej nezávislosti, aktualizovanie plánu podľa
dosiahnutých priebežných výsledkov.
Organizácia práce - vytváranie a aktualizovanie pracovného kolektívu, rozdeľovanie úloh a kontrola ich plnenia,
organizovanie pracovných stretnutí, stanovovanie zodpovednosti, určovanie toku vstupov, výstupov, dokumentov a
spolupráce tímov a jednotlivcov. Vhodné motivovanie pracovníkov - finančné i iné, zlepšovanie a utužovanie
vzťahov na pracovisku.
Na tieto činnosti sa bežne používa softvér na organizáciu práce, ktorý je často previazaný s celým informačným
systémom organizácie, systémom na zdieľanie dokumentov. Príkladom softvéru na správu projektu môže byť komerčná
sada nástrojov Oracle Primavera, alebo open-source systém OpenProject.
Typickým nástrojom je Ganttov diagram, zobrazujúci grafické rozloženie naplánovaných úloh v čase, ich členenie
na podúlohy, závislosť ich následnosti, množstvo už splnenej práce. Na x-ovej osi je čas z hľadiska
dní/týždňov/mesiacov, riadky na y-ovej osi zodpovedajú jednotlivým riešeným úlohám, väčšinou tiež zoradeným
chronologicky, čo ale nie je podmienkou a niekedy ani nie je možné. Vyplnené obdĺžniky znázorňujú plánované
trvanie úlohy v čase.

Obr. 3. Príklad Ganttovho diagramu.
Každý skutočný softvérový projekt má dokumenty i zdrojové súbory uložené v centrálnom repozitári. Vývojári majú
z repozitára "vytiahnuté" lokálne kópie súborov, na ktorých pracujú. Po dokončení ucelenej časti úprav novú
verziu posielajú naspäť do repozitára. V niektorých projektoch každá zmena podlieha schváleniu zodpovedným
pracovníkom - v prípade zdrojových kódov musí prejsť kontrolou, tzv. code review, kde sa stráži čistota kódu,
použitie dohodnutých štandardov i správna sémantika programov. Do repozitára sa nikdy neposielajú programy,
ktoré sú syntakticky nesprávne a ani sa nedajú skompilovať.
Každý absolvent nášho predmetu musí ovládať prácu aspoň s jedným konkrétnym systémom na správu zdrojových
súborov, napr. Subversion (svn), Git, resp. GitHub, alebo komerčným nástrojom Microsoft Team Foundation Server
(tfs).
Atribútom kvality softvéru sme sa už venovali vyššie a na ich dosiahnutie je potrebné, aby bol kvalitný aj
samotný proces vývoja, je predpokladom výslednej kvality vyvinutého systému. Preto nezanedbateľným priebežným
procesom je aj neustále zabezpečovanie kvality práce. Sem patrí aj príprava štandardných postupov a procedúr,
checklistov, štruktúry a obsahu vypracovávaných dokumentov, kontrola a meranie efektívnosti kvality práce.
1.6. Modely vývoja IS
Pri tak náročnom procese ako je vývoj informačného systému je potrebné postupovať podľa nejakého rámca, podľa
ktorého sa organizuje celá práca. Hovoríme o rozličných modeloch vývoja informačných systémov. Modely stanovujú
pravidlá, postupy, pracovnú terminológiu, formu dokumentácie, nadväznosť fáz, vstupy a výstupy fáz, druhy
pracovných schôdzí, zjednodušujú plánovanie a riadenie vývoja, pomáhajú vývojárom lepšie sa zorientovať vo
svojich zodpovednostiach a skontrolovať, že ich výstupy sú v súlade s očakávaniami ostatných členov vývojového
tímu.
Medzi základné všeobecné modely vývoja IS patria nasledujúce: vodopádový model, evolučný model, inkrementálny
model, vývoj s opakovaným použitím komponentov, vývoj formálnymi metódami, špirálový model, Unified process a
Rational Unified Process, agilné metódy a open source. Pri každom z nich sa pozastavíme a uvedieme ich výhody a
nevýhody.
Jednotlivé modely môže skúmať z hľadiska toho, či členovia vývojových tímov v každom okamihu rozumejú, čo majú
robiť a prečo (pochopiteľnosť) a aktuálny stav celého procesu a úlohy na ktorých všetci pracujú sú známe
(viditeľnosť), či je postup na jednotlivých etapách rýchly a svižný, alebo prácne zdĺhavý (rýchlosť), nakoľko
je daný model podporovaný automatizovanými prostriedkami - napr. nástrojmi CASE (Computer-Aided Software
Engineering).
1.6.1. Vodopádový model
Ide o najstarší model vývoja, ktorý je inšpirovaný ostatnými inžinierskymi disciplínami. Vychádza z postupnosti
realizovaných etáp, pričom vyžaduje, aby každá etapa bola celkom ukončená vrátane dokumentácie pred začatím
nasledujúcej etapy. Dôraz je preto kladený na dôkladné vypracovanie a zdokumentovanie každej etapy, aby sa
predišlo potrebe znovu otvárať predchádzajúce etapy po ich ukončení. V praxi sa tomu ale dá iba zriedka kedy
podarí celkom vyhnúť.

Obr. 4: Vodopádový model vývoja IS.
Výhodou vodopádových modelov je ľahšie udržovanie a kontrolovanie pracovnej disciplíny, dobrá zdokumentovanosť
všetkých činností, dobrá viditeľnosť a najmä možnosť zvoliť optimálnu architektúru, prostriedky, technológie a
naplánovať celý proces vývoja, keďže všetky požiadavky sú známe pred začatím fáz návrhu i implementácie.
Potreba špecifikovať všetky požiadavky na začiatku je zároveň aj hlavnou nevýhodou, existuje isté riziko
určenia nesprávnych požiadaviek a najmä, zadávateľ si na začiatku vývoja často nedokáže predstaviť, čo všetko
bude od systému vyžadovať. Návrat k predchádzajúcim etapám je náročný, keďže každá spätná zmena má dopad na
všetky nasledujúce fázy, ktoré treba reštartovať. Pri zlyhaní plánu pri vodopádovom modeli vývoja nie je k
dispozícii žiadna predbežná verzia a buď sa pokračuje, až kým systém nie je celý hotový, alebo sa vývoj musí
ukončiť bez výsledku ("všetko alebo nič"). Vodopádový model je možné používať iba vtedy, ak sú požiadavky na
systém vopred dostatočne jasné.
1.6.2. Evolučný model
Pri evolučnom vývoji sa systém vyvíja po častiach, pričom každá nová verzia sa špecifikuje, vyvíja a následne
testuje, čím postupne vznikajú jednotlivé verzie systému, ktoré už sú prevádzkovateľné, hoci neobsahujú celú
funkcionalitu. Vychádza sa iba z hrubého všeobecného opisu cieľovej aplikácie.
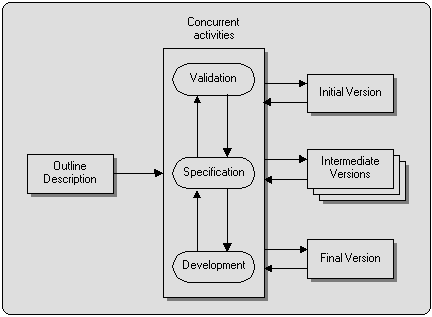
Obr. 5: Evolučný model vývoja IS.
Veľkou výhodou evolučného vývoja je, že sa špecifikácia vytvára postupne a skúsenosti používateľov z prevádzky
predchádzajúcej verzie sa využijú pri špecifikovaní nasledujúcich verzií. V prípade, že sa minú zdroje (čas,
peniaze), je možné nasadiť poslednú funkčnú verziu a projekt nezlyhal celkom. Zákazník má prvú fungujúcu verziu
k dispozícii oveľa skôr a môže ju hneď začať používať. Nevýhodou je, že model nevyžaduje dostatočnú disciplínu
pri vytváraní dokumentácie a preto je málo viditeľný. Keďže požiadavky nie sú vopred známe, štruktúra systému a
jeho architektúra často nie je optimálna, neustále zmeny vedú k vyššej pravdepodobnosti vzniku chýb. Tento
model vývoja nezodpovedá typickému modelu kontraktov / objednávok, kde sa väčšinou dohodne čo treba dodať,
koľko to bude stáť, ako dlho to bude trvať a systém sa realizuje a dodá. V tomto prípade je potrebné neustále
vyjednávať a dohadovať dodatky, čo je náročnejšie na manažovanie, keďže ku každému z nich by sa správne mali
vyjadriť všetci stakeholderi, k čomu často nedochádza, alebo sa tomu nevenuje dostatočná pozornosť a to vedie k
neskorším problémom. Model je vhodný najmä na systémy u ktorých sa neočakáva dlhodobá prevádzka a sú menšieho
alebo stredného rozsahu. Veľkosť projektu sa niekedy vyjadruje v tisíckach riadkov kódu (KLOC), čo má výpovednú
porovnávaciu hodnotu najmä pri použití štandardných programovacích jazykov typu C++ alebo Java a dodržiavaní
zásad čistého kódu.
1.6.3. Inkrementálny model
Je kombináciou vodopádového a evolučného modelu vývoja. Podobne ako v evolučnom modeli prebieha vývoj po
relatívne malých prídavkoch, inkrementoch. Odlišuje sa od neho väčším dôrazom na dokumentáciu, viditeľnosť,
disciplínu a manažovateľnosť procesov. Pred začiatkom vývoja prebehne zozbieranie hrubých požiadaviek na celý
system a naplánovanie vývoja na jednotlivé inkrementy. Na základe toho sa navrhne architektúra celého systému.
Počas vývoja sa postupne navrhujú, implementujú a testujú vznikajúce verzie, pričom jednotlivé inkrementy môžu
byť vyvíjané odlišnými postupmi - nevyžaduje sa jednotný prístup počas celého vývoja, ak si to okolnosti
vyžadujú.

Obr. 6: Inkrementálny model vývoja IS.
Má rovnaké výhody ako evolučný model, ale čiastočne sa zbavuje nevýhody nízkej viditeľnosti, neoptimálnej
architektúry a náročnej manažovateľnosti.
1.6.4. Vývoj s opakovaným použitím komponentov
V tomto prípade nemožno ani tak hovoriť o samostatnom modeli, ktorý pokrýva celý proces vývoja, ako skôr o
jeden aspekt, ktorý sa väčšinou kombinuje s iným modelom. Cieľom je maximalizovať úsporu času a prostriedkov
pri vývoji viacerých informačných systémov, ktoré majú spoločné prvky, vyčleniteľné do samostatných
univerzálnych, alebo ľahko prispôsobiteľných komponentov. Znovupoužitie komponentov si vyžaduje určitú
flexibilitu vývojového procesu už pri špecifikácii - nakoľko systém sa špecifikuje s východiskom existujúcich
znovupoužiteľných komponentov, pričom sa dosahuje kompromis medzi ideálnou funkcionalitou a vlastnosťami
systému na jednej strane a reálnymi možnosťami, ktoré sa dajú dosiahnuť využitím existujúcich komponentov.
Ďalšou výhodou popri úsporách je otestovanie zdieľaných komponentov vo viacerých rozličných situáciách, čo môže
viesť k robustnejšiemu a modulárnejšiemu návrhu a odladeniu chýb, ktoré by ostali skryté a objavili sa neskôr
počas prevádzky. Nevýhodou popri nutných kompromisoch je čiastočná strata kontroly nad budúcim vývojom a
podporou produktu, keďže znovupoužité komponenty "žijú" vo viacerých systémoch, na ktoré sa môžu v budúcnosti
vzťahovať odlišné požiadavky.
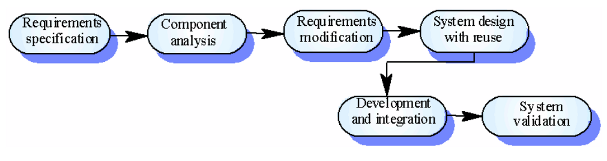
Obr. 7: Vývoj s opakovaným použitím komponentov.
1.6.5. Vývoj formálnymi metódami
Podobne ako predchádzajúci model ani tento nie je samostatným a kompletným scenárom na proces vývoja
informačného systému, ale akási "prísada", ktorá sa väčšinou kombinuje s iným modelom. Motiváciou je vyvinúť
systém, o ktorého vlastnostiach sa dá formálne niečo tvrdiť - napr. že výpočet zaručene skončí v stanovenom
čase, alebo vždy vykoná správnu akciu požadovanú v špecifikácii, alebo nikdy nedôjde k zablokovaniu paralelne
vykonávaných výpočtových vlákien. Je teda vhodný najmä pre vývoj systémov (alebo ich častí) s veľkými nárokmi
na spoľahlivosť, bezpečnosť, presnosť. Pri vývoji sa vytvorí klasická špecifikácia, ktorá sa formalizuje do
zvoleného formalizmu. K formalizmom existujú simulátory, analyzátory a softvérové knižnice, rozširujúce
klasické programovacie jazyky o nové prvky určené na formálne usudzovanie o činnosti programu, ktoré je často
založené na nejakej verzii predikátovej logiky.

Obr. 8: príklad postupu pri vývoji systému formálnymi metódami: z pôvodnej formálnej špecifikácie sa dôkazmi
(Px) získavajú verzie R1, R2, ..., až pokiaľ výsledok nie je priamo spustiteľný program. Metóda vychádza z
myšlienky, že dokázať správnosť jednotlivých transformácií je jednoduchšie, ako priamo dokazovať správnosť
výsledného programu.
1.6.6. Špirálový model
Ide o špecifický model zameriavajúci sa predovšetkým na určenie rizík a ich priorít. Metodológovia si
uvedomovali množstvo informačných systémov, ktoré boli neúspešné a preto sa do centra pozornosti dostáva
nepretržitá práca s rizikami vývoja a neustála prioritizácia aktivít podľa rizík vývoja. Podľa toho, ktoré
riziká sú v tom-ktorom projekte dôležitejšie, získame aplikovaním špirálového modelu nejaký konkrétny model
vývoja, ktorý môže byť napr. vodopádový, evolučný, alebo inkrementálny. Pri vývoji špirálovým modelom sa
postupuje cyklicky po špirále a opakujú sa štyri základné činnosti: 1. Zadefinovanie cieľov vyžadovaných
stakeholdermi, od ktorých závisí úspešnosť projektu 2. Nájdenie a vyhodnotenie rozličných prístupov k
dosiahnutiu týchto cieľov 3. Určenie a eliminovanie rizík, ktoré plynú zo zvoleného prístupu alebo skupiny
prístupov 4. Získanie súhlasu všetkých stakeholderov, na ktorých závisí úspešnosť projektu a realizácia
nasledujúceho cyklu. Dôraz je teda na to, aby sa predišlo nevhodným špirálam vo vývoji, kde by sa prirýchlo
začalo s návrhom a implementáciou systému, pričom by sa zanedbali niektoré dôležité aspekty - podcenili riziká.

Obr. 9: špirálový model vývoja informačných systémov.
1.6.7. Unified Process a Rational Unified Process
V 90-tych rokoch v softvérovom inžinierstve dominovali rozličné metódy objektovo-orientovaného softvérového
návrhu, ktoré kládli dôraz na mierne odlišné aspekty, používali čiastočne sa líšiace diagramy a postupy.
Zároveň vznikala prvá verzia unifikovaného modelovacieho jazyka UML. Prvky z pôvodne samostatných metód -
Boochova metóda, Rumbaughove OMT, Objectory (z prostredia spoločnosti Ericsson) - ktoré sa pripojilo k
spoločnosti Rational Software a dlhou históriou nástrojov na podporu vývoja softvéru i autori týchto metód sa
zlúčili pod krídlami spoločnosti IBM v úsilí o vytvorenie jednotného, flexibilného a podrobného frameworku na
tvorbu informačných systémov. Výsledkom je Unified Process, ktorý je ďalej podrobnejšie špecializovaný v metóde
Rational Unified Process (a niekoľkých ďalších, napr. Agile Unified Process alebo Oracle Unified Method).
Prístup by sa dal charakterizovať ako 1) Use-Case driven, čiže tvorba systému vychádza z používateľských
scenárov, ktoré sú základom pre špecifikáciu, analýzu a návrh, 2) Architecture-centric, čiže úvodné iterácie
vývoja sa sústreďujú na vytvorenie architektúry - spustiteľného jadra systému na ktorom sa stavia a 3)
Iterative and incremental, čiže vývoj pozostáva z jednotlivých malých iteračných cyklov vývoja, pričom v
priebehu vývoja sa množstvo práce venovanej jednotlivým aktivitám priebežne mení. Podobne ako v špirálovom
modeli je veľký dôraz na určenie rizík hneď od začiatku vývoja. Celkový životný cyklus vývoja Unified Process
pozostáva zo štyroch fáz: Inception (rozbeh), Elaboration (rozpracovanie), Construction (budovanie), Transition
(odovzdanie). Činnosť na vývoji je rozdelená do deviatich disciplín: šesť inžinierskych: Business Modeling
(modelovanie existujúcich procesov a vzťahov v cieľovej doméne informačného systému a hľadanie potenciálnych
zlepšení), Requirements (zbieranie, formulovanie, analyzovanie požiadaviek), Analysis and Design (analýza
hotových požiadaviek, návrh systému), Implementation (tvorba kódu podľa návrhu), Test (verifikácia a validácia
hotového kódu vzhľadom na návrh, špecifikáciu, a používateľov), Deployment (nasadenie systému do prevádzky) a
tri podporné disciplíny: Configuration and change management (správa verzií a zmien), Project management
(riadenie projektu), Environment (zabezpečenie vhodných nástrojov a celkového prostredia pre vývojárov).

Obr. 10: Rational Unified Process
Jednotlivé fázy su rozdelené do niekoľkých (spravidla 3-týždňových) iterácií. Každá z fáz má stanovené ciele,
ktoré sa počas nej vývojári usilujú dosiahnuť, ako vidno na nasledujúcom obrázku.

Obr. 11: Ciele jednotlivých fáz vo vývojovom modeli Unified Process
Výhodou UP a RUP je dôkladná a podrobná rozpracovanosť, vysoká flexibilita a dôraz na úspešné nasadenie
projektu zameraním sa na riziká. Nevýhodou sú vysoké náklady na manažment a celková komplexnosť.
1.6.8. Open-source
Jedna z najúspešnejších softvérových spoločností - Microsoft Corporation počas desaťročí používala uzatvorený
spôsob vývoja, kde k zdrojovým kódom systému mali prístup len vývojári. Podstatný dôvod je ochrana vlastníctva a práv,
aby si spoločnosť udržiavala svoje interné know-how a konkurenčnú výhodu oproti ostatným spoločnostiam na trhu.
Táto stratégia sa ukázala byť ako pomerne úspešná, keďže na poli operačných systémov pre stolné počítače,
kancelárskych softvérových balíkov, i vývojových nástrojov si firma udržala po desaťročia vedúcu pozíciu na
trhu. Na druhej strane vidíme úspešný príbeh operačného systému Linux, ktorého prvú verziu napísal jeden
nadšenec, zverejnil svoj zdrojový kód a otvoril systém pre vývojárov z celého sveta, ktorí do ďalších verzií
systému prispievali pridávaním nových a vylepšovaním existujúcich nástrojov, aplikačného softvéru, rôznych
verzií používateľského rozhrania a pod. Vznikla tak obrovská komunita vývojárov distribuovaných po celom svete,
ktorí venujú svoj čas a úsilie - niekedy zadarmo, niekedy za odmenu sponzorovanú spoločnosťami, ktoré v systéme
vidia potenciál - vývoju otvorených systémov. Prístup open-source umožňuje dosahovať vyššiu stabilitu a
bezchybnosť, keďže všetci používatelia a vývojári môžu v prípade nedostatkov hľadať a opravovať chyby priamo v
zdrojových kódoch, urýchľuje pokrok informačných technológií vôbec - keďže informácie a technológie sú
dostupnejšie a uľahčuje znovupoužiteľnosť komponentov a častí kódu vôbec. Napomáha prenositeľnosti programov na
rôzne platformy, keďže portovania pre každú platformu sa môže zhostiť iný tím. Tieto prednosti otvorenej
platformy zrejme nakoniec pochopila aj firma Microsoft, keď relatívne nedávno ohlásila, že jej populárna vývojová
platforma .NET, ktorej súčasťou je jazyk C# prejde do režimu open-source.
2. Tvorba katalógu požiadaviek (Requirements Specification)
Prvou veľkou a najdôležitejšou fázou vývoja informačného systému je tvorba katalógu požiadaviek (Requirements
Document), ktorý podrobne určuje, čo má produkt robiť na základe požiadaviek zadávateľa.
Výsledný katalóg požiadaviek musí byť napísaný jazykom, ktorý je zrozumiteľný. Jednak má byť zrozumiteľný
pre vývojový tím: nemôže sa spoliehať na odbornú terminológiu a poznatky z domény informačného systému bez toho,
aby boli vysvetlené. Po druhé musí byť zrozumiteľný aj pre zadávateľa: čiže nemôže obsahovať nevysvetlenú
terminológiu a poznatky ani z oblasti softvérového inžinierstva. Katalóg požiadaviek má byť čitateľný
a zrozumiteľný pre všetkých stakeholderov, ktorí s ním musia byť podrobne zoznámení a zadávateľ ho musí schváliť.
Medzi nich teda patria:
zadávateľ - kontroluje, či spísané požiadavky spĺňajú všetky potreby, ktoré na systém majú;
manažéri vývojového tímu - využívajú ho pri plánovaní a riadení procesu vývoja;
designéri - podľa katalógu požiadaviek vytvárajú návrh systému;
vývojári - postupujú podľa návrhu, ale ten sa odkazuje na katalóg požiadaviek, ktorý im pomáha pochopiť systém, ktorý vyvíjajú;
tvorcovia testov - podľa katalógu požiadaviek vytvárajú validačné testy;
správcovia výsledného systému - katalóg požiadaviek formuluje požiadavky aj na údržbu systému po jeho dodaní.
Výsledný dokument je záväzný pre obe strany a systém sa podľa neho ďalej navrhuje, implementuje a testuje.
Hlavným účelom katalógu požiadaviek je poskytnúť zoznam jednotlivých nedeliteľných požiadaviek, ktoré
sú jednoznačné a zrozumiteľné. Zoznam má byť vzhľadom na cieľovú funkcionalitu kompletný a konzistentný.
Mal by byť tématicky členený do jednotlivých častí. Samostatnú časť tvoria tzv. non-functional requirements,
čiže "ostatné požiadavky", ktoré určujú požiadavky nevzťahujúce sa na funkcionalitu. Predpisujú napr.
kvalitu a vlastnosti systému - zväčša vyjadrené formou atribútov kvality informačného systému, ktoré sú
vysvetlené v predchádzajúcej kapitole.

Obr. 12: Rôzne druhy ostatných požiadaviek (non-functional requirements).
2.1. Štruktúra dokumentu katalógu požiadaviek
Pre väčšiu zrozumiteľnosť sa zaužívala štandardizovaná štruktúra katalógu požiadaviek - jeho členenie
na kapitoly. Tvorbu katalógu požiadaviek popisuje viacero medzinárodných štandardov. V roku 1993 vznikla
prvá verzia štandardu 830, ktorý bol aktualizovaný v roku 1998. Po dlhšej prestávke bol v roku 2011
vydaný nový štandard
IEEE/ISO/IEC 29148. V prvých dvoch štandardoch (v ktorých vychádzame aj v našom
tímovom projekte) je dokument členený na nasledujúce kapitoly - pričom každý projekt si presnú štruktúru
podkapitol upraví podľa potreby, ide len o odporúčanú štruktúru:
1. Introduction
1.1 Purpose of requirements document
1.2 Scope of the product
1.3 Definitions, acronyms and abbreviations
1.4 References
1.5 Overview of the remainder of the document
2. General description
2.1 Product perspective
2.2 Product functions
2.3 User characteristics
2.4 General constraints
2.5 Assumptions and dependencies
3. Specific requirements: Covering functional, non-functional and interface requirements
4. Appendices
Index
Ako každý iný "slušný" dokument má katalóg požiadaviek v úvode v stati 1.1 napísané načo
je dokument určený a pre koho je určený. Aby čitateľ dokumentu vedel, čo práve drží
v ruke - hoci má nejakú predstavu, vždy je dobré, ak mu to autori pripomenú a jasne zadefinujú.
V stati 1.2. je opísaný rozsah systému: čo ešte patrí do systému, ktorý sa bude vyvíjať a čo už je
za hranicami jeho pôsobnosti, čo všetko - v hrubých rysoch pokrýva jeho funkcionalita?
Stať 1.3. je slovník pojmov. Nezavádzame ju "na silu" len preto, aby bola, ale treba si uvedomiť,
že dokument budú čítať aj ľudia, ktorí nevedia o doméne do ktorej sa ide informačný systém nasadiť
skoro nič a podobne ľudia, ktorí majú len veľmi hmlistú predstavu o tvorbe informačných systémov.
Preto kedykoľvek v texte použijeme nejaký pojem, ktorý nemusí byť automaticky zrejmý všetkým čitateľom,
pridáme ho do slovníka pojmov a vysvetlíme ho tam. Naopak, neuvádzame tu zbytočne prehľad terminológie,
ktorú nepoužívame alebo nie je pre informačný systém podstatná.
V stati 1.4. sa odkazujeme na všetky externé informácie, dokumenty, zákony, nariadenia, interné predpisy,
technologické postupy, manuály, dátové súbory, ktoré dal zadávateľ k dispozícii, zaužívané postupy a pod.
Všetko, čo nejakým spôsobom ovplyvňuje vznikajúci informačný systém a existovalo pred tým, ako začala
práca na vývoji.
Záver úvodnej kapitoly každého odborného dokumentu (tu stať 1.5) spravidla obsahuje stručný komentovaný
prehľad nasledujúcich kapitol, aby sa čitateľ vedel v celom dokumente zorientovať a rýchlo sa zamerať na to,
čo práve hľadá alebo sa ho týka.
Celá druhá kapitola (General description) je popis plánovaného systému prirodzeným jazykom, plynulými vetami
bez toho, aby sme išli do veľkých podrobností. Stať 2.1 zasadzuje systém do kontextu, díva sa na neho
z nadhľadu (perspektívy). Stať 2.2 by mala obsahovať stručný opis celej funkcionality - tak, aby čitateľ
z neho získal kompletnú predstavu, čo všetko systém bude robiť. Stať 2.3 má definovať používateľské role,
čiže typy používateľov, ktorí so systémom budú interagovať. Všeobecné obmedzenia v stati 2.4. určujú
ktoré predpisy a existujúca prax a akým spôsobom majú vecný vplyv na plánovaný systém. Predpoklady a
závislosti - stať 2.5. stanovuje konkrétne rozhrania systému s jeho okolím a ich vlastnosti.
Najdôležitejšou kapitolou dokumentu je tretia kapitola, ktorá obsahuje kompletný zoznam všetkých
požiadaviek na systém. Každá požiadavka musí mať svoje označenie (číslo alebo nejaký iný identifikátor),
aby sa na ňu dalo odkazovať z ostatných dokumentov - najmä z návrhu a testovacích scenárov a krátky popis,
typicky v rozsahu 1-3 viet. V tretej kapitole je teda znovu vymenované všetko čo systém bude robiť,
požiadavky sa môžu odkazovať na pojmy, dokumenty a informácie uvedené v predchádzajúcich kapitolách
katalógu požiadaviek.
Pri využití tohto štandardu narážame na dilemu, ak zadávateľ sám nevie sformulovať svoju ucelenú predstavu
a viaceré otázky ostanú nezodpovedané. Vývojári majú na výber: buď ich katalóg požiadaviek bude odpovedať
aj na tieto otázky, alebo zachytí len presne tie požiadavky, ktoré zadávateľ
požadoval. V druhom prípade ale treba vytvoriť ďalší dokument, ktorý plní úlohu kompletného katalógu
požiadaviek. Svojvoľným výberom z alternatív v prípade vynechania dôležitých odpovedí bez toho, aby sme
ich skonfrontovali so zadávateľom, by ľahko mohla nastať situácia, keď by zadávateľ s dodaným výsledkom
nebol spokojný. Úlohou vývojárov, ktorí pripravujú špecifikáciu, je sformulovať aj tie požiadavky na systém,
ktoré zadávateľ zamlčal a skonfrontovať s ním výslednú verziu špecifikácie. V tomto kontexte je užitočné
rozlišovať medzi: zámermi a cieľmi zadávateľa a jeho konkrétnymi požiadavkami. Zatiaľ čo zámery a ciele
len odpovedajú na otázku "Prečo má informačný systém vzniknúť?", konkrétne požiadavky odpovedajú na
otázky "Čo presne má systém robiť?". V niektorých informačných systémoch zadávatelia nevedia určiť
žiadne požiadavky, iba stanoviť svoje zámery a ciele.
Novší štandard 29148 z roku 2011 odpovedá ná tieto otázky a požiadavky rozdeľuje do 3 kategórií, pričom
môžu vzniknúť tri samostatné dokumenty:
- Stakeholder requirements specification (StRS)
- System requirements specification (SyRS)
- Software requirements specification (SRS)
Prvý zachytáva želania používateľov, ktoré dokážu sami sformulovať (user requirements).
Druhá iterácia vychádza z prvej, ale už požidavky rozdeľuje na "Functional requirements"
a pridáva množstvo kategórií pre non-functional requirements, pre zorientovanie sa
uvedieme aspoň ich zoznam: Performance requirements, System interfaces, Human system
integration requirements, Maintainability, Reliability, System modes and states, Physical
requirements, Adaptability requirements, Environmental conditions, System security,
Information management, Policies and regulations, System life cycle sustainment,
Packaging, handling, shipping and transportation.
Tretia iterácia už podrobne popisuje všetky konkrétne požiadavky na takej podrobnej úrovni,
aká je potrebná, aby bolo na základe tejto špecifikácie možné vypracovať jednoznačný návrh systému.
Rozdelenie na tri časti je pekne znázornené na nasledujúcom obrázku, kde vidíme, že
zámery a ciele zadávateľa sa nachádzajú v priestore "problému". Samotný popis čŕt systému
a presných detailných požiadaviek na softvér už patria do priestoru "riešenia", ktoré
na základe potrieb navrhuje a predkladá vývojový tím.
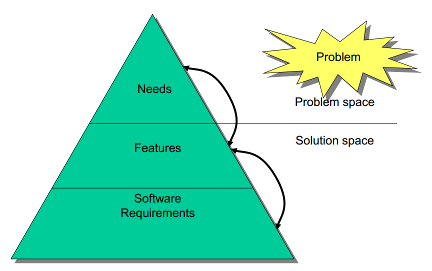
Obr. 13: Problem space vs. solution space
2.2. Fázy procesu tvorby špecifikácie požiadaviek
Povedali sme si čo je predmetom fázy špecifikácie, aká je štruktúra výsledného dokumentu a konečne
sa môžeme zamerať na proces špecifikácie podrobnejšie. Robíme to preto, že fáza špecifikácie
je najdôležitejšou fázou celého vývoja informačného systému, nesmie sa podceniť a treba jej venovať
dostatočnú pozornosť a úsilie. Na všetky chyby, ktoré sa v tejto fáze urobia, neskôr vývojový tím
veľmi draho doplatí.
Hlavným problémom pri tvorbe špecifikácie je, že vývojári nie sú expertmi v oblasti, pre ktorú
systém implementujú (v cieľovej doméne informačného systému) a zadávateľ si nevie predstaviť,
ako bude výsledný systém vyzerať, nepozná technické možnosti a schopnosti vývojového tímu.
Tento problém je fundamentálnou prekážkou toho, aby vznikol systém, ktorý optimálne rieši
potrebu zadávateľa a výsledok je vždy "zlý" a neoptimálny. Nanajvýš je možné usilovať sa
o čo najväčšie priblíženie sa optimálnemu riešeniu a dosiahnuť sa to dá iba dobrou, intenzívnou
a efektívnou komunikáciou medzi zadávateľom a vývojovým tímom.
Vytváranie špecifikácie (Requirements Engineering) má nasledujúce fázy:
- Requirements elicitation, čiže zbieranie požiadaviek
- Requirements analysis and negotiation, analýza a vyjednávanie
- Requirements documentation, zapisovanie výslednej podoby
- Requirements validation, kontrola a schvaľovanie

Obr. 14: Fázy tvorby špecifikácie požiadaviek
Podobne ako pri celom vývoji informačného systému, aj tu treba postupovať iteratívne. Zozbieranie požiadaviek
sa takmer nikdy nepodarí počas jedného stretnutia so zadávateľom. Množstvo informácií je obrovské, je nutné
sa v ňom zorientovať, informácie usporiadať, nájsť priority, hierarchiu a súvislosti. Tento iteratívny proces
vystihuje špirálový model procesu tvorby požiadaviek na nasledujúcom obrázku:
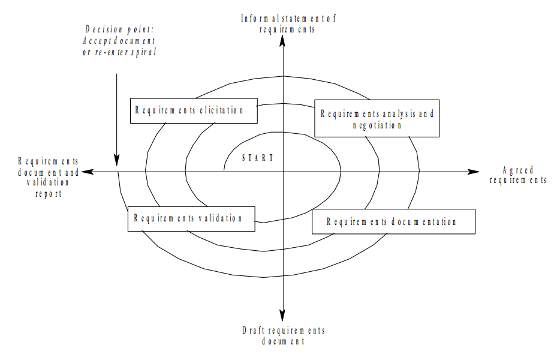
Obr. 15: Špirálový model tvorby požiadaviek
Pri tvorbe požiadaviek narážame na množstvo problémov:
- jednotliví stakeholderi môžu byť do procesu nedostatočne zapojení a málo motivovaní,
neuvedomujú si potrebu dôkladnej komunikácie;
- pri špecifikácii sa neberie ohľad alebo sa príliš často zabúda na skutočný podnikateľský
zámer spoločnosti, pre ktorú sa systém vyvíja a vývojári riešia alebo hľadajú fiktívny problém,
také riešenie zadávateľovi nepomôže;
- proces tvorby požiadaviek nie je dostatočne riadený, je ponechaný na aktivitu jednotlivcov,
ktorí si neuvedomujú svoju zodpovednosť;
- vývojári a prípadne stakeholderi nemajú jasne zadefinovanú zodpovednosť za splnenie
jednotlivých úloh;
- pri komunikácii sa príliš často naráža na problémy a nedorozumenia;
- niektoré informácie sú z vnútorných politických dôvodov v organizácii nedostupné, nemenné, alebo nediskutovateľné (tabu);
- proces nie je dobre naplánovaný v čase (over-long schedules) a výsledná dokumentácia nie je v dostatočnej kvalite.
- požiadavky nie sú navzájom konzistentné (existujú medzi nimi rozpory) a nie sú kompletné;
- robiť v požiadavkách zmeny potom ako sa požiadavky dohodli a sformulovali je nákladné a náročné;
2.2.1 Fáza zbierania požiadaviek
Proces zbierania požiadaviek je schématicky zachytený na nasledujúcom obrázku.

Obr. 16: Špecifikácia: fáza zbierania požiadaviek.
Základným predpokladom pre dobrú komunikáciu je vybudovanie dôvery medzi zadávateľom
a vývojovým tímom. Zadávateľ, ktorý tímu dostatočne nedôveruje nebude schopný formulovať
požiadavky zrozumiteľne a bez predsudkov. Dosiahnutie tejto dôvery nie je jednoduchý proces,
ale je nutnou podmienkou úspešnosti projektu.
Najskôr je potrebné identifikovať ciele zadávateľa, vrátane jeho podnikateľského zámeru
a sformulovať hrubý opis problému, ktorý má informačný systém riešiť, v rámci akých existujúcich
obmedzení.
Pred samotným zbieraním požiadaviek je potrebné získať čo najviac informácií o pozadí informačného
systému do ktorého sa bude nasadzovať, oblasti - doméne ktorú bude riešiť (napríklad ak riešime
informačný systém pre hasičov, tak treba zistiť čo najviac informácií o tom, ako hasiči pracujú)
a o systémoch, ktoré sa v organizácii už používajú
Informácie, ktoré sme v predchádzajúcom kroku získali potrebujeme spracovať a zorganizovať.
Napokon sa zameriame na zbieranie konkrétnych požiadaviek od všetkých zainteresovaných stakeholderov.
Komunikácia so stakeholdermi prebieha formou rozhovorov (interviews). Základné druhy interviews
sú:
zatvorené (closed interview) - keď vývojári majú vopred sformulované otázky, na ktoré potrebujú poznať odpovede
otvorené (open interview) - keď dopredu nie je stanovená presná agenda a diskusia o systéme prebieha voľným spôsobom s otvoreným koncom.
Rozhovory sú úspešné, ak ich účastníci majú schopnosť nie len rozprávať, ale najmä počúvať. Je potrebné pružne reagovať na myšlienkové
pochody druhej strany a vyjadrovať sa a formulovať vety presne a jednoznačne. Aj v prípade otvorených interviews je stakeholderom
vhodné dať oporný bod, z ktorého sa môžu o potrebách na systém rozhovoriť.
Vhodným nástrojom pri zbieraní požiadaviek sú používateľské scenáre. Sú to príbehy, ktoré opisujú príklady interakcie používateľa
so systémom - ako by mohol byť systém používaný. Mali by obsahovať:
- popis stavu systému pred začiatkom scenára
- bežný chod udalostí v scenári
- výnimky voči bežnému chodu udalostí
- informácia o súčasne/paralelne vykonávaných aktivitách
- opis stavu systému na konci scenára
Analyzovaním zapísaných scenárov získavame zoznam konkrétnych jednotlivých požiadaviek na systém.
V niektorých prípadoch a pri rozsiahlejších informačných systémoch môže byť proces zbierania požiadaviek natoľko komplikovaný,
že sa oplatí do organizácie vyslať zástupcu vývojového tímu, ktorý v organizácii pôsobí nejaký čas, zúčastňuje sa bežných činností
a pozoruje ako to vnútri organizácie funguje. To, čo pri rozhovoroch stakeholderi popíšu sa môže líšiť od ich skutočnej dennej praxe.
V spoločenských vedách sa tento odbor nazýva Etnografia a môže sa uplatniť v prenesenej forme aj pri zbieraní požiadaviek na informačný
systém.
Pri zbieraní požiadaviek môže situáciu uľahčiť prototyp, čiže prvotná (nekompletná, zjednodušená) verzia systému.
Používatelia môžu s prototypom experimentovať, zistiť ako si vývojári predstavujú výsledný produkt a odovzdať im hodnotnú
spätnú väzbu ohľadne svojich požiadaviek na systém - už si vedia predstaviť ako bude výsledok vyzerať a tak zrazu presne vedia čo potrebujú.
Takýto prototyp musí byť vyvinutý rýchlo a preto sa často používajú špecializované nástroje a vývojové prostredia na rýchle prototypovanie,
ktoré nespĺňajú všetky vlastnosti (napr. z hľadiska bezpečnosti, stability, prenositeľnosti a pod.), ktoré budú kladené na výsledný systém, ale o to rýchlejšie
umožňujú stakeholderom vidieť základnú kostru alebo používateľské rozhranie aplikácie.
Naviac aj samotní vývojári pri vytvorení prototypu objavia nedostatky (nekonzistentnosť, chýbajúce informácie), ktoré zanechali
v špecifikácii a majú možnosť ich takto včas opraviť.
Rozlišujeme dva základné druhy prototypovania:
- Throw-away prototyping - vytvorený prototyp sa použije na získanie spätnej väzby, potom sa zahodí a systém sa vytvorí
od začiatku - väčšinou v nejakom inom vývojovom prostredí
- Evolutionary prototyping - vytvorený prototyp sa robí už v cieľovom vývojovom prostredí a stáva sa základom, prvou verziou
cieľovej aplikácie, modifikuje sa a (často vo viacerých iteráciách) z neho vzniká výsledný systém. Pozri tiež: evolučný model vývoja IS
v predchádzajúcej kapitole.
Cena, ktorú za luxus prototypovania (platí najmä pre prvý typ) vývojový tím zaplatí, nie je nízka:
- sú potrební experti, ktorí dokážu okrem cieľového prostredia vyvíjať aplikácie aj v prostredí určenom na prototypovanie
- namiesto jedného systému sa vyvíjajú dva: je potrebný dlhší celkový čas, vyššie náklady
- prototyp je nekompletný - niektoré kľúčové vlastnosti sa nemusí podariť do prototypu zaradiť
Ďalšie prístupy k prototypovaniu:
Funkcionalitu výsledného systému môžeme modelovať prototypom bez použitia informačných technológií.
Paper prototyping: skupina ľudí, ktorí sedia za okrúhlym stolom si môžu informácie vymieňať, ukladať na lístočkoch papiera a simulovať
tak procesy, ktoré má vykonávať informačný systém. Takto môžu odhaliť chýbajúce procesy, duplicitu, neefektívnosť a celkovo
demonštrovať funkcionalitu systému.
Wizzard of Oz prototyping: jeden človek nahrádza celý informačný systém a komunikuje s používateľmi, ako keby komunikovali
s informačným systémom, môže si pritom viesť agendu na papieri.
2.2.2 Fáza analýzy a vyjednávania požiadaviek
Po zozbieraní požiadaviek od jednotlivých stakeholderov sa často stáva, že nie sú jednoznačné, sú navzájom v konflikte (nekonzistentnosť),
niektoré informácie chýbajú. Netreba to chápať ako zlyhanie, ale ako prirodzený proces, ktorý je najmä pri viacerých stakeholderoch očakávaný.
Predmetom druhej fázy tvorby špecifikácie je analýza zozbieraných poŽiadaviek a vyjednanie zladenia zistených problémov so stakeholdermi.
Aj na túto fázu si musíme naplánovať dostatok času a zdrojov.

Obr. 17: Špecifikácia: fáza analýzy a vyjednávania požiadaviek
Táto fáza sa prirodzene prelína s fázou zbierania požiadaviek a problémy sa riešia priebežne hneď ako sa objavujú.
Pri kontrole správnosti požiadaviek môžeme použiť nasledujúci zoznam kontrolných bodov (checklist) - každý bod
vyjadruje nejaký problém, ktorý treba opraviť - požiadavku buď odstrániť, alebo preformulovať:
- premature design: predčasný návrh = niektorá požiadavka sa vzťahuje na návrh systému, čiže odpovedá na otázku "Ako sa bude systém vyvíjať?" namiesto toho,
aby riešila otázku "Čo má systém robiť?".
- combined requirements: kombinované požiadavky = nie sú dostatočne atomické - každá požiadavka by mala vyjadrovať iba jednu vec, jednu myšlienku. Ak sa dá rozdeliť na
viacero požiadaviek, ktoré sa dajú naformulovať samostatne, treba to urobiť.
- unnecessary requirements: nepotrebné požiadavky = je požiadavka naozaj potrebná? vedeli by sme sa bez nej zaobísť? Implementácia systému je väčšinou natoľko náročná,
že nám zaberie viac času, ako máme k dispozícií a všetko, čo v systéme nemusí byť, by tam byť ani nemalo.
- use of non-standard hardware: použitie neštandardného hardvéru = ak si vyberáme z dvoch možných hardvérových komponentov - jeden je síce lacnejší, ale dodáva ho
len jedna malá spoločnosť, tak si vždy vyberme radšej štandardizované a dobre dostupné riešenie. Podpora ovládačov pre nový operačný systém po upgrade môže chýbať,
jediný dodávateľ na trhu môže za rok zaniknúť a dodanie nášho systému ďalšiemu klientovi sa znemožní, možnosti integrácie s inými systémami alebo znovupoužitia
komponentov sa znižujú. Platí to nielen pre hardvér - akékoľvek neštandardné komponenty sú potenciálnym rizikom.
- conformance with business goals: súlad s podnikateľským zámerom = naozaj rieši požiadavka niečo, čo spoločnosť pri svojej činnosti potrebuje? ak nie, požiadavka
nie je opodstatnená a treba ju zrušiť.
- requirements ambiguity: nejednoznačnosť = je možné (čo len teoreticky) rozumieť požiadavke viac ako jedným spôsobom? nájsť jej rôzne interpretácie? ak áno,
v každom prípade ju treba upresniť, inak je to časovaná bomba, ktorá s veľkou pravdepodobnosťou vybuchne pri odovzdávaní hotového systému zákazníkovi.
- requirements realism: splniteľnosť = ak požiadavka nie je splniteľná, do katalógu požiadaviek ju neuvádzame.
- requirements testability: otestovateľnosť = ak sa nedá zistiť, či bude požiadavka splnená alebo nie, požiadavku neuvádzame.
Vo fáze anlýzy požiadaviek si všímame interakciu - vzájomné vzťahy a súvislosti medzi jednotlivými požiadavkami. Pre názornosť môžeme
interakcie zobraziť v interakčnej matici.
2.2.3. Fáza validácie požiadaviek
Na rozdiel od fázy analýzy a vyjednávania - keď pracujeme so surovým zoznamom požiadaviek, fáza kontroly / validácie požiadaviek
pracuje s kompletným návrhom výsledného dokumentu potom, ako boli nezrovnalosti odstránené. Kým charakteristickou otázkou procesu
analýzy by malo byť: "Have we got the right requirements?" - získali sme tie pravé požiadavky?, charakteristickou otázkou
fázy validácie by malo byť: "Have we got the requirements right?" - sú už požiadavky v poriadku? Pri kontrole dokumentu
prechádzame jednotlivé požiadavky, pričom môžeme naraziť na nasledovné situácie:
Requirement clarification: požiadavka nie je zapísaná dostatočne zrozumiteľne, treba ju spresniť.
Missing information: stále existujú niektoré informácie, ktoré v dokumente nie sú zachytené, dokument treba aktualizovať dovtedy, kým nebude kompletný.
Requirements conflict: v dokumente sa nachádzajú požiadavky, ktoré sú v konflikte - kontakt so zainteresovanými stakeholdermi musí konflikt vyriešiť.
Nerealistická požiadavka: požiadavka sa využitím dostupných technológií za prítomnosti aktuálnych obmedzení nedá implementovať, treba ju upraviť po konzultácii so stakeholdermi.
Pri kontrole výsledného katalógu požiadaviek si všímame nasledujúce vlastnosti a v prípade nedostatkov uplatníme jednu z uvedených štyroch akcií:
Understandability: zrozumiteľnosť = bude formulácia požiadavky zrozumiteľná pre všetkých čitateľov dokumentu?
Redundancy: duplicita = je niektorá informácia redundantná? t.j. dá sa odstrániť bez toho, aby to malo na obsah celkového dokumentu nejaký dopad?
Completeness: úplnosť = sú uvedené všetky informácie a všetky požiadavky?
Ambiguity: nejednoznačnosť = sú všetky pojmy v požiadavkách jednoznačne zadefinované? môže sa stať, že niektorí čitatelia ich pochopia inak?
Consistency: vzájomný súlad = existujú dve rôzne požiadavky, ktoré nie sú celkom v súlade a skrývajú nejaké rozpory?
Organization: usporiadanosť = je dokument usporiadaný a členený zmysluplne? sú súvisiace požiadavky rozumne zoskupené?
Conformance to standards: súlad so štandardmi = sú všetky požiadavky a dokument v súlade so štandardami? ak nie, sú odlišnosti od štandardu dostatočne zdôvodnené?
Traceability: vystopovateľnosť = je pôvod každej požiadavky jasný a dostatočne zdokumentovaný? ak by malo dôjsť k zmenám požiadaviek, vieme
zistiť od ktorého stakeholdera, z ktorého interview, alebo kvôli ktorému obmedzeniu alebo štandardu sa daná požiadavka v dokumente vyskytla?
3. Diagramy UML
Pri špecifikovaní a navrhovaní informačných systémov si vývojári pomáhajú schémami, obrázkami, diagramami. Obrázky slúžia jednak
ako vhodné médium - podklad diskusie vývojárov a jednak pre čitateľov dokumentov, aby sa oveľa rýchlejšie a prehľadnejšie zorientovali
v informáciách ktoré dokument sprostredkúva. Naviac, obrázky svojou grafickou reprezentáciou umožňujú vytvoriť model - čiže
abstraktné zjednodušenie systému, na ktorom je možné pozorovať, analyzovať, skúmať a navrhovať závislosti, štruktúru, správanie,
tok informácií, tok riadenia, stavy, scenáre udalostí a ďalšie aspekty. Do 90-tych rokov existovalo niekoľko rôznych notácií
pomocou ktorých sa modely informačných systémov zakresľovali. Pri spájaní týchto úsilí do modelu vývoja Rational Unified Process opísaného
v predchádzajúcej kapitole vznikol jednotný grafický jazyk na zakresľovanie diagramov používaných pri špecifikácii a návrhu informačných
systémov: jazyk UML (Unified modeling language). Jednotnosť notácie umožňuje vývojárom pochopiť význam diagramov vytvorených inými
vývojármi. Situácia keď jeden vývojár číta dokument vytvorený iným vývojárom je veľmi bežná:
- špecifikáciu, návrh a implementáciu často vytvárajú rôzni ľudia
- systém, ktorý navrhol jeden tím neskôr dostane na starosti iný tím, ktorý má doplniť novú funkcionalitu
- vývojársky tím obsahuje viacero členov s rozdelenými úlohami a zodpovednosťou
- vývojový tím integruje do svojho systému komponent, ktorý vyvinul iný tím.
Je zrejmé, že ak by každý používal iný spôsob zakresľovania diagramov, dochádzalo by k zbytočným nedorozumeniam a chybám.
Aktívne ovládanie jazyka UML preto patrí k základným poznatkom, ktoré si má osvojiť každý informatik.
Hoci jazyk UML a jednotlivé diagramy nebudeme študovať do maximálnej hĺbky, uvedieme účel a základné pravidlá najbežnejších UML diagramov.
Do roku 2004 sa používala verzia UML 1, odvtedy postupne vznikali jednotlivé aktualizácie verzie UML 2. Tieto verzie sa líšia
v grafickej reprezentácii a svojich možnostiach, preto pri kreslení diagramov je dôležité skontrolovať, že používate nástroj,
ktorý podporuje aktuálnu verziu jazyka.
3.0. Entitno-relačný diagram (ERD)
Entitno-relačný diagram nepatrí do jazyka UML, lebo ten sa zameriava predovšetkým na objektový návrh, zatiaľ čo ERD je všeobecnejší.
Napriek tomu je ERD veľmi bežný a často využívaný. Znázorňuje vzťahy (relácie) medzi entitami. Entita je niečo, čo sa dá nazvať
podstatným menom. Diagram sa typicky používa na modelovanie priestoru domény pre ktorú sa informačný systém vyvíja (napr. mliekárenský
podnik, ak vyvíjame informačný systém pre výrobu mliečnych výrobkov). Entity sa zakresľujú do obdĺžnikov. Vzťahy medzi entitami (relácie)
sú v kosoštvorcoch a sú prepojené so všetkými entitami, ktoré do daného vzťahu vstupujú. Entity aj relácie môžu mať svoje atribúty, ktoré
sa do diagramu môžu zakresliť ako ovály spojené so svojou entitou/reláciou úsečkou. Medzi entitami môže byť vzťah generalizácie/špecializácie
vyjadrený trojuholníkom. Vzťah môže byť pomenovaný. Vzťahy medzi entitami môžu mať vyjadrenú násobnosť (koľkokrát sa daná entita daného
vzťahu zúčastňuje).

Obr. 18: Príklad entitno-relačného diagramu.
Na obrázku je zobrazená doména autoservisu. V servise pracujú dva druhy zamestnancov: mechanik a obchodník, každý je určený atribútmi
meno a číslo. Mechanik vykonáva opravy, čo je vyjadrené reláciou Mechanic - Does - RepairJob, pričom oprava má svoje atribúty: popis,
číslo opravy, cena za materiál a cena za prácu. Medzi entitami RepairJob (oprava) a Car (automobil) je takisto vzťah n:1 - jeden konkrétny
automobil mohol podliehať viacerým opravám. Vzťah nákup automobilu (Buys) sa týka troch entít: Obchodník nakupuje daný automobil od nejakého
klienta.
Diagram dátového modelu, čiže tabuľky, ich atribúty a vzťahy medzi tabuľkami sa niekedy tiež označuje ako entitno-relačný diagram.
Jeho účel je odlišný - dokumentuje podrobnú štruktúru databázy, čiže perzistentnej vrstvy informačného systému - je povinnou súčasťou
návrhu každého systému, ktorý do externej pamäte ukladá dáta. Naopak klasický ERD sa skôr využije pri špecifikácii na modelovanie
vzťahov v doméne, pre ktorú sa systém špecifikuje.
3.1. Diagram používateľských scenárov (UML Use-case diagram)
Diagram modeluje činnosti, ktoré informačný systém pri interakcii s používateľmi poskytuje.
Diagram sa používa najmä v skorších fázach vývoja, pri špecifikácii a analýze. Slúži na pomenovanie základných hrubých
používateľských scenárov a rozličných rolí, v ktorých používatelia vystupujú pri interakcii so systémom. Definuje ktoré roly sa
zúčastňujú ktorých scenárov.
Jednotlivé činnosti (scenáre, prípady použitia) sú zakreslené ako ovály, sú vyjadrené slovne v nedokonavom tvare.
Nemali by to byť jednorázové akcie, ale nejaké postupy, ktoré sa skladajú z viacerých krokov. Používateľské roly sa nazývajú
aktori a sú zakreslené ako schématické postavičky. Jedna fyzická osoba môže vystupovať aj v rozličných roliach. Aktorom nemusí
byť živá bytosť, môže to byť aj fyzická entita, ktorá v systéme hrá nejakú aktívnu rolu. Od aktorov vedú úsečky k oválom, ktoré
reprezentujú scenáre, ktorých sa daný aktor zúčastňuje. V prípade potreby je možné scenáre rozkresliť podrobnejšie: pomocou
relácie extends alebo pomocou relácie uses (niekedy označovanej includes). Extends znamená, že príslušný nadscenár môže zahŕňať
príslušnú špecializáciu, pričom spravidla sa prejaví len jedna z možných špecializácií. Relácia uses/includes znamená, že
príslušný nadscenár vždy zahŕňa aj všetky zobrazené prepojené podscenáre. V prípade aktorov môžeme využiť reláciu generalizácie
(dedičnosť) na vyjadrenie vzťahu medzi dvomi aktormi - všeobecnejším a jeho konkrétnejšou špecializáciou. Znamená to, že konkrétnejší
aktor sa môže zúčastniť všetkých scenárov ako aktor všeobecnejší, ale zúčastňuje sa nejakých špecifických scenárov naviac.

Obr. 19: príklad Use-case diagramu.
Diagram používateľských scenárov nikdy nemôže byť použitý len tak, bez podrobnejšieho vysvetľujúceho textu. Používateľské role,
aj uvedené scenáre treba podrobne konkretizovať. Use-case diagram slúži najmä ako sumarizujúci pohľad a prehľad všetkých (alebo
zvolenej skupiny) používateľských scenárov.
3.2. Sekvenčný diagram
Sekvenčný diagram sa spravidla týka jedného konkrétneho scenára. Môže byť využitý pri podrobnom analyzovaní používateľského scenára
zachyteného v use-case diagrame na hrubo-zrnnej úrovni, alebo na vyšpecifikovanie následnosti komunikácie objektov (čomu väčšinou
zodpovedá volanie metód príslušných objektov) na podrobnej a nízkej úrovni. Sekvenčný diagram sa zvlášť hodí na zakreslenie nejakého
komunikačného protokolu.
Diagram sa zakresľuje ako skupina zvislých prerušovaných čiar, pričom každá z nich zodpovedá jednej entite a v hornej časti diagramu
je popísaná. Zvislé čiary zodpovedajú plynutiu času - ten plynie v celom diagrame synchronizovane a rovnako, zhora smerom nadol.
Scenár začína tak, že jedna entita vyšle do druhej entity správu, znázornenú vodorovnou šípkou. To spôsobí vytvorenie kontextu
spracovania správy na danej cieľovej entite - je zobrazený úzkym zvislým obdĺžnikom a trvá dovtedy, kým požiadavka nie je celá spracovaná.
Entita typicky oslovuje ostatné entity v diagrame zaslaním ďalších správ, ktoré nasledujú neskôr v čase (čiže nižšie). Tie opäť
vedú k vytvoreniu kontextu na spracovanie danej správy, znovu oslovujú ďalšie entity atď. Správy sú vždy konkretizované textom umiestneným
nad šípkou. Po spracovaní požiadavky entita odpovedá návratovou správou (bodkovaná čiara) a presne v tom okamihu jej kontext zaniká.
Na jednej entite môže vzniknúť aj nový kontext, pokiaľ predchádzajúci kontext trvá. Jazyk UML dovoľuje v sekvenčnom diagrame špecifikovať
časti, ktoré sa nevykonajú vždy (optional, znázornené rámčekom s označením opt v rohu), alebo viaceré alternatívne časti, ktoré sa vykonajú
podmienene, v závislosti od splnenia stanoveného predikátu (alt). Podobne je možné zakresliť cykly (loop), prípadne súčasne vykonávané aktivity
(par).
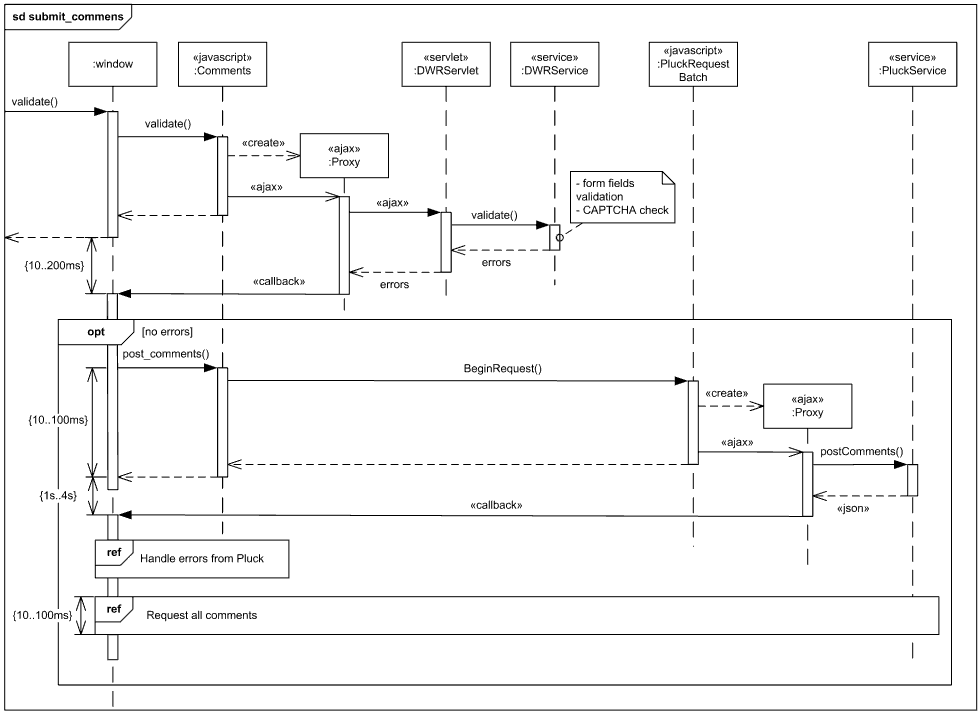
Obr. 20: Príklad sekvenčného diagramu. Iný pekný príklad, v ktorom vidno vnorené kontexty:
tracemodeler.com
3.3. Diagram komunikácie
Diagram vyjadruje rovnakú informáciu ako sekvenčný diagram, ale celkom iným spôsobom: Entity sú zobrazené ako obdĺžniky a správy, ktoré
si entity navzájom posielajú sú vyjadrené ako šípky nad spojnicami medzi entitami. Postupnosť komunikácie je určená číslami pred správami,
napr. správa 1 Show Map je prvá, za ňou nasleduje správa 1.1 Get Map, potom 1.2 Get Map, atď. neskôr správa 2. Find Route, 2.1 Get Route, atď.
Význam tohto diagramu spočíva v tom, že na rozdiel od sekvenčného vidíme statické rozloženie entít na ploche, vidíme ktoré spolu navzájom
nekomunikujú a ktoré áno a aká intenzívna je táto komunikácia.

Obr. 21: Príklad komunikačného diagramu.
3.4. Stavový diagram
Stavový diagram je veľmi špecifický, ale dôležitý nástroj modelovania správania sa nejakej entity. Každý stavový diagram musí mať
jasne určenú entitu, ktorej stavy zobrazuje. Stav entity je pasívny, nie je to akcia. Stav trvá nejakú dobu, entita v ňom zotrváva
po určitú dobu, kým nenastane nejaká udalosť, alebo sa nevykoná nejaká akcia. Následkom udalosti/akcie sa entita dostáva do ďalšieho
stavu. Niektorý zo stavov je počiatočný, niektoré stavy môžu byť označené ako koncové. Stavy sa zakresľujú ako ovály a orientované
šípky znázorňujú dvojice stavov, medzi ktorými existuje prechod. Stavové prechody sú popísané udalosťami/akciami, ktoré vedú ku stavovému
prechodu. Nasledovaním stavových prechodov môže dochádzať k cyklom. Ľubovoľný stav diagramu môže byť prepojený prechodom s ľubovoľným
iným. Treba si uvedomiť rozdiel medzi stavovým diagramom a diagramom činností. Zatiaľ čo stavový diagram zobrazuje pasívne stavy,
diagram činností (activity diagram, niekedy nazývaný aj flow-chart, po slovensky vývojový diagram) zobrazuje postupnosť akcií, ktoré
spolu tvoria nejaký postup/algoritmus. Zameriavajú sa teda na celkom odlišný uhol pohľadu na určitý proces. Niektoré stavy môžu mať
vnútornú štruktúru rozobratú na podstavy: takýto stav má vnútri svoj iniciálny stav a stavové prechody vychádzajúce von automaticky
opúšťajú príslušný nadstav. Stavové prechody nadstavu sa môžu realizovať z ľubovoľného podstavu.

Obr. 22: Príklad stavového diagramu pre entitu Kurz. Na obrázku vidíme využitie makro-stavov, ktoré vnútri tvorí samostatný stavový diagram. Stavové prechody vnútri makro-stavu nie sú na obrázku kvôli priestoru popísané, ale pri dôslednom modelovaní by popísané mali byť. Každý stavový prechod v stavovom diagrame má byť popísaný udalosťou/akciou/časovým horizontom.
3.5. Diagram činností (vývojový diagram/flow chart)
Diagram činností - hoci používa graficky podobnú notáciu ako stavový diagram vyjadruje zakreslenie postupnosti krokov s možnými
cyklami, vetvením a paralelným spracovaním. V obdĺžnikoch sú zakreslené jednotlivé príkazy/atomické činnosti, sú prepojené
orientovanými úsečkami, ktoré znázorňujú tok riadenia (beh programu). Do kosoštvorcov sa zapisujú podmienky vetvenia a na hrany,
ktoré z nich vychádzajú sa zapisujú prípady na základe ktorých dochádza k vetveniu toku výpočtu.

Obr. 23: Príklad diagramu činností (activity diagram).
3.6. Diagram komponentov
Diagram komponentov ponúka statický pohľad na štruktúru a architektúru systému podľa nejakého konkrétneho členenia.
Diagram tvoria pomenované obdĺžniky s ikonou komponentu v rohu zodpovedajúce veľkým celkom, ktoré sú prirodzene odčleniteľné
od zvyšku aplikácie. Sú prepojené s ostatnými komponentami s ktorými komunikujú - túto komunikáciu s pravidla definujú
verejne prístupné rozhrania daného komponentu - znázornené uzavretým krúžkom, resp. otvoreným polkruhom (poskytovateľ, vs. klient)
pripojeným krátkou úsečkou k zodpovedajúcemu komponentu. Komponentový diagram môže znázorňovať aj hierarchickú štruktúru komponentov
- keď sú menšie komponenty zapúzdrené do väčšieho, v tom prípade v diagrame môžu byť použité "delegation connectory", ktoré smerujú
vonkajšie rozhrania na rozhrania vnútorných komponentov.

Obr. 24: Príklad komponentného diagramu (component diagram).
3.7. Diagram tried (UML Class diagram)
Diagram tried je jeden z najpoužívanejších diagramov UML. Znázorňuje triedy použité v systéme, alebo jeho časti, prípadne ich metódy
a polia a vzťahy medzi triedami. Medzi triedami môžu byť tri základné vzťahy: generalizácia, agregácia a asociácia. Triedy, medzi
ktorými je vzťah sú prepojené úsečkou so zodpovedajúcim symbolom.
Prvý z nich vyjadruje vzťah dedičnosti - jedna trieda je špecializáciou inej - dedí z nej všetky vlastnosti a pridáva nejaké svoje
špecifické črty. Generalizácia sa znázorňuje trojuholníčkom na strane všeobecnejšej triedy.
Agregácia označuje vzťah celok-časť. Na strane celku sa zakresľuje kosoštvorec. V prípade, že je prázdny, ide o bežnú agregáciu,
ak je plný, ide o kompozíciu. Kompozícia je silnejšia agregácia, kde celok a časť nemôžu samostatne existovať a dávajú zmysel len ako celok.
Asociácia je všeobecný vzťah medzi dvoma triedami, nevyjadruje sa žiadnym symbolom a stanovuje, že jedna trieda nejakým spôsobom využíva
služby druhej. Špecifickým typom asociácie je dependencia, ktorá sa definuje takto: medzi triedou A a triedou B je dependencia, ak zmena
funkcionality v triede B môže vynútiť úpravy v triede A.

Obr. 25: Príklad triedneho diagramu (class diagram).
Špeciálnym prípadom triedneho diagramu je package diagram, ktorý namiesto tried zobrazuje celé balíky tried. Pri triednom diagrame
si treba uvedomiť, že to, čo zobrazuje sú typy údajov, nie údaje samotné. Diagram teda len znázorňuje aké sú vzťahy medzi jednotlivými
typmi dát, ktoré v aplikácii používame.
3.8 Diagram objektov (UML Object diagram)
Naopak, diagram objektov - hoci sa syntakticky veľmi podobá triednemu diagramu nezobrazuje typy, ale konkrétne údaje, tak ako sa vyskytujú
v pamäti počas behu aplikácie. Ak má automobil štyri kolesá, tak v objektovom diagrame budú zobrazené štyri obdĺžniky označené príslušnými
názvami objektov reprezentujúcich jednotlivé kolesá automobilu.
Obr. 26: Príklad objektového diagramu (object diagram).
3.9. Diagram rozmiestnenia elementov (UML Deployment diagram)
Deployment diagram zobrazuje rozloženie komponentov na jednotlivých výpočtových uzloch počas reálnej prevádzky systému.
Je v ňom zobrazené aké rôzne výpočtové uzly (fyzické počítače) systém bude využívať, aká bude ich rola (klient, databázový server a pod.),
aká bude topológia ich vzájomného prepojenia, aké komunikačné protokoly sa budú na komunikáciu medzi komponentami používať.

Obr. 27: Príklady deployment diagramov.
3.10. Diagram dátových tokov (data-flow diagram)
Na záver uveďme diagram dátových tokov, určený na modelovanie toku informácií medzi procesmi a externými a internými dátovými úložiskami.
Zobrazuje konkrétne kúsky informácií a procesy, ktoré si informácie medzi sebou vymieňajú. Externé úložiská (resp. vstupy a výstupy dát
do modelovaného systému) sú označené obdĺžnikmi,
interné úložiská dát sú pomenované medzi dvoma vodorovnými čiarami, konkrétne informácie (typy tečúcich údajov) sú popísané na šípkach,
ktoré znázorňujú zdroj a cieľ toku informácií. Procesy sú označené kruhmi.
Tento diagram síce nie je súčasťou UML, je omnoho starší, ale umožňuje modelovať tok
údajov medzi procesmi jedinečným spôsobom, takže sa stále bežne používa.
Obr. 28: Príklad data flow diagramu.
3.11. Príklad
Využitie UML diagramov si ukážeme na malom príklade. Naším cieľom bude navrhnúť systém pre elektronické voľby. Niečo podobné už funguje v Estónsku viac ako 10 rokov.
Elektronické voľby (a zvlášť cez Internet) nikdy nemôžu byť natoľko bezpečné a spoľahlivé ako ručné sčítavanie hlasov, kde si do volebnej komisie každá strana môže menovať svojich členov, ktorí dohliadajú na regulérnosť volieb.
Za regulérnosťou sa skrýva viacero požiadaviek:
- voľby by mali byť anonymné: 1) nemal by existovať žiaden spôsob, ako by niekto mohol zistiť, ako občan volil a zároveň 2) nemal by existovať žiaden spôsob, ako by občan mohol niekomu tretiemu dokázať koho volil.
- hlasy by sa nemali dať nijakým spôsobom sfalšovať - t.j. ani zmeniť ani pridať za tých voličov, ktorí sa rozhodli nevoliť
- každý volič by mal mať právo voliť najviac raz
Tieto požiadavky vôbec nie je jednoduché zabezpečiť, viaceré štúdie skôr naznačujú, že je to nemožné. Zvlášť, ak by sa občanom dovolilo voliť zo svojho počítača cez Internet.
Predpokladajme však, že sa riziká podarí znížiť na prijateľnú úroveň. Elektronické voľby potom umožnia:
- ušetriť obrovské množstvo papiera
- ušetriť obrovské množstvo práce
- získať výsledky prakticky okamžite po uzatvorení volieb
- vytvoriť omnoho demokratickejšie formáty volieb - s možnosťou vyznačiť poradie kandidátov
- automaticky organizovať viackolové voľby len jedným hlasovaním
- spresniť priebeh volieb v prípade odstupujúcich kandidátov
- a veľa ďalších výhod
V tejto časti použijeme jazyk UML na modelovanie častí informačného systému zabezpečujúceho elektronické voľby.
3.11.1. Use-case diagram
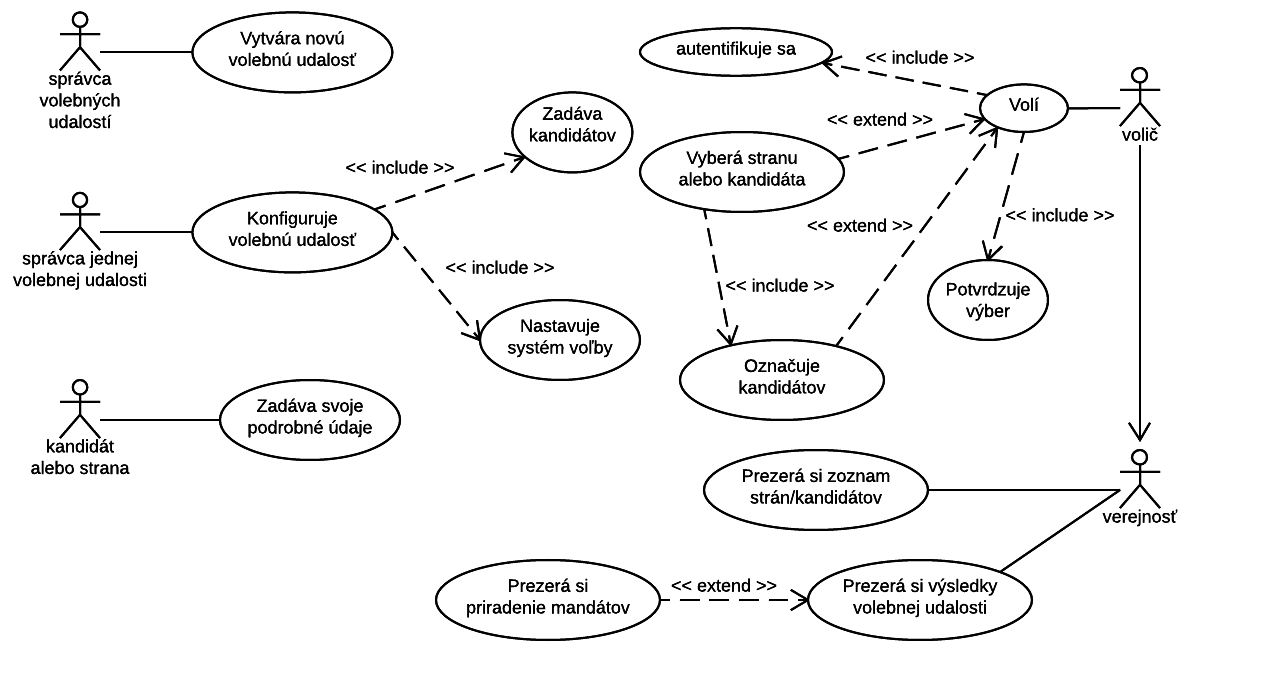
Obr. 29: Use-case diagram pre IS elektronické voľby.
Modelovanie volebného informačného systému začíname zobrazením všetkých podstatných funkcií, ktoré
systém plní v use-case diagrame (diagram používateľských scenárov) a uvedomením si pre ktoré rozličné
používateľské roly je každá takáto funkcionalita dostupná.
Každej použivateľskej roli zodpovedá jedna grafická postavička.
Ak je medzi niektorými rolami vzťah generalizácie, v diagrame sú spojené šípkou, smerujúcou
od špecifickejšej roly ku všeobecnejšej. V našom prípade má používateľská rola
volič k dispozícii
funkcionalitu, ktorá je pre neho špecifická, napr. počas voľby označuje kandidátov, ale zároveň má
k dispozícii všetku funkcionalitu, ktorá je dostupná pre všeobecnejšiu rolu
verejnosť, keďže
je jej špecializáciou.
Každý ovál zodpovedá nejakej ucelenej funkcionalite (use case), ktorej dosahovanie sa realizuje vykonaním
určitého scenára - postupnosti krokov, ktoré nie sú v tomto diagrame viditeľné, ale môžu byť zobrazené
v sekvenčnom diagrame. V niektorých prípadoch však môžeme
podstatné časti príslušného scenára zdôrazniť aj tu - najmä, ak im zodpovedá nejaká samostatne ucelená podfunkcionalita.
V tomto príklade
správca jednej volebnej udalosti, ktorý konfiguruje nejakú volebnú udalosť,
musí nastaviť systém voľby a potom pozadávať kandidátov (príp. strany). Preto je v diagrame šípka smerujúca
od use-case
Konfiguruje volebnú udalosť ku use-case
Nastavuje systém voľby
i k use-case
Zadáva kandidátov, obe označené stereotypom
<< include >>.
Podľa typu voľby môže volič buď len vyberať jednu stranu, resp. kandidáta (napr. v prezidentských voľbách),
alebo v inom type volieb môže krúžkovať kandidátov. Preto je používateľský scenár
volí "rozšírený"
voliteľne o podscenár
vyberá stranu alebo kandidáta, alebo podscenár
označuje kandidátov.
Oba sú teda špecializáciou všeobecnejšieho scenára
volí a tento vzťah generalizácie/špecializácie,
resp. realizácie/doplnkového voliteľného rozšírenia je vyjadrený prototypom
<< extend >>. V oboch prípadoch sa volič musí autentifikovať a na záver potvrdiť svoj
volebný výber a preto sú tieto ďalšie dva podscenáre označené prototypom
<< include >>. V niektorých
prípadoch volič nielen vyberá stranu, ale okrem toho môže svoje preferenčné hlasy určiť zakrúžkovaním kandidátov.
Preto jeden z podscenárov je zároveň potenciálne súčasťou druhého podscenára.
Na tomto diagrame je dôležité všimnúť si, že funkcionalita popísaná v ováloch aa vyjadruje nedokonavým vidom slovies:
vytvára, konfiguruje, zadáva, volí a pod. Nie je vhodné použiť ani neurčitok (voliť, vytvoriť, konfigurovať),
ani rozkazovací spôsob (vytvor, konfiguruj), ani žiadnu inú formu (vytvorenie, voľba, konfigurácia...).
Ešte raz si všimnime šípky medzi scenármi A -> B: v prípade doplnkového/voliteľne pridaného podscenára ide šípka
smerom od špecializácie ku všeobecnejšiemu use-case (<< extend >>) - otázka:
je A rozšírením B?,
zatiaľ čo v prípade zahrnutia podscenára
v komplexnejšom scenári (<< include >>) smeruje šípka od komplexnejšieho k čiastkovému,
jednoduchšiemu, zahrnutému scenáru - otázka:
je B súčasťou A?
3.11.2. Stavový diagram
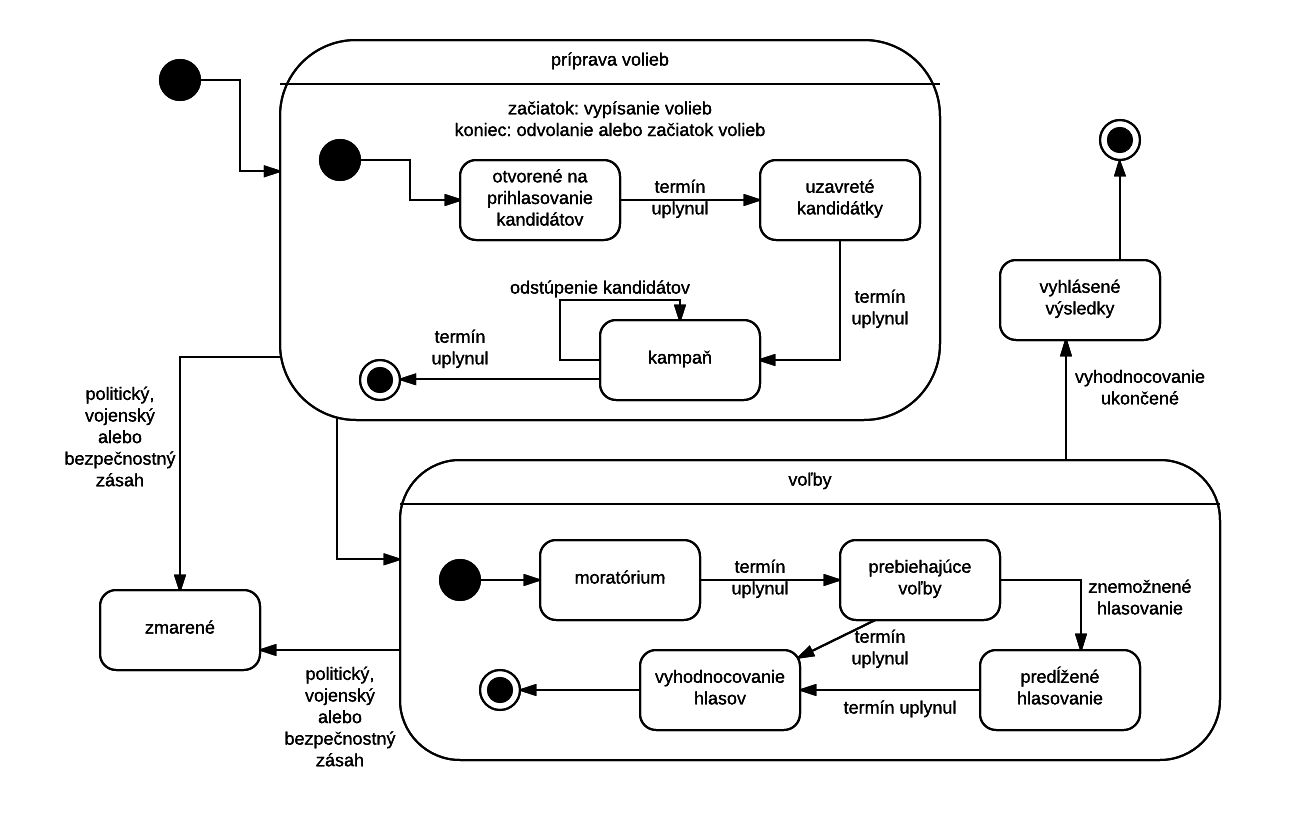
Obr. 30: Stavový diagram pre IS elektronické voľby.
Informačný systém nikdy nebude plniť svoj účel správne, ak jeho tvorcovia nepochopili životný cyklus entít,
ktoré v systéme hrajú kľúčové úlohy. Každá entita prechádza cez určité stavy a svoj stav mení v závislosti
na svojej interakcii s okolitým svetom - spravidla v okamihu nejakej uskutočnenej udalosti alebo po uplynutí
určitej stanovenej doby. Stavový diagram UML znázorňuje pasívny prechod nejakej entity medzi jej stavmi a udalosti,
ktoré zmenu stavu takejto entity spôsobujú. Zvolenou modelovanou entitou môže byť ľubovoľná entita z domény
problému informačného systému. Tento typ diagramu je možné použiť, ak za entitu vezmeme samotný informačný
systém, prípadne jeho používateľské rozhranie, ale v tomto príklade a aj v príkladoch, ktoré nás počas
tímového projektu a písomných testov budú zaujímať, budú modelované stavy inej entity. V tomto prípade ide o entitu
voľby.
Každý stav entity je vyjadrený nejakým oválom, každý ovál vyjadruje nejaký stav entity. Každý prechod do ďalšieho
stavu (šípka medzi dvoma oválmi) by mal byť popísaný textom - udalosťou, pri ktorej k prechodu medzi stavmi dochádza.
Výsledkom je potenciálne cyklický orientovaný graf. Modelovať stavy enity sa dá na rôznej hrubozrnnosti, čím môžeme
dostať diagram na markoskopickej úrovni, hoci každý - alebo len niektoré - z jeho stavov obsahujú podrobnejší
diagram. Do stavového diagramu entita vstupuje cez počiatočný stav (čierny kruh) a vystupuje väčšinou cez koncový
stav (kruh v kružnici).
3.11.3. Sekvenčný diagram
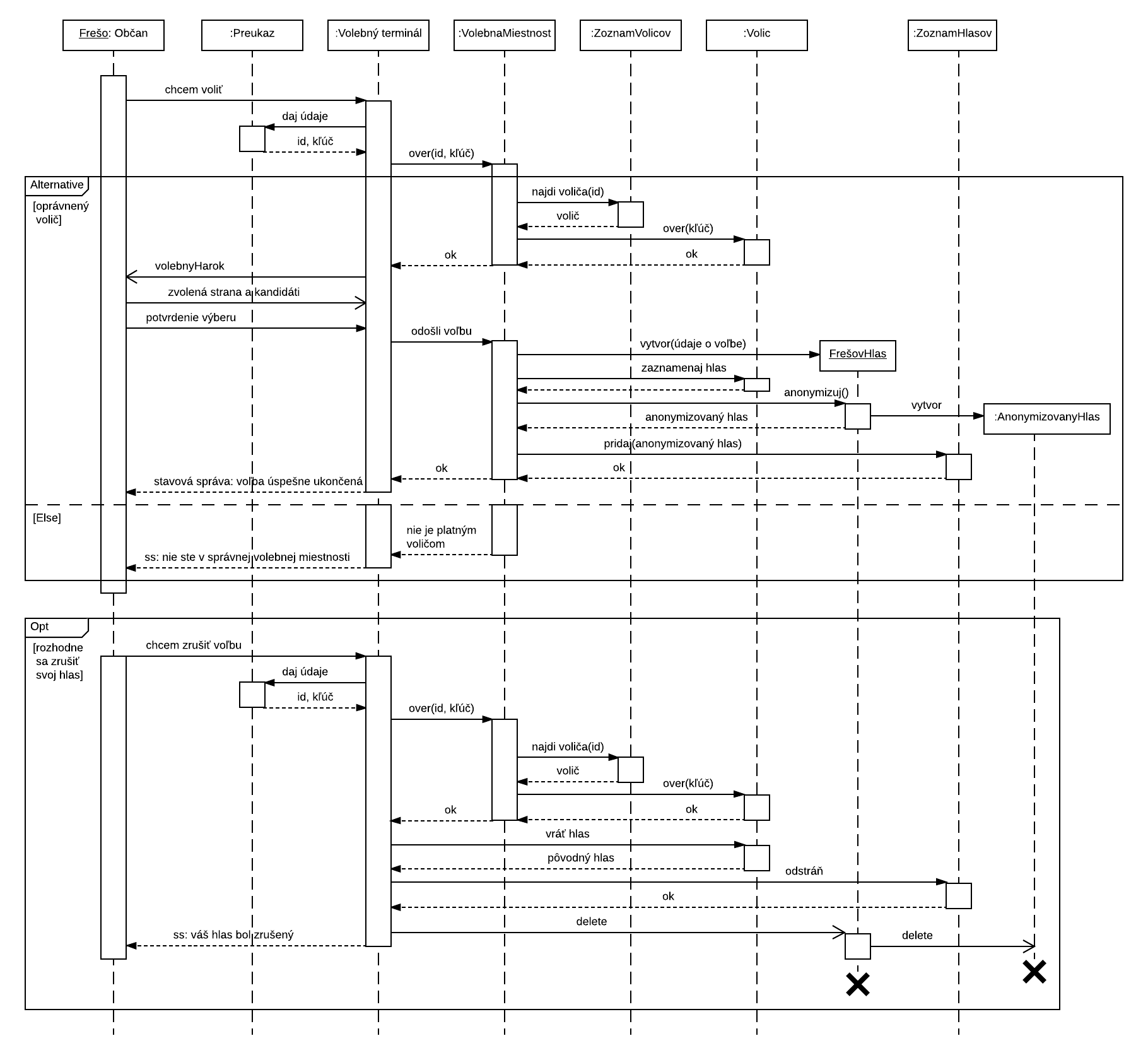
Obr. 31: Sekvenčný diagram opisujúcu scenár "volí" s doplnkovou možnosťou zrušenia hlasu pre IS elektronické voľby.
V sekvenčnom diagrame plynie čas zhora nadol. Na x-ovej osi sú zobrazené jednotlivé entity. V prípade podrobného
návrhu entity zodpovedajú objektom nejakých tried, pri menej podrobnom diagrame entity zodpovedajú celým komponentom.
Môže ísť aj o entity z domény problému informačného systému (napr. archív, predseda volebnej komisie, štatistický urad a pod.), ak modelujeme časový priebeh nejakého scenára v reálnom
svete a interakciu medzi skutočnými entitami. Vodorovné šípky (spravidla nejdú šikmo - necestujú v čase! - pokiaľ
nechceme zvlášť znázorniť, že doručenie správy nejaký čas trvá - v tom prípade môže byť šípka aj šikmo smerom nadol)
znázorňujú komunikáciu medzi entitami v zmysle: jedna entita posiela druhej entite nejakú správu uvedenú v texte nad šípkou. V prípade objektov ide spravidla o volanie metódy, kde môžeme uviesť aj argumenty volanej metódy. Tento diagram je veľmi vhodný na pochopenie
postupnosti a poradia správ pri komunikácii počas nejakého konkrétneho používateľského scenára (často sekvenčný diagram
zodpovedá jednému oválu/scenáru z use-case diagramu). Zvislé prerušované čiary zodpovedajú životnosti (časovej platnosti)
jednotlivých entít. Ak nejaká entita vzniká uprostred príslušného scenára, tak sa aj jej hlavička (obdĺžnik s názvom entity)
uvedie až v príslušnom čase. V tomto prípade vznikla entita FrešovHlas, (podobne zodpovedajúci objekt triedy AnonymizovanyHlas) až keď ho objekt triedy VolebnaMiestnost vytvoril a preto je hlavička tejto entity uvedená v strede diagramu. Ak nejaká entita naopak v nejakom čase prestane existovať, tak je jej zvislá čiara ukončená
hrubým šikmým krížom. V našom prípade bol objekt evidujúci hlas zrušený, lebo o to požiadal sám volič.
Pomocou vetvenia (rámček s alt/alternative v ľavom hornom rohu) môžeme vyjadriť alternatívne cesty
scenára podľa platnosti nejakej podmienky, ktorá je tiež vyjadrená pod slovíčkom
alt v hranatých zátvorkách.
Podobne, rámčeky s popisom
opt,
resp.
loop vyjadrujú časti scenára, ktoré sa nie vždy, resp. opakovane vykonajú.
Pre úplnosť: existujú aj rámčeky
par a
critical, ktoré označujú časti scenára,
ktoré sa vykonávajú paralelne, resp. takú podčasť, ktorá obsahuje kritický úsek scenára,
ktorý sa môže vykonávať naraz iba jeden raz (v jednom výpočtovom vlákne - critical region),
pre ešte väčšiu úplnosť pozri
uml-diagrams.org.
Na zvislých osiach sú umiestnené
prázdne zvislo-úzke obdĺžniky, ktoré vyjadrujú dobu, po ktorú je nejaká správa entitou spracovávaná. Mali by začínať
presne v okamihu, keď správa príde a väčšinou končia, keď sa odpovedná správa vracia naspäť entite, ktorá poslala správu,
čo príslušný obdĺžnik vytvorila. Entita môže počas spracovávania správy zavolať svoju vlastnú metódu
(pošle správu sama sebe) - v tom prípade spracovávanie pôvodnej správy stále pokračuje ďalej, ale vytvorí
sa ďalší - prekrývajúci obdĺžnik zodpovedajúci časovému intervalu spracovania vnorenej správy. Notácia
spracovávania správ predpokladá, že po poslaní správy inej entite prechádza kontext spracovania
(mohli by sme povedať "výpočtové vlákno") do príslušnej entity, až kým správu nespracuje a neodpovie na ňu.
V programovaní to zodpovedá volaniu metódy - výpočtové vlákno so zavolaním metódy odíde spracovávať zavolanú metódu.
Naopak, ak má ísť o asynchrónnu správu poslanú medzi dvoma entitami, ktoré obe ďalej pokračujú
(každá má "svoje výpočtové vlákno"),
tak sa šípka môže nakresliť s polovičným profilom, alebo bez výplne. V záhlaví entít sa môžu vyskytnúť anonymné inštancie
nejakých tried (napr.
:VolebnaMiestnost), alebo priamo nejaké špecifické inštancie určitých tried (napr.
Frešo:Občan).
Samotná inštancia (objekt) zvykne byť podčiarknutá. Pre úplnosť: ak je entitou zúčastňujúcou sa komunikácie
objekt v nejakej používateľskej roli, tak namiesto obdĺžnika možno použiť piktogram používateľskej roly (postavičku),
prípadne ikony i názvy iných stereotypov - pozri
tracemodeler.com.
Diagram na obrázku vyššie znázorňuje priebeh používateľského scenára
volí s doplnkovou funkcionalitou umožnenia
zrušiť už hodený hlas (ak voľby stále prebiehajú). Predtým ako občan vyplní svoju voľbu na volebnom termináli, sa
na základe jeho autentifikácie preukazom overuje, či je platným voličom v danej volebnej miestnosti (táto verzia
systému neprakticky predpokladá, že volič má voliť iba vo svojom volebnom obvode, hoci aj toto obmedzenie tradičných volieb
je jedným z tých, ktoré by bolo možné elektronickými voľbami ľahko prekonať).
3.11.4. Triedny diagram
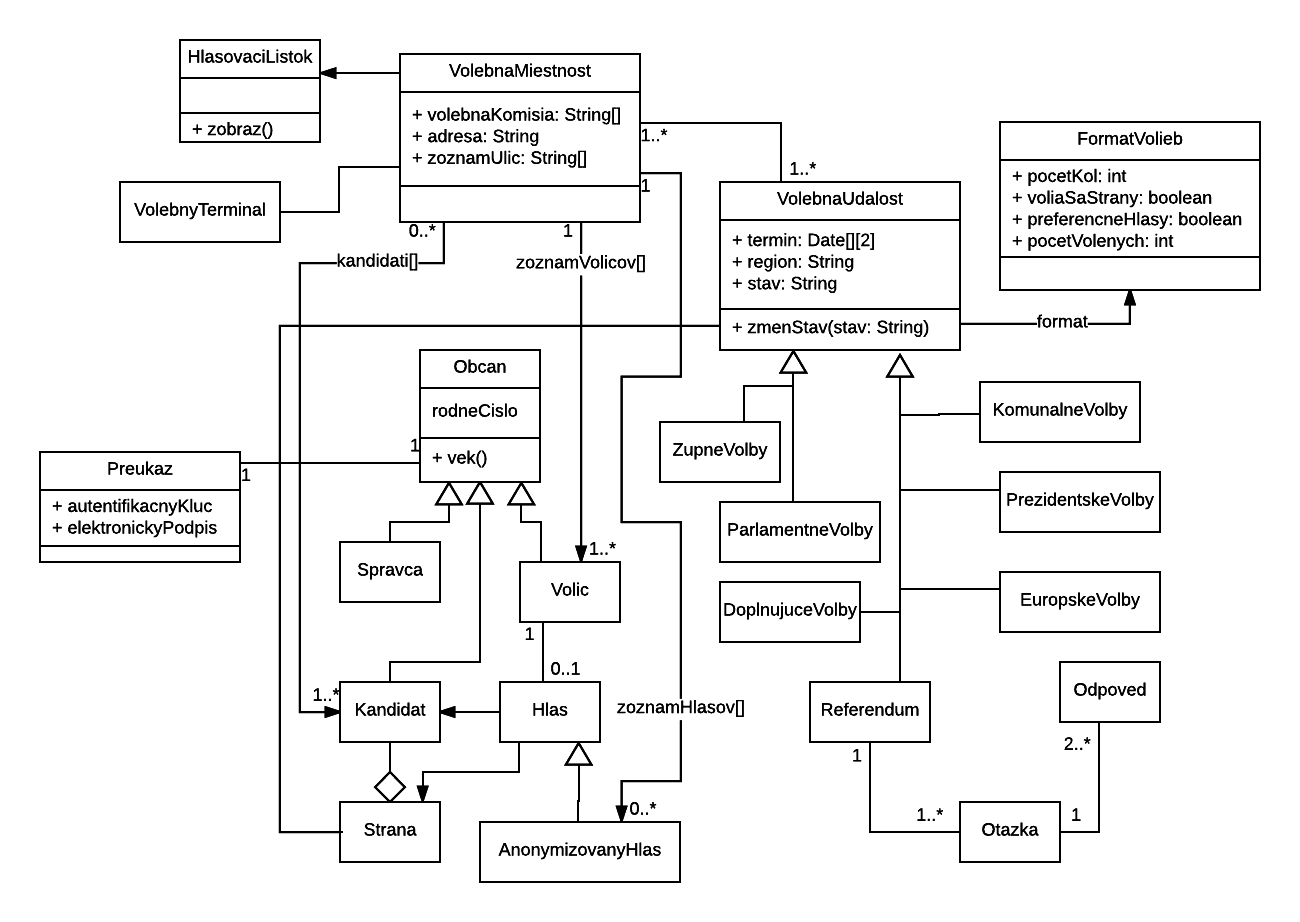
Obr. 32: Triedny diagram vybranej časti IS elektronické voľby ktorá rieši voľbu vo volebnej miestnosti.
Triedny diagram zobrazuje podrobnosti tried a vzťahy medzi triedami - čiže medzi typmi dátových údajov,
ktoré aplikácia používa. Pod podrobnosťami máme na mysli zoznam metód (a ich argumentov a návratových hodnôt), ktoré chceme znázorniť a zoznam jej atribútov (= premenných). Obe môžu byť dekorované viditeľnosťou: + = public, - = private, # - protected, prípadne ~ - package. Ak pre myšlienku, ktorú diagramom chceme vyjadriť, zoznam metód a atribútov nie je podstatný, trieda môže byť vyjadrená aj obyčajným obdĺžnikom obsahujúcim len názov triedy. Medzi triedami rozlišujeme tri základné typy vzťahov (relácie):
generalizácia - zodpovedá vzťahu nadtrieda-podtrieda a vyjadruje sa prázdnym trojuholníčkom na strane nadtriedy
agregácia - zodpovedá vzťahu celok-časť a vyjadruje sa kosoštvorcom na strane celku. Ak je kosoštvorec plný,
ide o silnejšiu verziu agregácie - kompozíciu, ktorá značí, že časť je neoddeliteľnou súčasťou celku a nemá samostatne
reálny význam. Vzťah celok-časť sa prakticky často realizuje tak, že v triede, ktorá je celkom, sa vyskytuje odkaz
na príslušnú časť vo forme atribútu. Názov tohto atribútu sa potom zvykne písať ako textový popis čiary vyjadrujúcej
agregáciu, namiesto toho, aby sa uviedol priamo v zozname atribútov triedy.
asociácia - zodpovedá nejakému inému vzťahu medzi triedami - typicky keď metóda alebo atribút jednej triedy využíva (ako argument, alebo návratovú hodnotu) objekty druhej triedy. Táto relácia môže byť orientovaná (orientovaná šípka) alebo nie (čiara nie je ukončená šípkami).
Všetky tri druhy vzťahov sú tzv. dependenciou, čiže závislosťou medzi triedami, ktorú je možné znázorniť aj priamo pomocou prerušovanej čiary a ktorá je vždy orientovaná: dependencia A -> B označuje, že zmena triedy B môže vyvolať nutnosť úprav v triede A. Na vzťahoch medzi triedami je možné zobraziť násobnosť vzťahu (1 na 1, 1 na mnoho, mnoho na mnoho, prípadne počty aj presnejšie špecifikovať). Napríklad na obrázku vyššie je vidno, že každému voličovi (1) zodpovedá jeden alebo žiaden hlas (0..1).
Očakáva sa, že v triednych diagramoch, ktoré na tomto predmete vytvoríte, použijete všetky tri uvedené základné typy vzťahov medzi triedami aj ich násobnosti.
3.11.5. Deployment diagram

Obr. 33: Deployment diagram pre IS elektronické voľby.
Deployment diagram vyjadruje prevádzkový pohľad na systém - na akých hardvérových zariadeniach
bude systém v prevádzke nainštalovaný, ako budú prepojené komunikačnými spojeniami a aké komunikačné
protokoly sa na týchto prepojeniach použijú. Na hardvérových zariadeniach (sú označené 3D krabicami)
a stereotypom (<< device >>) sú prevádzkované jednotlivé komponenty systému (obdĺžniky s ikonkou
komponentu v rohu), ktoré tam môžu byť prevádzkované v rámci nejakého výpočtového prostredia - napr.
aplikačného servra Tomcat. Výpočtové prostredie je označené stereotypom << execution environment >>
a zobrazené 3D krabicou vnútri svojho hardvérového zariadenia, pričom komponenty sa umiestňujú priamo
do tohto prostredia - ak je, pravda, na zariadení vyjadrené. Iné obmedzenia (napr. OS = Linux) príslušného
výpočtového uzla sú vyjadrené v záhlaví v zložených zátvorkách. Pokiaľ chceme zobraziť aj jednotlivé
artefakty, ktoré sa na príslušné zariadenie inštalujú (súbory, balíčky, aplikácie), môžeme ich vyjadriť
obdĺžnikom so stereotypom << artifact >> a napr. ikonou súboru. Pri prevádzke tieto artefakty
po spustení tvoria nejaký koponent, čomu zodpovedá stereotyp << manifest >>, príklad je uvedený na obrázku.
3.11.6. Activity diagram
Pre zaujímavosť a na odlíšenie od stavového diagramu sa pozrime ešte na príklad Activity diagramu,
ktorý je UML verziou tradičných vývojových diagramov (flow-chart). UML Activity diagram používa rovnaký
grafický jazyk ako stavový diagram, ale zobrazuje niečo iné: zatiaľ čo stavový diagram zobrazuje
pasívne stavy nejakej entity a akcie/udalosti, ktoré vedú k zmenám stavu, sú uvedené pri šípkach medzi
dvojicami stavov, v activity diagrame je zobrazený nejaký postup pozostávajúci z krokov (akcií), ktoré
sú uvedené v ováloch. Šípky znázorňujú iba postupnosť/následnosť jednotlivých akcií. Vetvenie na rôzne
alternatívy sa značí pomocou kosoštvorca, s jedným vstupným a minimálne dvoma výstupnými prepojeniami.
Nasledujúci príklad zobrazuje postupnosť krokov voliča pri interakcii s volebným terminálom.

Obr. 34: Activity diagram interakcie voliča s terminálom pre IS elektronické voľby.
4. Návrh
Návrh je najnáročnejšou fázou tvorby informačného systému. V praxi sa mu často nevenuje dostatočná pozornosť, čo vedie k neoptimálnym systémom
s krátkou životnosťou a množstvom chýb. Základ návrhu tvorí architektúra systému. Pri návrhu sledujeme základný princíp vysokej súdržnosti a
nízkej fragmentovanosti. Môžeme sa inšpirovať stavebníctvom. Na prvom obrázku je systém s vysokou súdržnosťou a malým počtom vzájomných
spojov jednotlivých komponentov. Na druhom obrázku je opačný prípad. Prvý variant je z hľadiska návrhu oveľa vhodnejší ako druhý, pretože ak by
z nejakého dôvodu došlo k modifikácii, ktorá by viedla k posunutiu stredového upínacieho bodu, tak by sa museli zmeniť všetky segmenty, ktoré
sú v ňom uchytené.

Obr. 35: Základný princíp pri navrhovaní: efektívna architektúra.
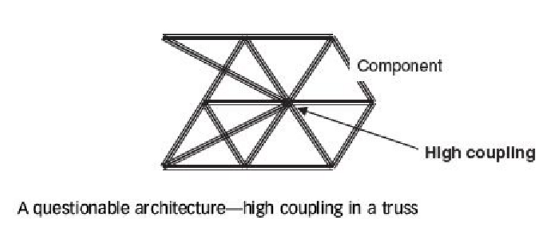
Obr. 36: Základný princíp pri navrhovaní: neefektívna architektúra.
4.1. Architektonické pohľady na systém
Architektúra softvérového systému je základná kostra systému na ktorú sa upínajú všetky komponenty.
Môžeme ju študovať z hľadiska statického - opisuje softvérové, hardvérové a dátové prvky a vzťahy medzi nimi,
alebo dynamického - opisuje tok informácií a procesov. Rozlišujeme niekoľko základných architektonických
pohľadov na systém (mohli by sme povedať pri pohľade na systém si nasadíme rozličné okuliare, ktoré umožňujú vidieť rozličné aspekty):
- Funkčný pohľad - opisuje funkčné elementy systému, ich zodpovednosti, rozhrania a interakcie.
- Informačný pohľad - opisuje spôsob ako systém ukladá, spravuje a distribuuje informácie.
- Konkurenčný pohľad - identifikuje elementy systému, ktoré sa vykonávajú paralelne a súťažia o rovnaké zdroje,
spolu so spôsobom riadenia tohto konkurenčného správania.
- Vývojový pohľad - opisuje elementy (moduly), do ktorých je členený kód programu a vzájomné väzby elementov.
- Pohľad zavádzania systému - opisuje prostredie do ktorého bude systém zavedený, vrátane závislostí, ktoré má systém na tomto prostredí.
- Prevádzkový pohľad - opisuje ako sa bude systém prevádzkovať, administrovať, udržiavať v prevádzkovom prostredí.
4.2. Ciele pri tvorbe návrhu
Napriek tomu, že sa môžu zdať prirodzené, je dobré uvedomiť si, aké ciele by sme pri tvorbe návrhu mali sledovať:
- Sufficiency: dostatočnosť = návrh je dostatočný vtedy, keď pokrýva všetky požiadavky uvedené v špecifikácii.
- Understandability: zrozumiteľnosť = návrh je zrozumiteľný, keď mu rozumejú členovia vývojové tímu, nie je určený pre zadávateľa, pretože obsahuje technický jazyk a iba by ho poplietol.
- Modularity: modularita = systém je rozdelený do častí (modulov), pričom architektúra je pripravená na jednoduché pridávanie nových alebo výmenu existujúcich modulov bez toho, aby sme ostatné moduly museli akokoľvek meniť.
- Cohesion: súdržnosť = časti systému, ktoré prirodzene patria spolu a vytvárajú celky držia pohromade.
- Coupling: spájanie = systém jednoznačne definuje rozhrania, minimalizuje ich počet aj rozsah.
- Robustness: robustnosť = systém je odolný voči neočakávaným situáciám, ktoré nie sú pokryté v špecifikácii - nedá sa ľahko zhodiť.
- Flexibility: flexibilita = zmena požiadaviek nespôsobí priveľa práce.
- Reusability: znovupoužiteľnosť = systém je navrhnutý tak, že sú jeho časti použiteľné aj v iných systémoch, resp. systém využíva časti z iných systémov.
- Information hiding: skrývanie informácií = systém dôsledne implementuje skrývanie informácií medzi modulmi: v prípade návrhu nejde ani tak o bezpečnosť dát pred nepovolaným prístupom, ale o kvalitu návrhu - súkromné údaje jednotlivých modulov majú ostať neprístupné preto, aby sa zbytočne nezvyšoval počet závislostí medzi modulmi, čo by viedlo k príliš náročnej modifikácii.
- Efficiency: úspornosť = systém je navrhnutý tak, že využíva všetky zdroje efektívne, nielen pracuje rýchlo a stačí mu malá pamäť, ale nepoužíva veľa papiera v tlačiarni, nemá veľkú spotrebu energií, nevyžaduje častú obsluhu, nespôsobuje upchatie komunikačných kanálov a podobne.
- Reliability: spoľahlivosť = systém robí to, čo je uvedené v špecifikácii a robí to spoľahlivo, bez výpadkov.
4.3. Štruktúra dokumentu Software Design Description
Výsledkom úsilia fázy návrhu informačného systému by mal byť dokument, podľa ktorého sa systém dá priamo naprogramovať. Návrh by mal byť
dostatočne konkrétny na to, aby doviedol dve skupiny, ktoré by postupovali nezávisle podľa jedného návrhu, k veľmi podobnému výsledku.
Vychádzajúc zo štandardu IEEE 1016, ktorý od prvej verzie z roku 1987 bol dvakrát upravovaný (1998, 2009), návrh softvéru by mohol mať
nasledujúcu štruktúru - opäť ide len o odporúčanie, ktoré sa prispôsobuje príslušnému projektu:
1. Introduction
1.1 Purpose
1.2 Scope
1.3 Definitions, acronyms, and abreviations
2. References
3. Decomposition description
3.1 Module decomposition
3.1.1. Module 1 description
3.1.2. Module 2 description
3.2 Concurrent process decomposition
3.2.1. Process 1 description
3.2.2. Process 2 description
3.3 Data decomposition
3.3.1 Data entry 1 description
3.3.2 Data entry 2 description
4. Dependency description
4.1 Intermodule dependencies
4.2 Interprocess dependencies
4.3 Data dependencies
5. Interface description
5.1 Module interface
5.1.1 Module 1 description
5.1.2 Module 2 description
5.2 Process interface
5.2.1 Process 1 description
5.2.2 Process 2 description
6. Detailed design
6.1 Module detailed design
6.1.1 Module 1 detail
6.2.2 Module 2 detail
6.2 Data detailed design
6.2.1 Data entity 1 detail
6.2.2 Data entity 2 detail
4.4. Objektový návrh
4.4.1. Základné princípy OOP
Objektovo-orientované programovanie sa do centra softvérového priemyslu dostalo koncom 80-tych a začiatkom 90-tych rokov, keď sa ukazovalo,
že dáta sú pri návrhu softvérového diela a pri jeho životnom cykle oveľa podstatnejšie a stabilnejšie ako funkcionalita, ktorá sa nad týmito
dátami vykonáva. Namiesto dovtedy zaužívanej dekompozície systému (rozdelenie na menšie podčasti) na základe funkcionality sa dôležitejšou
stávala dekompozícia na základe dát. Dáta sa prirodzene formovali do štruktúr - zväčša popisujúcich atribúty nejakej entity => objektov.
Prvým masovo rozšíreným OOP jazykom bol stále pomerne nízkoúrovňový jazyk C++, ktorý neriešil vážny a fundamentálny problém: rozsiahlejšie
projekty narážali na nejasne definované kompetencie pri správe pamäti. Ak si jednotlivé komponenty programu (myslíme metódy) preposielajú
(najmä rozsiahlejšie) údaje uložené v objektoch vytvorených v dynamickej pamäti, nie je celkom jasné - a jazyk to nijak nedefinuje, či adresát
má na starosti aj odstránenie objektu z pamäti. Ak je ten istý objekt rozoslaný viacerým adresátom, žiaden z nich nemôže zodpovedať za jeho
odstránenie z pamäti - niekto iný ten objekt možno ešte potrebuje. Ak sa má o jeho uvoľnenie z pamäti postarať
odosieľateľ, ten tiež nemá kontrolu nad tým, kedy adresáti už objekt nepotrebujú a možno odosielateľ už dávno neexistuje, kým adresáti s objektom
pracujú naďalej. Odpoveďou na tento problém je všetko stále kopírovať,
čo je ale veľmi zlá stratégia efektívneho narábania s pamäťou i s procesorovým časom. Vzniká tak paradox, že na jednej strane nízkoúrovňový
a veľmi efektívny jazyk, akým je jazyk C, bol rozšírený o chybne koncipovanú správu dynamickej pamäte objektov v C++ a hoci nedávny štandard
vo verzii C++11 sa situáciu za cenu neelegantného skomplikovania jazyka snažil zachrániť, podstatne kvalitnejšie riešenie zaviedli jazyky
rodiny Java v 90-tych rokoch a vytlačili jazyk C++ z role priemyselného štandardu. Spustiteľný program v Jave už nie je len skompilovaný
kód (binárny strojový kód ako v prípade C++, bytecode v prípade jazyka Java - ale stále je to len skompilovaný kód), ale potrebuje špeciálne
výpočtové prostredie - virtuálny stroj (virtual machine), ktorý má okrem iného na starosti správu dynamickej pamäte.
Virtuálny stroj sám a ku každému jednému objektu eviduje, či je objekt ešte niektorým komponentom využívaný a keď nie je, automaticky ho
z pamäti odstráni (garbage collection) bez toho, aby sa o to programátor musel starať.
V tom prípade sa nič nemusí kopírovať, všetky komponenty zdieľajú tú istú kópiu objektu a všetky objekty sa preposieľajú odkazom (referenciou).
A ak niekde náhodou naozaj potrebujeme kópiu, tak si objekt explicitne vyklonujeme (metóda clone()).
Tento významný posun znamenal odstránenie jedného
z najproblematickejších miest, kde môžu vznikať programátorské chyby, ktoré sa veľmi ťažko hľadajú a opravujú. Preto sa dnes v praxi siaha
po jazyku C++ iba v prípadoch, keď ide o kritické systémy, kde záleží na presnom načasovaní udalostí, resp. maximálnom výkone (renderovanie grafiky,
riadenie hardvéru, vedecké výpočty) a kde automatická správa pamäte (garbage collection) vedie k neočakávanej variabilite v odozve systému,
ktorú si nemožno dovoliť. Predsa len interpretovanie platformovo nezávislého javovského bajtkódu nemôže byť rovnako efektívne, ako beh programu
preloženého priamo do strojového kódu procesora.
V tých prípadoch (keď Java a spol. nevyhovuje) však väčšinou vystačíme s elegantnejším, lepšie čitateľným, jednoduchším a zrozumiteľnejším jazykom C.
V poslednom desaťročí sa aj jazyky rodiny Java dostávajú postupne do úzadia, najmä kvôli zmene platformy - väčšina informačných systémov sa presúva
na web, kde Java nie je kľúčovým hráčom, aj keď aplikačné servre založené na technológii Java EE
sú silnou, populárnou a stále sa rozvíjajúcou technológiou. Otázna je aj situácia na mobilných zariadeniach, kde sa síce používa Java na platforme Android, ale kód beží na neštandardnom virtuálnom stroji, iné platformy (iOS) našli tiež iné alternatívy ako Java.
Vráťme sa k OOP. Čiže dáta sa v OOP dostali v informačných systémoch viac do pozornosti. Objekty (po slovensky
predmet) oveľa viac začali zodpovedať
novej úlohe, ktorú informačné systémy začínali plniť: počítače už nemali len "počítať" - vykonávať pre človeka náročné výpočty, ale informačné systémy
odrážali a nahrádzali situácie z reálneho sveta - čiže informačné systémy sa stávali
modelmi reality a objekt sa osvedčil ako základný stavebný
prvok modelov reality zloženej z entít a vzťahov medzi entitami. Nad dátami reprezentovanými objektami sa vykonávajú operácie (nejaké čiastkové výpočty)
a ukázalo sa, že tieto operácie je dobré umiestniť čo najbližšie k dátam - priamo do objektov. Tak sa z objektu stáva nielen súbor údajov o nejakej
entite (jeho atribútov), ale aj súbor operácií - nejakých elementárnych alebo aj zložitejších funkcií, ktoré vieme na entite realizovať. Napríklad,
ak je v objekte Student uložené rodné číslo študenta, tento objekt môže obsahovať operáciu (metódu) vek(), ktorá z rodného čísla vypočíta aktuálny vek študenta.
Tento koncept - dátový typ s množinou definovaných operácií na týchto dátach s jasne určeným významom - sa často označuje ako abstraktný dátový typ (ADT). Typickým
príkladom je typ zásobník, ku ktorému sú definované operácie vlož prvok na vrch zásobníka (push), vyber prvok z vrchu zásobníka (pop) a zisti, či zásobník je prázdny (isEmpty).
V systéme sa typicky nachádza viacero objektov, ktoré majú rovnakú štruktúru. Napríklad, v akademickom informačnom systéme tvoria základné evidované
údaje o každom študentovi samostatný objekt, každému študentovi zodpovedá jeden objekt v systéme. Všetky takéto objekty majú rovnakú štruktúru
a tá je predpísaná definíciou typu objektu, čiže jeho triedou. Vidíme, že trieda (class) je typom štruktúrovaných údajov a objekt (object)
je hodnotou - jedným konkrétnym prípadom (inštanciou triedy). Čiže napr. medzi triedou Student a nejakým konkrétnym objektom tejto triedy (ktorý obsahuje
napr. základné údaje o študentke Alexandre) je vzťah rovnakého druhu ako napr. medzi typom premennej "int" a hodnotou 7: trieda vs. objekt je ako typ vs. hodnota.
Pripomeňme však ešte raz, že k objektu a triede patria aj operácie, ktoré príslušná trieda definuje. Operácie patria aj triede aj objektu: trieda ich zadefinuje
a nad konkrétnymi objektami operácie pracujú.
OOP sa v skratke často definuje ako kombinácia troch hlavných vlastností jazyka:
OOP = inheritance + polymorphism + encapsulation, čiže dedičnosť, polymorfizmus a zapúzdrenie údajov.
Kľúčovú rolu hrá aj
abstrakcia, čo označuje princíp hľadania spoločných vlastností rozličných vecí vytváraním ich zovšeobecnení. Zovšeobecnenie je abstrakciou definujúcou
spoločné vlastnosti všetkých pôvodných vecí. Vzniká tým hierarchia konceptov, všeobecný koncept s vybranými spoločnými vlastnosťami (generalization) a sada rôznych vecí, kde
každá k spoločným vlastnostiam pridáva niečo svoje špecifické (specialization).
Napríklad, v grafickom editore používateľ vytvára kružnice a elipsy, úsečky, body, obdĺžniky, mnohouholníky a podobne, ale všetky majú spoločné niektoré vlastnosti a operácie:
majú polohu v dokumente určenú súradnicami (
x, y), vieme ich posunúť o vektor [
dx, dy] operáciou
move(dx, dy), vedia sa do dokumentu na svojej pozícii
nakresliť (
draw(Document d)). Tieto spoločné vlastnosti a operácie vyberieme do abstraktnejšieho pojmu
útvar. V OOP jazyku sa uvedená situácia modeluje tak, že
jednotlivým druhom útvarov zodpovedajú triedy (napr. trieda
Kruznica, trieda
Bod, atď.), ktoré sú podtriedami nadtriedy
Útvar.
Tiež hovoríme, že podtriedy sú od nadtriedy odvodené, resp. ich rozširujú (kľúčové slovo
extends v jazyku Java).
Inheritance čiže dedičnosť označuje
schopnosť jazyka OOP definovať takéto abstrakcie. Podtriedy dedia všetky vlastnosti nadtried, sú niečím špecifické - niečím sa od svojich nadtried odlišujú. Vo väčšine jazykov
má každá trieda najviac jednu nadtriedu, ale nadtrieda môže mať viacero podtried. Ak sa nejaký typ entity hodí do viac ako jednej abstrakcie, väčšina OOP jazykov dovoľuje vytvoriť
tzv. interfejsy, kde jedna špecifická trieda môže spĺňať charakteristiku viacerých abstraktnejších pojmov - každý definovaný svojím interfejsom. Napríklad trieda Človek, určená na
reprezentáciu ľudských bytostí a ich vlastností (atribúty farba očí, farba vlasov, telesná hmotnosť, veľkosť chodidla a pod.) môže byť odvodená od abstraktnejšieho konceptu
Cicavec (ktorý napríklad definuje atribút priemerná doba kojenia), ale zároveň v inej (mohli by sme povedať ortogonálnej) hierarchii je odvodený od konceptu Suchozemský živočích,
kde môžu byť atribúty ako dĺžka kroku, alebo počet nôh. Jazyk C++ umožňuje aj takúto viacnásobnú dedičnosť, hoci väčšina iných jazykov len na úrovni interfejsov, kde (napr. v jazyku Java)
nie je možné definovať atribúty, ale len operácie. Interfejs je len predpisom rozhrania (zoznamu operácií), ktoré musí trieda, ktorá tento interfejs implementuje, definovať.
Nie je však problém do interfejsu zaradiť gettery a settery (operácie, ktoré vrátia hodnoty príslušných atribútov) a tým sa s uvedeným príkladom viacnásobnej dedičnosti vysporiadať.
V príklade sú uvedené len gettery:
public interface Cicavec
{
/** @returns priemerna doba kojenia v tyzdnoch */
public int primernaDobaKojenia();
}
public interface SuchozemskyZivocich
{
/** @returns dlzka kroku v milimetroch */
public int dlzkaKroku();
/** @returns pocet noh zivocicha */
public int pocetNoh();
}
public class Clovek implements Cicavec, SuchozemskyZivocich
{
public java.awt.Color farbaOci() { ... }
public java.awt.Color farbaVlasov() { ... }
...
public int primernaDobaKojenia() { ... }
public int dlzkaKroku() { ... }
public int pocetNoh() { ... }
}
Vráťme sa k príkladu grafického editora s útvarmi a všimnime si, že vo všeobecnej triede
Útvar je definovaná operácia
draw(Document d), ktorú prekrýva každá
zo špecifických podtried. Za jedným menom (draw) sa teda skrývajú rozličné tvary: poly-morph =>
polymorphism. Ak si vytvoríme pole objektov triedy Útvar, do tohto poľa nám
princípy dedičnosti OOP dovoľujú priradiť aj ľubovoľnú podtriedu triedy Útvar, pretože každá podtrieda triedy Útvar má všetko, čo útvar má mať a preto ju môžeme použiť v ľubovoľnej
situácii, kde sa útvar vyžaduje. Iterujme cez toto pole a na každej položke poľa vykonajme operáciu draw(). Program v OOP jazyku automaticky zvolí tú správnu metódu draw()
z tej triedy, akej je príslušná položka poľa.
Utvar utvary[] = new Utvar[10];
Document d;
...
u[0] = new Kruznica(100, 100, 5);
u[1] = new Obdlznik(200, 200, 7, 4);
...
for (Utvar u : utvary)
u.draw(d); // na tomto mieste sa volaju rozne metody draw => polymorfizmus
Položme si ešte tieto otázky: Ako bude kompilátor vedieť, ktorú zo všetkých metód draw() má
na danom riadku programu zavolať? Ako sa takýto pekný polymorfizmus v OOP jazykoch v skutočnosti dosahuje?
Kompilátor bežne prekladá volanie funkcie, procedúry, metódy priamo do strojovej inštrukcie procesora "CALL adresa". Adresa nasledujúcej inštrukcie sa odloží na zásobník,
riadenie programu z tohto miesta prejde na inštrukciu na udanej adrese - tam sa nachádza kód príslušnej funkcie a po dosiahnutí inštrukcie "RET" (return) sa zo zásobníka
vyberie adresa nasledujúcej inštrukcie, aby program pokračoval na tom mieste, odkiaľ bola daná funkcia zavolaná.
Toto v prípade polymorfizmu nie je možné, lebo z daného miesta programu je potrebné zavolať vždy inú metódu draw(). Preto musí byť v každom objekte uložená aj jeho trieda (čiže jeho typ)
a kompilátor pri preklade na danom riadku programu vygeneruje kód, ktorý najskôr zistí, akého typu je objekt v premennej u. Potom sa pozrie do tabuľky virtuálnych metód -
inými slovami - zistí si adresu tej správnej metódy draw() - a tú zavolá.
Napokon základná vlastnosť OOP jazykov
encapsulation - zapúzdrenie údajov vyjadruje možnosť skryť lokálnu implementáciu týkajúcu sa objektu pred objektami iných tried.
Metódy iných tried sa k atribútom označeným príznakom "private" nedostanú. Objekty by navonok mali zverejniť (príznakom "public") čo najmenej svojich atribútov (ideálne žiadne)
a čo najmenej operácií (len tie, ktoré sú nevyhnutné). Vďaka tomu v systéme bude vznikať menej vzájomných implementačných závislostí medzi triedami. Nielen že bude kód čitateľnejší,
ale bude najmä ľahšie modifikovateľný - v prípade zmien, ktoré sa netýkajú zverejneného rozhrania stačí urobiť zmeny v rámci jednej triedy.
Hoci väčšina systémov sa aj dnes navrhuje v objektovom návrhu, nadšenie z OOP už čiastočne opadlo. Významným faktorom je znovu prechod systémov na web. Jeden typický http request
na webový server zväčša znamená len rýchle a efektívne spustenie krátkeho skriptu. Klientský kód sa zasa píše v jazyku Javascript, ktorý kvôli svojej netypovosti zaužívané princípy OOP opustil.
Nie je to faktor jediný. Prvotné nadšenie z OOP opadlo kvôli nepraktickosti objektových frameworkov s priveľmi zväzujúcimi hierarchiami tried. Ako uvidíme čoskoro pri nárhovom
vzore dekorátor, rozšírenie triedy o nejakú funkcionalitu je možné robiť nielen prostredníctvom relácie generalizácie (dedičnosť), ale aj pomocou relácie agregácie (vzťah celok - časť).
4.4.2. Objektová normalizácia
Z databázových systémov poznáme normálne formy pre dátový model pre relačné
databázy. Podobne existujú normálne normy pre objektové dátové modely,
ktoré sa od relačných databáz odlišujú najmä tým, že umožňujú v pamäti
ľahšie reprezentovať kolekcie dát, t.j. situácia je o niečo jednoduchšia.
Podrobný návrh komponentov by sme vždy mali skontrolovať, či spĺňa
všetky tri normálne formy.
1ONF: Trieda je v prvej objektovej normálnej forme, ak jej objekty
neobsahujú skupinu opakujúcich sa atribútov. Takéto atribúty je
potrebné vyčleniť do objektov novej triedy a skupinu opakujúcich sa
atribútov nahradiť jednou väzbou na kolekciu objektov
tejto novej triedy. Schéma je v 1ONF, ak všetky triedy sú v 1ONF.

Obr. 37: 1ONF - pôvodný model pred normalizáciou obsahuje názov a cenu
o troch rôznych produktoch v oboch triedach.
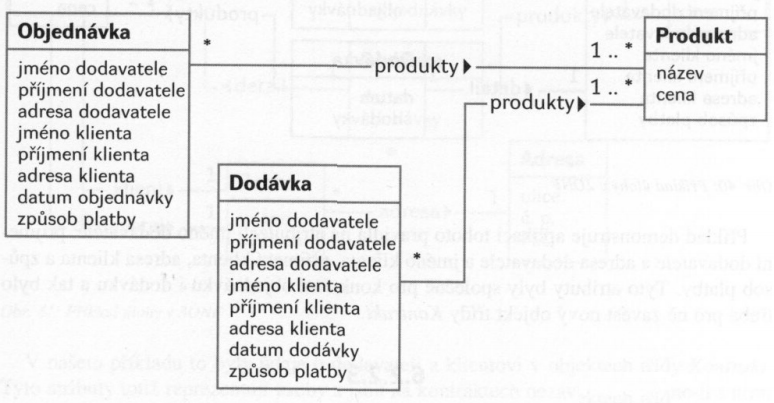
Obr. 38: 1ONF - normalizovaný model vytiahol údaje o produktoch
do samostatnej triedy, pričom trojice pôvodných atribútov nahradil
odkazom na kolekciu. To umožňuje odkazovať sa aj na viac ako tri
atribúty v prípade potreby a odstraňuje nevhodnú duplicitu atribútov.
2ONF: Trieda je v druhej objektovej normálnej forme, ak jej objekty
neobsahujú atribút, alebo skupinu atribútov, ktoré by boli zdieľané
s nejakým iným objektom. Zdieľané atribúty treba vyčleniť do objektu
novej triedy a vo všetkých objektoch, kde sa vyskytovali nahradiť
väzbou na tento objekt novej triedy. Schéma je v 2ONF, ak sú
všetky triedy v 2ONF.

Obr. 39: 2ONF - model po normalizácii - údaje uvedené teraz v triede
Kontrakt boli predtým zdieľané medzi triedami Objednávka a Dodávka,
preto ich možno vyčleniť do samostatnej triedy a v oboch triedach
použiť referenciu na príslušný kontrakt s podrobnými informáciami.
Vďaka tomu môže jeden kontrakt obsahovať aj viacero objednávok
a dodávok.
3ONF: Trieda je v tretej objektovej normálnej forme, ak jej objekty
neobsahujú atribút alebo skupinu atribútov, ktoré majú samostatný
význam nezávislý na objekte, v ktorom sú obsiahnuté. Ak také atribúty
existujú, je potrebné ich vyčleniť
do objektu novej triedy a v objekte, kde sa nachádzali nahradiť
väzbou na tento objekt novej triedy. Schéma je v 3ONF, ak sú všetky
triedy v 3ONF.
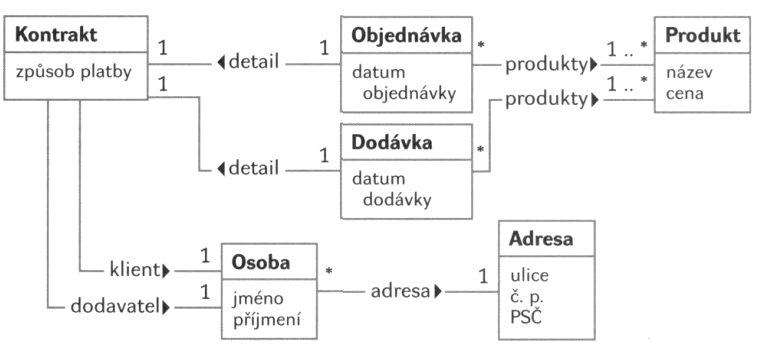
Obr. 40: 3ONF - model po výslednej normalizácii - údaje o dodávateľoch
a klientoch boli oddelené od údajov o kontrakte do samostatnej triedy.
To dovoľuje jednej osobe vystupovať vo viacerých kontaktoch bez
nebezpečnej duplicity. Naviac, adresy osôb boli tiež vyčlenené do
samostatnej triedy. To dovoľuje viacerým osobám zdieľať rovnakú
adresu.
Pri navrhovaní reprezentácie dát je potrebné dôkladne zvažovať
akými druhmi dotazov budeme dáta vyvolávať. Pre rozličné frekvencie
rôznych typov dotazov sa hodia rozličné reprezentácie.
Proces refaktorizácie je proces pri ktorom meníme štruktúru
kódu (alebo jeho návrhu) tak, aby sme dosiahli prehľadnejší,
prípadne efektívnejší kód. Príkladmi refaktorizácie na úrovni návrhu
môžu byť:
- presunutie metódy do nadtriedy: metóda nadtriedy sa detí, takže
funkčnosť inštancie zostáva nezmenená
- presunutie deklarácie dátovej položky do nadtriedy
- rozdelenie kódu jednej metódy na dve metódy, kde kód jednej
metódy obsahuje volanie druhej metódy
- operácie inverzné k op. 1-3
- premenovanie mena triedy alebo metódy alebo dátovej položky
- vrátane premenovania všetkých volaní alebo použití
- vykonanie transformácie podľa pravidla nejakej normálnej formy
4.5. Základné typy softvérovej architektúry
Softvérová architektúra tvorí základnú kostru aplikácie, zahŕňa softvérové
komponenty a vzťahy medzi nimi. Architektúra skrýva menej
podstatné informácie modulov a je abstraktným pohľadom na systém.
Definuje hlavne vzťahy medzi komponentami, ostatné vlastnosti
a informácie skrýva. Návrh okrem architektúry obsahuje aj informácie
o použitých algoritmoch a dátových štruktúrach a o vzhľade používateľského
rozhrania.
Architektúra pomáha dosahovať vlastnosti systému resp. bráni ich
dosiahnutiu; býva ťažké ju v priebehu projektu meniť. V softvérovom
inžinierstve sa zaužívalo niekoľko štandardných architektonických štýlov.
Navzájom sa nutne nevylučujú, dajú sa rôzne kombinovať a myšlienky v nich
obsiahnuté často slúžia ako inšpirácia pre individuálnu architektúru vytváraného systému.
4.5.1. Pipes and filters
Začnime jednoduchým motivačným príkladom - každý čitateľ tohto dokumentu je zrejme
aspoň občasným používateľom OS Linux. Sila rodiny OS Unix spočíva v myšlienke
- v jednoduchosti je sila, čo znamená, že UNIX obsahuje množstvo drobných utilít,
ktoré je možné navzájom prepájať v skriptoch a tak dosiahnuť obrovskú flexibilitu
systému. Jedným z bežných spôsobov prepájania programov je ich reťazenie pomocou
operátora pipe (|), ktorý spôsobí, že štandardný výstup jedného programu sa automaticky
presmeruje na štandardný vstup ďalšieho programu, takouto kombináciou vieme
v príkazovom riadku (command line) jednoducho poskladať užitočné aj
komplikovanejšie povely. Napríklad, nasledujúci povel:
$ ps aux | grep programcok | grep -v grep | awk '{print $2}' | xargs kill
zastaví proces, ktorý bol spustený s menom
programcok, pričom
ps aux vylistuje
podrobný zoznam všetkých procesov,
grep programcok vyberie len tie riadky zo zoznamu
procesov, ktoré obsahujú slovo
programcok, lenže tam sa objaví aj samotný proces grep,
takže následne
grep -v odfiltruje tie, ktoré obsahujú slovo grep - ostane riadok jediný
vo formáte
kluka 18441 0.0 0.0 9608 4252 pts/8 S+ Sep05 4:38 programcok
a pomocou programu
awk z neho vyberieme druhý stĺpec obsahujúci id procesu (pid),
ktorému pošleme signál 9 príkazom
kill s argumentom
pid, pričom program
xargs
zabezpečí, že argumenty programu
kill budú poskladané zo vstupu, ktorý dostane
príkaz
xargs. Každá z uvedených štandardných linuxových utilít robí malú transformáciu,
kde transformuje vstupné údaje na výstupné, takým utilitám v architektúre typu
pipes and filters
hovoríme filtre a sú poprepájané komunikačnými kanálmi (rúrami = pipes).
Z hľadiska architektúry informačného systému nemusí byť zapojenie filtrov len lineárne.
Niektoré filtre môžu syntetizovať viacero vstupov do jedného výstupu, alebo naopak produkovať
viacero výstupov z jedného vstupu, alebo vo všeobecnosti môžu mať viacero vstupov a výstupov.
Poprepájaním fitrov teda vznikne orientovaný graf, ktorý tvorí architektúru v štýle pipes and filters.
Komunikácia nemusí prebiehať cez presmerovaný štandardný vstup a štandardný výstup ako je v našom linuxovom príklade.
Každý operačný systém resp. jazyk poskytuje rôzne nástroje - napr. Unix poskytuje komunikačný kanál systémovým
volaním pipe(), v každom systéme sú dostupné TCP sockety, vo webovom prostredí websockety, v prostredí Java EE
napr. technológia JMS (Java Messaging Service) a ďalšie.
Veľkou výhodou takejto architektúry je vysoká modularita - jednotlivé filtre sú celkom nezávislé
od vnútornej implementácie a internej reprezentácie dát iných filtrov, jediné, čo potrebujeme zabezpečiť
je zladiť formát dát prenášaných v komunikačných kanáloch. Hociktorý filter je možné nahradiť alternatívnym,
ktorý robí z vonkajšieho hľadiska tú istú činnosť, ale dosahuje ju inými prostriedkami.
Vysoká modularita umožňuje dobrú znovupoužiteľnosť komponentov a je predpokladom väčšej životnosti softvéru.
Obrovskou výhodou tejto architektúry je dobrá paralelizovateľnosť výpočtu, ktorá je prakticky zadarmo
- bez toho, aby sa programátor akokoľvek musel starať o problémy synchronizácie procesov, ktoré sú
bežné a spôsobujú ťažkosti v iných prístupoch k paralelizácii (napr. výpočtové vlákna - thready). Každý
z filtrov, ktorý má vo vstupnom bufri dostupné dáta môže počítať. Ak je vnútorná architektúra filtrov
tiež postavená na pipes and filters, tak týmto spôsobom môžeme získať stovky až tísice filtrov, ktoré
sa môžu vykonávať súčasne - napr. na modernom paralelnom hardvéri podporujúcom výpočty na GPU.
Nevýhodou tejto architektúry je, že vyžaduje vysoký tok dát - každý filter má typicky na vstupných
kanáloch nejaké vstupné bufre, na výstupných zasa výstupné a tak sa pri každej, často aj elementárnej
čiastkovej operácii všetky dáta kopírujú cez bufre a interné reprezentácie jednotlivých filtrov. To má
logický dopad na nižší výkon v porovnaní s architektúrami, ktoré sú optimalizované na úspornosť zdrojov,
hoci často za cenu nižšej prehľadnosti a modularity.
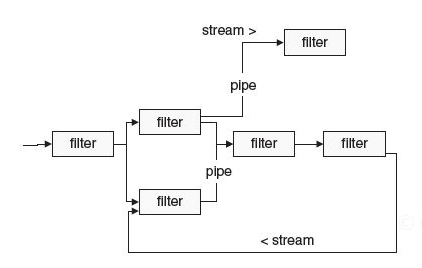
Obr. 41: Schématické znázornenie architektonického štýlu
pipes and filters.
4.5.2. Dávkové spracovanie / batch
V niektorých prípadoch je vhodné, aby sa dáta nespracovávali priebežne, on-line, aktuálne,
ale všetky naraz, v dávke. Typickým príkladom je spracovanie mesačnej alebo ročnej uzávierky
účtovníctva, kde je potrebné vytvoriť požadované mesačné alebo ročné správy, ktoré nie je
vhodné vytvárať skôr, keďže položky objednávok, faktúr a transakcií niekedy neprichádzajú
v správnom poradí, neskôr sa podľa potreby ešte upravujú a podobne. V dávkovom spracovaní
sa všetky údaje pripravia do jedného alebo viacerých dátových zdrojov, odštartuje sa výpočet,
ktorý ich rad za radom spracuje a vyprodukuje požadované výstupy. Dávkové spracovanie sa často
štartuje automaticky v čase, keď systém nie je zaťažený bežnou prevádzkou (nočné dávkové
spracovanie). Tu treba brať zreteľ na ošetrenie mimoriadnych prípadov, vytváranie podrobných
záznamov priebehu spracovania dávok, náročnosť ladenia a testovania, keďže si vyžaduje
prítomnosť testovacieho tímu mimo bežný pracovný čas. Práca sa pri dávkovom spracovaní
typicky člení do jednotlivých úloh (job), ktoré pozostávajú z mnohých položiek (item).
Rozličné vývojárske frameworky majú zabudovanú podporu (knižnice) na riešenie dávkového
spracovania. Napr. Java EE obsahuje
Batch Processing Framework
so sadou tried zabezpečujúcich riadenie dávkového spracovania - programátor píše
kód metód, ktoré spracovávajú jednotlivé položky a konfiguruje sekvenčnú alebo
paralelnú postupnosť spracovania. Podobne, rozsiahly javovský framework Spring
pre vytváranie veľkých podnikových aplikácií obsahuje svoj vlastný
Spring Batch Framework.
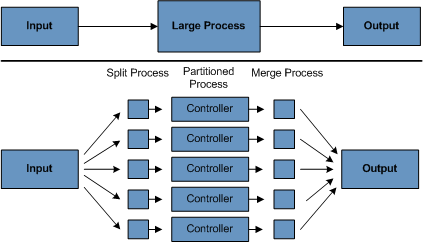
Obr. 42: Rozdielne prístupy k dávkovému spracovaniu - rozdelenie na paralelne spracovávané položky umožňuje zvýšiť efektívnosť architektonického štýlu
batch processing.
4.5.3. Client / server
Client = zákaznik, server = sluha. Ako už názov naznačil, ide o architektúru, kde jedna strana
(server) poskytuje nejakú službu, ktorá je typicky dostupná viacerým zákazníkom. V oboch
roliach však v architektúre vystupujú softvérové komponenty, nie reálni zákazníci, alebo
sluhovia. Komponent sluha teda obsluhuje iný komponent - zákaznika. Poskytuje mu nejakú
jasne definovanú službu podľa dohodnutého komunikačného rozhrania. Zákazník oslovuje
sluhu, aby mu službu dodal. Sluha môže svoje poskytované služby aj niekde zverejniť,
aby o nich zákazníci vedeli a aby sa dozvedeli špecifikáciu rozhrania, ktorým majú sluhu
osloviť. Pod službou si tu môžeme predstaviť rozličné veci - či už ide
o dodanie nejakých konkrétnych dát alebo súborov z/do úložiska, realizovanie nejakého
konkrétneho výpočtu, overenie bezpečnostného certifikátu, obsluha nejakého fyzického
alebo elektronického zariadenia, môže ísť o čokoľvek. Medzi problémy, ktoré server musí
riešiť, patrí prístup k zdieľaným zdrojom: ak naraz spracováva požiadavky viacerých
klientov, alebo naopak serializácia - zoradenie jednotlivých požiadaviek klientov
do poradia spracovania podľa stanovených kritérii priority.
Výhodou tejto architektúry
je nízke previazanie komponentov (low coupling), zvlášť, pokiaľ je serverovské rozhranie
definované tak, že obsahuje len nevyhnutné položky a všetky sú dostupné cez ten istý vstupný
bod - čo napr. webový server spĺňa, keďže príma požiadavky v univerzálnom protokole HTTP.
Dnes najrozšírenejším príkladom tejto architektúry je webový server, ktorý poskytuje vyžiadané
webové stránky webovým klientom - väčšinou internetovým prehliadačom.
Iné príklady servrov sú: tlačový server, databázový server, aplikačný server, ale v roli
servera môže vystupovať aj ľubovoľný konkrétny komponent informačného systému a poskytovať
nejakú internú službu ostatným komponentom toho istého systému. Komunikácia medzi komponentami
typicky využíva nejakú komunikačnú technológiu (napr. TCP/IP - sockety alebo datagramy),
alebo priamo technológiu podporujúcu poskytovanie služieb (SOAP, REST a pod.).

Obr. 43: Schématické znázornenie architektonického štýlu
client / server.
4.5.4. Master / slave
Ak na zabezpečenie určitej funkcionality nestačí jeden počítač, ale je vhodnejšie použiť celú skupinu
počítačov, môžeme využiť architektúru master/slave. Jeden centrálny počítač (master) rozdeľuje prácu a zodpovedá
za celkový výsledok. Ostatné počítače (slaves) pravidelne kontaktujú mastera, či pre ne nemá nejakú novú
úlohu. Po pridelení čiastkovej úlohy pracujú, až kým ju nevyriešia a napokon svoj výsledok odošlú na mastra.
Master čiastkové výsledky integruje do celkového výsledku.
Vo väčšine prípadov je práca nastavená flexibilne vzhľadom na počet pripojených slaveov, ktorí sa k procesu
priebežne pripájajú a odpájajú. Master by sa mal postarať aj o situácie, keď slave nedodá svoj čiastkový
výsledok včas a prideliť prácu inému slaveovi. Slaveovia, ktorí sú aktívni, masterovi pravidelne hlásia
svoj stav - pripravený alebo obsadený.

Obr. 44: Schématické znázornenie architektonického štýlu
master / slave.
Architektúra master/slave sa často kombinuje s architektúrou client/server, keď celá skupina master so svojimi slaveami poskytujú nejakú službu clientovi. Client posiela zložitú úlohu na mastera, ktorý ju rozdelí na čiastkové úlohy pre svojich slaveov a po ukončení poskytne celkový výsledok clientovi.
Obr. 45: Kombinácia architektúry
client / server a
master / slave: server poskytuje výpočtové služby,
client odošle vstupné dáta a popis úlohy, ktorú treba vypočítať, na server/master. Ten spravuje skupinu slaveov.
Z nej vybere vhodného slavea, ktorý je práve voľný a poskytuje požadovaný typ výpočtu. Odošle mu vstupné údaje
a popis úlohy. Po dopočítaní slave pošle výsledok na mastera, kde čaká vo fronte dovtedy, kým si ho client
nevyzdvihne. Každý slave sa pravidelne hlási masterovi zaslaním datagramu (protokol UDP), ostatná komunikácia
prebieha cez TCP sockety.
4.5.5. Paralelné komunikujúce procesy
Už dávno sa počítače nepoužívajú len ako lepšie kalkulačky - na vykonávanie postupností zložitejších výpočtov.
Informačné systémy nahrádzajú množstvo činností, ktoré sa v minulosti robili ručne, výmenou fyzických papierov
a dokumentov, komunikáciou reálnych ľudí a inštitúcií a ich rozhodnutiami a pod. Informačné systémy sú teda
modelmi reality. Pre realitu je však typické, že množstvo vecí sa deje naraz, súčasne. Informačný systém
(keďže za sekundu počítač dokáže vykonať miliardy operácií) takúto paralelnú realitu zvláda obslúžiť aj sekvenčne
- stačí, ak si ku každej paralelne vykonávanej aktivite zriadi potrebné dátové štruktúry a ak nejaká aktivita
trvá dlhšie, tak na jeden raz z nej urobí vždy len jeden malý krok, aby výsledok vyzeral tak, že všetky
potrebné aktivity sústavne napredujú. Avšak, ak bude vnútorná architektúra informačného systému lepšie
zodpovedať realite - to znamená každú z paralelne vykonávaných operácií obslúži samostatný výpočtový
proces (alebo výpočtové vlákno - thread), tak bude výsledný informačný systém prehľadnejší, zrozumiteľnejší,
jeho architektúra bude pre túto situáciu vhodnejšia. A to je základ myšlienky architektonického štýlu paralelných komunikujúcich
procesov.
Príkladom môže byť bankový informačný systém, ktorý naraz umožňuje viacerým zákazníkom vyberať / vkladať
v bankomatoch (po anglicky ATM - automated teller machine). Namiesto toho, aby jeden centrálny bankový
systém neustále komunikoval so všetkými aktívnymi ATM, môže byť každý zákazník obslúžený samostatným
procesom. Výhodou je, že tento proces sa môže zákazníkovi neustále venovať a napr. reagovať okamžite na jeho
interakciu (rozhodne sa prerušiť transakciu, a pod.), aj keď spracovanie jeho operácií v banke trvá
najaký čas - deje sa asynchrónne, v pozadí.
Podobná situácia nastáva v systémoch, ktoré komunikujú s akýmikoľvek fyzickými entitami
- nielen ľuďmi, napr. obsluha rozličných zariadení, strojov, senzorov vo fabrikách alebo v iných
automatizovaných systémoch, vstupno/výstupných zariadení počítača, alebo aj rôznych úloh,
ktoré informačný systém zabezpečuje súčasne a nesúvisia priamo s vonkajším fyzickým svetom
- každá úloha môže byť riešená v samostatnom procese.
Dôležitým rysom v tejto architektúre je zvolenie vhodného komunikačného a synchronizačného protokolu
vrátane komunikačnej i synchronizačnej technológie - procesy či vlákna?, dátové štruktúry v zdieľanej pamäti, či sockety,
alebo webové sľužby?, flagy/semafóry/mutexy/monitory/bariéry? zbernica/sériová komunikácia/počítačová sieť?
Variantom tejto architektúry je multi-agentová architektúra, ktorá sa vyznačuje tým, že každý proces (v tomto prípade agent)
si užíva vysoký stupeň autonómnosti, čiže väčšinou sám zodpovedá a sám riadi svoje konanie, má k dispozícii spôsoby
ako zbierať informácie z prostredia, v ktorom pôsobí a spôsoby, ktorými môže vykonávať v prostredí akcie podľa svojho
rozhodnutia. Multi-agentová architektúra dosahuje vysokú modularitu a znovupoužiteľnosť, v multi-agentových systémoch
typicky možno pridávať/odoberať agentov bez toho, aby to ovplyvnilo činnosť zvyšku systému.
Samotný architektonický štýl paralelných procesov ani multiagentová architektúra neodpovedajú na množstvo otázok,
ktoré musia návrhári pri využití tohto štýlu vyriešiť a väčšinou sa kombinuje s nejakými inými architektonickými štýlmi.
4.5.6. Systémy založené na udalostiach
Koncept, ktorý s udalosťami úzko súvisí, je stav. Každá udalosť, ktorá sa niekde udeje - či už v reálnom svete, alebo v informačnom systéme,
má za následok, že sa nejakej entite zmenil stav. Napríklad: udalosť Bill udrel Freda znamená, že sa Fredovi zmenil stav brady,
lebo ju už má rozbitú. Vybudovanie informačného systému podľa tohto architektonického štýlu znamená, že väčšina jeho
funkcionality sa deje, resp. aktivuje vtedy, keď sa zmenil stav, čiže nastala nejaká udalosť. Udalosť vedie k notifikácii (poslanie správy)
tých komponentov, ktoré na danú zmenu stavu chcú nejakým spôsobom reagovať. Následkom notifikácie
o udalosti je vykonanie postupnosti akcií. Tie potenciálne môžu viesť k ďalším zmenám stavu a teda k aktivovaniu
ďalšej a ďalšej funkcionality.
Čitateľ si určite rád ako cvičenie predstaví relevantné príklady využitia tejto architektúry.
Tu si predstavme akademický informačný systém: štúdijný program, ktorý
je
zverejnený na fakultnej webovej stránke, vie ručne vygenerovať (vyexportovať) správca AISu. Vhodnejší model
by bol, ak by sa po každej zmene v informačnom liste nejakého predmetu (udalosť => zmena stavu)
funkcionalita exportu aktivovala automaticky. Modul, ktorý export realizuje, sa vopred
zaregistruje, aby dostával o zmenách v informačných listoch notifikácie. Ešte lepšia možnosť:
notifikáciu nedostane nejaký exportovací modul, ale objekt, ktorý zodpovedá príslušnému štúdijnému
programu. Každý štúdijný program potom odchytáva notifikácie o zmenách vo všetkých svojich
predmetoch. Ak je nejaký predmet zaradený vo viacerých štúdijných programoch, automaticky
takto dojde k vyexportovaniu všetkých z nich.
Tento architektonický štýl sa mimoriadne dobre hodí na programovanie grafických používateľských rozhraní (GUI),
ktoré fungujú na princípe udalostí - interakcie používateľa so systémom - výber v menu, stlačenie tlačidla,
navigácia na stránke, to sú všetko udalosti. Treba len pripomenúť, že GUI nie je jediné využitie tohto štýlu
a udalosti môžu zodpovedať aj ľubovoľnej zmene akejkoľvek entity, ktorú systém modeluje.
Do extrému vo využití tohto architektonického štýlu ide programovaci jazyk JavaScript, kde sa cez
notifikácie na udalosti realizuje úplne všetko. Táto filozofia vyplýva z dvoch cieľov: 1) krátka odozva
na interakciu používateľa s webovou stránkou, 2) jednovláknová architektúra - všetko sa deje v tom
istom výpočtovom vlákne, čo dramaticky zamedzuje vzniku problémov pri synchronizácii viacerých vlákien.
Aby sa pomocou jedného výpočtového vlákna dosiahla rýchla odozva, akékoľvek operácie, ktoré trvajú
nejaký nezanedbateľný čas je potrebné urobiť asynchrónne a ich ukončenie považovať za udalosť, ktorá
generuje notifikáciu, na ktorú sa zareaguje v najbližšom možnom čase - keď dojde na rad pri jednovláknovom
spracovaní všetkých už čakajúcich notifikácií.
Postupné vykonávanie udalosťami aktivovaného kódu sa často realizuje dátovou štrktúrou
event queue. V okamihu, keď nejaká udalosť nastane, sa požiadavka na jej spracovanie zaradí na koniec frontu. Tam počká až dovtedy, kým na ňu nepríde rad. Ostatné udalosti čakajúce vo fronte pred ňou nastali skôr. Preto budú spracované prv. Aby reakcia systému na udalosti netrvala dlho, je potrebné, aby spracovanie ľubovoľnej udalosti prebehlo v čo najkratšom čase. Aplikácie môžu generovať udalosti napríklad aj preto, že chcú odštartovať vykonávanie nejakej inej časti kódu, niekedy čoskoro potom, čo dokončia spracovanie svojej požiadavky, prípadne nastavia generovanie istej udalosti v pravidelných časových intervaloch.
4.5.7. Architektúra zameraná na služby (Service Oriented Architecture, SOA)
Ide o jeden z modernejších štýlov, blízky príbuzný architektúr
software as a service (SAAS),
data as a service,
platform as a service a všetko objímajúci
cloud.
Vychádza zo stále väčšej potreby prepájania rôznych aplikácií a služieb, ktoré niekedy v čase návrhu ani nie sú známe.
To si vyžaduje pri zverejnení nejakej služby zverejniť aj rozhranie, ktorým je táto služba dostupná.
A to v takom formáte, aby mu iný informačný systém mohol porozumieť automaticky, bez potreby zásahu vývojára.
Typickým príkladom sú webové služby (web services) vybudované technológiou SOAP. Takáto webová služba, ktorá
je dostupná cez Internet, zverejňuje aj tzv. SOAP descriptor, čo je XML súbor podrobne popisujúci zverejnené
rozhranie. Tým pádom je voči takémuto descriptoru možné automaticky vytvoriť triedy, ktoré takéto služby
volajú a plynule ich zaradiť do systému, ktorý bol vyvinutý skôr ako samotná služba. V dnešnej rýchlo sa
meniacej dynamickej dobe je takto možné priebežne vyberať z dostupných servrov, ktoré požadované služby poskytujú.
Tento medzikrok často realizuje broker, u ktorého sa jednotlivé servre poskytujúce služby registrujú
a ktorý dokáže realizovať požiadavky klientov prispôsobené na rozhranie toho-ktorého servra.

Obr. 46: Service-oriented architecture.
4.5.8. Virtual machine
Pod pojmom stroj (machine) sa v tomto kontexte chápe počítač ako taký. Počítač ako zariadenie, ktoré dokáže realizovať
výpočet podľa zadaného programu. Virtuálny stroj je teda tiež počítač, ktorý realizuje výpočet podľa zadaného programu,
ale nie fyzický, ale len virtuálny - čiže je to model fiktívneho počítača. Reálny počítač je nahradený softvérom, ktorý ho emuluje,
virtuálnym strojom.
Výhody tohto prístupu sú viaceré. Jednak programy, ktoré sú napísané pre virtuálny stroj a nie pre reálny stroj, môžu
bežať na ľubovoľnom reálnom stroji, na ktorom je k dispozícii príslušný virtuálny stroj. Ďalej, tento výpočet môže byť
pod lepšou kontrolou - virtuálny stroj môže neustále monitorovať, čo program robí a priraďovať mu práva, obmedzenia,
priority, spravovať jeho zdroje podľa potreby. Ale hlavne - virtuálny stroj nemusí byť univerzálnym počítačom s operačným
systémom, ktorý poskytuje všetky komplexné služby, ale len jednoduchým jednoúčelovým interpretrom, ktorý dokáže spracovávať
skripty riešiace úzku vymedzenú skupinu úloh. Napriek tomu v rámci takto vymedzeného sveta poskytuje veľkú
flexibilitu a univerzálnosť a nie je zaťažený rozhodnutiami o poskytovanej funkcionalite vytvorenej v čase návrhu systému,
až v čase vytvárania skriptov, ktoré virtuálny stroj spracováva. To môže byť oveľa neskôr, dávno po jeho nasadení
do prevádzky.
V učebnici Software Engineering - Modern Approaches je uvedený nasledujúci príklad programu spracovávaného virtuálnym
strojom, ktorý mohol napísať v takto špecializovanom jazyku aj samotný používateľ:
Balance checking / add excess to account + subtract deficit from saving;
Save report / c:Reports + standard headings + except replace "Ed'' by "Al'' PrintReport / standard headings
e-mail report to Jayne@xyz.net.
4.5.9. Repository
V tomto architektonickom štýle sú základom pre architektúru systému dáta, množstvo dát. Často sú tieto dáta trvácne a
v systéme sa k nim pristupuje viacerými spôsobmi, z viacerých komponentov, viacerými používateľmi.
Vtedy má zmysel dáta uskladniť v centrálnom sklade dát - typicky v databáze. Repozitár môže mať aj inú podobu - napríklad
súborový alebo webový server, na ktorom je uložených množstvo súborov alebo hypertextových dokumentov tiež spadá pod tento
architektonický štýl, alebo centrálna adresárová služba, ktorá eviduje autentifikačné údaje používateľov, ktoré sú spoločné
pre celú rodinu aplikácií.
Samostatným variantom je tzv. blackboard architektúra, kde blackboard je úložiskom prevažne dočasných dát a slúži na výmenu
údajov medzi jednotlivými komponentami v zmysle: všetci vidia na tabuľu, každý na ňu môže čokoľvek napísať a tým sa dorozumievať
s ostatnými - blackboard môže byť komunikačnou platformou v multi-agentových systémoch.
Výhodou architektúry v štýle repository je možnosť centrálneho riešenia zálohovania, bezpečnosti a prístupových práv, zotavenia
z poruchy a pomerne dobrá možnosť dopĺňania ďalšej funkcionality, ba i aplikácií, ktoré pracujú s údajmi v repozitári.
Medzi nevýhody patrí komplikovanosť dátového modelu - ak databáza zahŕňa všetky údaje z celého systému, množstvo závislostí je
veľké a málo prehľadné - čo v prípade nutnosti zmeny dátového modelu spôsobí problémy, centrálne zabezpečenie niektorých služieb
(zálohovanie, bezpečnosť...) nemusí vyhovovať všetkým častiam aplikácie. V prípade veľkej prevádzky nemusí repozitár stačiť
obslúžiť všetky požiadavky a distribuovanie repozitára na viacero počítačov môže byť komplikované.

Obr. 47: Príkladom frameworku, ktorý zovšeobecňuje prístup k repozitárom rôznych druhov je oraclovský Data Anywhere Architecture a jej
Repository API.
4.5.10. Hierarchická / vrstvová
Ako dobrá ilustrácia nám tu môže poslúžiť organizácia softvéru na bežnom PC. Na najnižšej vrstve je samotný hardvér - procesor,
pamäť, vstupné a výstupné zariadenia, ktoré komunikujú na nízkoúrovňovom protokole a svoju funkcionalitu vystavujú cez
vstupno/výstupné porty dostupné cez inštrukcie strojového kódu OUT a IN, resp. cez priamy prístup do pamäte.
S týmto hardvérom na tejto úrovni programy
nikdy nekomunikujú. Na vrstve nad hardvérom je jednak základný systém, ktorý je uložený v pamäti ROM - BIOS (basic input/output system),
alebo jednotlivé hardvérové ovládače, ktoré sú zavedené do jadra operačného systému. S nimi komunikujú všeobecnejšie služby
operačného systému (súborový systém, vstup z klávesnice, myši, výstup na obrazovku), nad nimi sú ďalšie, ešte všeobecnejšie
služby operačného systému (grafický okienkový manažer, správca programov a procesov a pod.) Tieto služby sú využívané dynamicky
i staticky linkované knižnicami, poskytujúcimi komplexnú funkcionalitu rôznym aplikáciám a o vrstvu ďalej nájdeme samotné aplikačné programy...
Každá vrstva komunikuje s vrstvou pod sebou a poskytuje o rád všeobecnejšiu funkcionalitu vrstve nad ňou.
Obr. 48: Príklad hierarchickej / vrstvovej architektúry pri využití technológie OpenGL.
Vrstvová hierarchická architektúra sa nemusí týkať len celého počítača a operačného systému. Tu sa zaoberáme informačnými systémami
a nie operačnými systémami. V tomto štýle môžu byť vybudované aj samotné aplikácie/informačné systémy. Jednotlivé vrstvy sú typicky
realizované balíčkami tried (packages), ktoré skrývajú podrobnosti pred ďalšími vrstvami. Pre dosiahnutie jednotlivých zložiek
celkovej funkcionality aplikácie môže existovať viacero paralelných vrstvení. Je vecou designu, na aké konkrétne vrstvy a do koľkých
vrstiev bude návrh rozdelený. Vrstvová architektúra (layered architecture) úzko súvisí s tzv. "Three tier" architektúrou, kde
je informačný systém rozdelený na 3 samostatné poschodia - prezentačné (používateľské rozhranie), dátové (úložisko perzistentných
dát - databáza) a aplikačné (logika, stredné poschodie). Rozdiel medzi "three tier" a "layered architecture" je v tom, že pri "three tier"
beží každé poschodie na inej infraštruktúre/platforme (napr. webový prehliadač - prezentačné poschodie, aplikačný server - aplikačné
poschodie, databáza - dátové poschodie. Analogicky môže existovať "one tier" aplikácia, ktorá celá beží na jednej platforme (desktop alebo
mobil), ale má (napríklad) tri vrstvy - vtedy ide o vrstvovú architektúru.
4.5.11. Zdieľaná pamäť vs. skrývanie informácií
Architektonický štýl zdieľaná pamäť niekedy označuje skupinu štýlov (Blackboard, Data-centric, Rule-Based system), ale v našom kontexte máme na mysli to,
že jednotlivé komponenty informačného systému majú uložené údaje v spoločnej pamäti a majú k nim spoločný prístup. Je to v zásadnom rozpore
so štýlom skrývanie informácií, ktorý vychádza z enkapsulácie v objektovo-orientovanom programovaní. Pri použití zdieľanej pamäte sa porušuje
základný cieľ pri tvorbe návrhu - minimálne rozhrania, keďže komponenty majú prístup k detailným údajom uloženým v zdieľanej pamäti a vznikajú
medzi reprezentáciou dát a jednotlivými komponentami závislosti, ktoré je vhodné pri návrhu minimalizovať. Jeho využitie
je napriek tomu na mieste vtedy, keď sú v zdieľanej pamäti uložené (väčšinou) nemenné údaje veľkého rozsahu, s ktorými potrebuje pracovať viacero komponentov - často,
opakovane, rýchlo.
Namiesto toho, aby si komponenty tieto údaje medzi sebou preposielali - a tým zaťažovali zbernicu, procesor i pamäť vytváraním osobitných kópií,
údaje sú uložené v pamäti len raz a všetky komponenty s nimi môžu pracovať. Napríklad, obrázok z kamery s obrovským rozlíšením, v ktorom rôzne
algoritmy využívajú rôzne údaje, iné ho zasa vizualizujú, škálujú, alebo inak spracovávajú - stačí, aby bol v pamäti len jeden raz. Komunikácia
cez zdieľanú pamäť je maximálne rýchla, pretože je priama - počas komunikácie nevyužíva žiadne medzivrstvy operačného systému, nepotrebuje
prepínanie kontextu medzi user a kernel módom. Vo väčšine operačných systémov je komunikácia cez zdieľanú pamäť možná aj medzi rôznymi
procesmi. Systémové volania OS dovoľujú alokovať úsek pamäte, ktorý si viaceré procesy namapujú do svojho adresného priestoru. Napríklad
v systémoch Linux existujú systémové volania shmget(2), shmat(2), vo Windows sú to CreateFileMapping(), OpenFileMapping().
4.5.12. Microservices
Tento architektonický vzor je najviac up-to-day so súčasným dianím vo svete informačných systémov a údajne je základom takých gigantov, ako sú
Netflix, eBay, Amazon, the UK Government Digital Service, realestate.com.au, Forward, Twitter, PayPal, Gilt, Bluemix, Soundcloud, The Guardian
a mnohých ďalších. Štýl vychádza z notorických skúseností vývojárov o častej potrebe zmien požiadaviek počas reálneho nasadenia systému.
Preto sa usiluje o maximálne oddelenie komponentov, ktoré tvoria systém - každý z nich je samostatnou aplikáciou, ktorá poskytuje čo najmenšiu
množinu konzistentných služieb ostatným komponentom, typicky cez nejaký rýchly, jednoduchý a transparentný protokol (napr. REST).
Realizovanie zmeny v systéme si potom vyžaduje len úpravu niektorej služby a minimálnú vyžiadanú úpravu rozhraní služieb, takýto systém sa
jednoduchšie aktualizuje priamo počas prevádzky systému, dovoľuje inkrementálny vývoj a plynulé nasadzovanie jednotlivých častí ako sa dokončujú.
Každý komponent je jednoduhcšie samostatne otestovateľný. Microservices sú v kontraste so systémami, ktoré sa spoliehajú na pokročilé
a komplikované komunikačné platformy (enterprise service bus), ktoré sú typické pre SOA. Naopak, microservices používajú čo najjednoduchšie
komunikačné kanály a s čo najjednoduchšími rozhraniami - a preto ich popularita rastie. Narozdiel od bežných podnikových aplikácií, ktoré
zvyknú ukladať údaje do jednej spoločnej databázy má typicky každá služba v rámci tejto architektúry svoje perzistentné úložisko. To potenciálne
vedie k dočasným vzájomným nekonzistenciam údajov a jednotlivé služby sa musia medzi sebou nejak synchronizovať, čo môže predstavovať
výzvu, niekedy až prekážku pri nasadzovaní aplikácií podľa tejto architektúry.
5. Návrhové vzory
Návrhové vzory sú ustálené postupy pri tvorbe návrhu,
ktoré vývojári informačných
systémov používajú znova a znova a preto im pre zjednodušenie dali
meno a podrobne ich analyzovali, aby pri tvorbe ďalších systémov,
v ktorých sa rovnaké situácie znovu vyskytnú, mohli využiť existujúce
skúsenosti a priamo v nich aplikovať optimálne postupy. Týmto
sa podobajú na architektonické štýly. Rozdiel je v tom, že návrhové
vzory často riešia len malý čiastkový problém v návrhu, zatiaľ čo
architektonické štýly ovplyvňujú celkovú architektúru aplikácie.
Každý návrhový vzor je určený svojim menom, krátkym popisom účelu,
a vychádza z nejakej konkrétnej situácie v reálneho života pri tvorbe
informačného systému. Viaceré zdroje pre každý konkrétny návrhový
vzor ukazujú príklad implementácie zodpovedajúcej situácie,
popisujú roly zúčastnených prvkov v danej situácii, zakresľujú
triedny a objektový diagram zovšeobecnenej situácie a uvádzajú
výskyty návrhového vzoru v známych informačných systémoch.
Vychádzajúc z knihy Design Patterns (Erich Gamma et.al.) si pomenujme
22 známych návrhových vzorov, ktoré su v nej uvedené. Delia sa na tri typy:
Creational - slúžia alebo nejak súvisia s vytváraním nových inštancií,
Structural - určujú štruktúry, ktoré zjednodušujú stavbu návrhu, jeho
architektúru, Behavioral - pokrývajú určité správanie, interakciu
medzi objektami.
5.1. Creational Patterns
Tieto návrhové vzory sa týkajú spôsobu vytvárania nových objektov.
5.1.1. Abstract Factory
Provide an interface for creating families of related or dependent objects without specifying their concrete classes
Abstract Factory je trieda (príp. interface), ktorá poskytuje funkcie na vytváranie inštanciíi nejakej skupiny tried.
Namiesto toho, aby sme priamo volali konštruktory príslušných tried, ktorých inštancie chceme na danom mieste vytvoriť,
si vypýtame referenciu na factory ("fabriku"). Jej metódy vedia vrátiť nové inštancie potrebných typov. V skutočnosti
k danej abstract factory existuje jedna (väčsino viacero) podtried - concrete factory, ktoré prekrývajú uvedené metódy.
Inštancie vracajú až implementácie metód v podtriedach (v concrete factories).
Význam takéhoto triku spočíva v tom, že náš
kód sa stáva nezávislý od konkrétnych implementácii potrebných tried. Inštancie, ktoré takto získame spĺňajú požadované
vlastnosti, ale v skutočnosti sú inštanciami nám neznámych tried, ktoré sú podtriedami nami požadovaných tried. V závislosti
od prostredia, v ktorom náš kód beží, môžeme získať inú "konkrétnu fabriku", ktorá vracia objekty iných tried, ale tieto implementačné
detaily sú pre náš kód skryté. Vďaka tomu je náš kód prenositeľnejší a môže fungovať v rozličných prostrediach bez zmien.
Abstract factory je väčšinou súčasťou nejakého frameworku a týmto spôsobom poskytuje jednotné rozhranie pre aplikácie
aj keď je framework implementovaný pre rozličné platformy.
Príkladom je framework pre vytváranie rôznych GUI widgetov - okienok, scrollbarov, dialógov, progressbarov a podobne.
Aplikácia, ktorá chce vytvárať objekty uvedených typov, požiada framework o "fabriku". Framework - podľa toho, na ktorej
platforme práve beží, vráti "fabriku", ktorá vracia objekty pre príslušnú platformu - napr. v systéme MS Windows vráti
objekt, ktorý vie zobraziť windowsové okno, v systéme xwindows vráti objekt, ktorý zobrazuje X-ovské okno. Aplikácia
od "fabriky" takto získava objekty, ktorých typ je všeobecný (napr. okienko) a nestará sa o to, na ktorej platforme
práve beží.
Abstract factory má často metódy podľa vzoru
factory method, ale môže využiť aj
prototype. Concrete factory je často singleton.
Obr. 49: Štruktúra návrhového vzoru Abstract Factory (
Wikimedia).
5.1.2. Builder
Separate the construction of a complex object from its representation so that the same construction process can create different representations.
Builder je abstraktná trieda, ktorá ponúka sadu čiastkových krokov, z ktorých je možné skladať zložitejšie objekty. Tento abstraktný
builder má viacero konkrétnych podtried (konkrétnych builderov), ktorí tie isté čiastkové kroky realizujú iným spôsobom,
iným štýlom, v inom formáte a podobne. Vďaka tomu môžeme napísať algoritmus, ktorý pozostáva z týchto čiastkových krokov, ale ktorý
je nezávislý od toho-ktorého podrobného formátu.
Náš algoritmus využíva abstraktný builder a ním definované metódy, ktoré sa v skutočnosti realizujú jednou z možných implementácií
v jednom z konkrétnych builderov prekrývajúcich príslušné metódy.
Príkladom takéhoto buildra môže byť konverzia textu. Abstraktný builder ponúka elementárne stavebné kroky ako - pridať znak,
ukončiť odstavec, zmeniť font textu a podobne. Konkrétne buildery môžu byť napr. tri rôzne - jeden, ktorý produkuje plain ASCII text,
druhý, čo produkuje TeX-ový zdroják, tretí, ktorý zobrazuje text v nejakom grafickom widgete. Každý z nich interpretuje jednotlivé
kroky po svojom. Trieda, ktorá tento builder využije môže mať za úlohu zparsovať (prečítať) súbor vo formát RTF. Počas dekódovania
RTF súboru postupne volá jednotlivé krokové operácie konverzného buildra. Tento algoritmus prečítania RTF súboru bude však univerzálny
a môžeme ho ľahko spojiť s ľubovoľným typom konvertera (plain ASCII, TeX, widget) bez toho, aby sme ho akokoľvek potrebovali meniť.
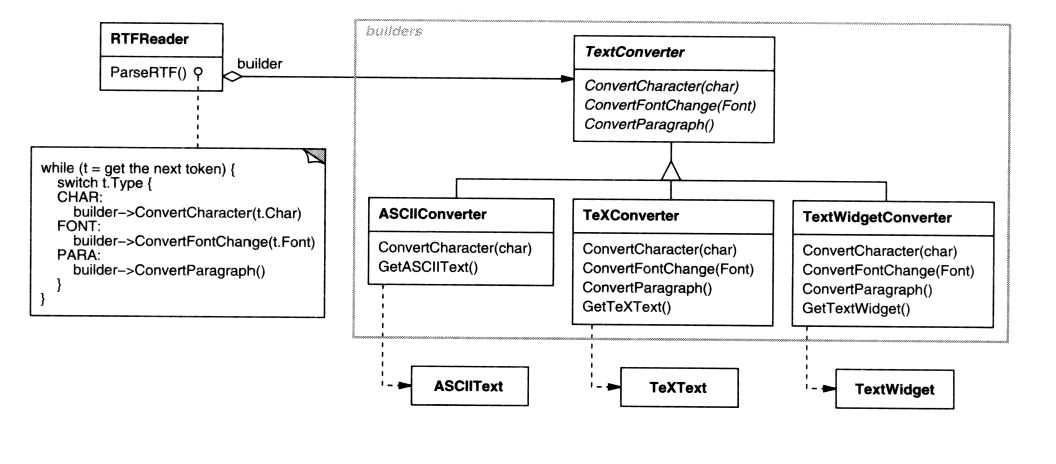
Obr. 50: Príklad využitia návrhového vzoru Builder.
5.1.3. Factory Method
Define an interface for creating an object, but let subclasses decide which class to instantiate. Factory Method lets a class
defer instantiation to subclasses.
Factory method je taká metóda v nejakej abstraktnej triede (túto triedu nazvime Creator), ktorá zodpovedá za vytvorenie
určitého typu inštancie (tento typ nazvime Product). V skutočnosti však inštanciu vytvára prekrývajúca metóda v nejakej
konkrétnej podtriede Creatora a vracia inštanciu nejakej podtriedy triedy Product.
Napriek tomu môžu iné metódy Creatora použiť túto factory method - len vždy dostanú inštanciu z nejakej vhodnej zodpovedajúcej
podtriedy triedy Product, podľa toho, na ktorej podtriede Creatora sú volané.
Trieda Creator a Product je teda typicky súčasťou nejakého frameworku, pričom súčasťou tohto frameworku je aj nejaká ďalšia funkcionalita
využívajúca inštancie typu Product. Používateľ tohto frameworku - nejaká naša cieľová aplikácia definuje podtriedu Creatora -
nejakého konkrétneho Creatora, ktorého prekrývajúca factory method bude vracať inštanciu nejakej našej triedy odvodenej od frameworkovej triedy Product.
Napríklad, si predstavme framework, ktorý umožňuje evidovať viacero dokumentov používateľa a už má implementovanú metódu NewDocument(), ktorá
zavolá factory method na vytvorenie dokumentu (ten však framework nedefinuje) a pridanie tohto dokumentu do zoznamu evidovaných dokumentov.
Náš systém, ktorý takýto framework využije vytvorí podtriedu triedy, ktorá eviduje dokumenty a prekryje v ňom factory method, ktorá bude
vytvárať dokument nášho typu. Táto situácia je zachytená na nasledujúcom obrázku, pričom trieda Application je v roli Creator, trieda
Document je v roli Product, MyApplication je v roli ConcreteCreator a MyDocument je v roli ConcreteProduct.

Obr. 51: Príklad použitia návrhového vzoru Factory Method.
5.1.4. Prototype
Specify the kinds of objects to create using a prototypical instance, and create new objects by copying this prototype.
Opäť si pomôžme motivačným ilustračným príkladom zo sveta OS Linux. Vytváranie nového procesu v unixových systémoch sa realizuje
pomocou systémového volania
fork(). Toto volanie zduplikuje proces, ktorý
fork() zavolal. Výsledkom je, že namiesto
predchádzajúceho jedného procesu bežia v systéme zrazu dva identické procesy, ktoré sa (zjednodušene povedané) líšia len
v návratovej hodnote volania
fork() - pôvodný (rodičovský) proces dostane nenulový identifikátor (pid)
novo-vytvoreného procesu, nový proces (dieťa) dostane nulu. Keďže programová pamäť je read-only (proces nemá možnosť
meniť za behu svoj vlastný kód), táto pamäť je zdieľaná medzi oboma procesmi. Všetky dáta aj informácie, ktoré o procese
eviduje operačný systém, sa zduplikujú (v prípade vhodnej implementácie sa dáta môžu zduplikovať až pri prvom zápise
do príslušnej stránky - technika
copy on write). Tento postup (
fork()) sa používa aj vtedy, keď nejaký proces chce odštartovať
iný program - najskôr sám seba zduplikuje pomocou
fork() a až potom jeho dcérsky proces zavolá systémové volanie
exec(),
ktoré nahradí aktuálne bežiaci program novým, načítaným zo spustiteľného súboru. Prečo je to tak?
Operačný systém eviduje o procesoch množstvo informácií - prístupové práva, otvorené súbory, premenné prostredia, priorita a pod.
Pri vytvorení nového procesu tak povediac "na zelenej lúke" by musel stráviť netriviálny čas tým, aby zistil, čo všetko má do týchto
svojich interných tabuliek o novom procese povypĺňať. Oveľa jednoduchšie je zobrať údaje o nejakom existujúcom procese (a najlepšie
rovno o tom, ktorý ten nový proces vytvára) a skopírovať ich - naklonovať ich. Je to rýchlejšie, úspornejšie a jednoduchšie.
A to je zároveň myšlienka návrhového vzoru Prototype pri objektovom návrhu OOP (pozor! ilustračný príklad s fork() je len analogická situácia, ilustračný príklad na pochopenie princípu, ale tam ide o niečo iné ako o návrh systému v OOP).
Návrhový vzor prototyp predpisuje, že nové inštancie nejakej triedy (alebo často skôr skupiny tried zastrešenej nejakou spoločnou
abstraktnou nadtriedou) sa nevytvárajú volaním konštruktora. Namiesto toho sa vyrábajú naklonovaním nejakej existujúcej inštancie
(napr. v jazyku Java obsahuje každá trieda metódu Clone()). Výsledkom je zjednodušenie a zrýchlenie kódu a tým aj zamedzenie
vzniku potenciálnych chýb.
5.1.5. Singleton
Ensure a class only has one instance, and provide a global point of access to it.
Asi najjednoduchší návrhový vzor, ktorý hovorí o tom, že nejaká trieda má v celom systéme iba jednu inštanciu - v celej aplikácii existuje
jediný objekt danej triedy. Táto trieda by mala poskytovať nejakú statickú (triednu) metódu, ktorá vráti príslušnú inštanciu.
V prípade, že inštancia ešte neexistuje, najskôr ju vytvorí.
Singleton využívame napríklad v prípade, že potrebujeme nejaké globálne nastavenia, ktoré majú byť zdieľané a viditeľné v celej aplikácii,
môže ísť o nejaké globálne počítadlo, či štatistiky, debugovací, či logovací komponent. V niektorých prípadoch sa môže hodiť, ak singleton
je súčasťou nejakého frameworku a aplikácia si definuje svoju vlastnú verziu, odvodenú od singletonovej triedy, v takom prípade sa na
vytváranie jeho inštancie často používa factory method namiesto konštruktora.
5.2. Structural Patterns
Druhá skupina návrhových vzorov rieši rozličné situácie v návrhu, kde sa z jednotlivých objektov a tried formujú zložitejšie štruktúry,
ktoré ale majú nejaký zaužívaný účel, formu, či vlastnosti.
5.2.1. Adapter
Convert the interface of a class into another interface clients expect. Adapter lets classes work together that couldn't
otherwise because of incompatible interfaces.
Tento bežný návrhový vzor (tiež nazývaný Wrapper) potrebujeme vždy vtedy, keď potrebujme využiť nejakú existujúcu knižnicu, framework,
alebo implementáciu, ale trieda, ktorá v nej poskytuje potrebnú funkcionalitu má iný interfejs, ako v našom prípade má mať. Preto
impelementujeme "obaľovaciu" triedu, ktorá nič nerobí, len prekladá formát volaní z jedného interfejsu na druhý.
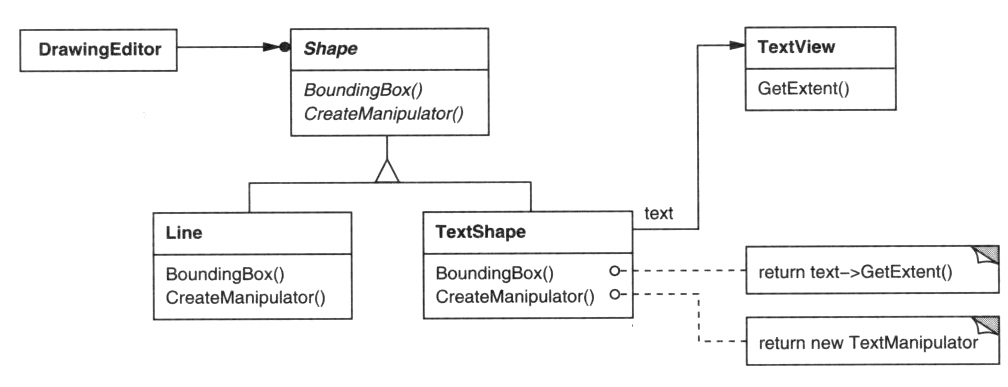
Obr. 52: Príklad použitia návrhového vzoru Adapter.
V príklade chceme využiť existujúcu triedu TextView, aby sme ju zaradili do kresliaceho editora, ktorý vyžaduje, aby všetky
nakresliteľné prvky spĺňali predpis definovaný abstraktnou triedou Shape. Hoci TextView obsahuje väčšinu potrebnej funkcionality,
metódy majú iné názvy. Napríklad metóda GetExtent() vráti obdĺžnik, v ktorom sa textový element nachádza a mala by sa volať
BoundingBox(). Preto vytvoríme adaptér TextShape, ktorý bude "obalovať" inštanciu triedy TextView:
jeho metóda BoundingBox() len prepošle výsledok metódy GetExtent(). V komplikovanejšom prípade by formát dát mohol byť iný (napr. relatívna
pozícia namiesto absolútnej) a adapter by musel preposielané údaje aj nejakým jednoduchým spôsobom transformovať. Naopak, niektorá
funkcionalita v obalovanej triede nemusí byť vôbec prítomná a úlohou adaptéra je doplniť ju - v tomto prípade pridáva metódu CreateManipulator()
a samostatnú triedu TextManipulator, ktorá potrebnú funkcionalitu dopĺňa.
5.2.2. Bridge
Decouple an abstraction from its implementation so that the two can vary independently.

Obr. 53: Problematická situácia, ktorá vedie k použitiu návrhového vzoru Bridge.
Za návrhovým vzorom Bridge sa skrýva pomerne komplikovaný, ale o to zaujímavejší koncept. Vysvetlime si to na nasledujúcom príklade.
Predstavme si knižnicu pre programovanie používateľského rozhrania, ktorá chce byť prenositeľná na rôzne platformy a mala by fungovať v rozličných
okienkových systémoch. Túto platformovú prenositeľnosť môžeme dosiahnuť napríklad pomocou generalizácie - aplikácia bude používať
abstraktnú triedu Window a každá okienková platforma zadefinuje svoju podtriedu (napr. XWindow, WPFWindow a pod.) Aplikácia potom
bude vytvárať inštanciu príslušnej podtriedy a pracovať s ňou pomocou univerzálneho typu Window.
Toto riešenie (bez použitia nejakej abstract factory) prináša problém, lebo náš kód, ktorý bude knižnicu využívať, bude predsa len
platformovo závislý (vytvára predsa inštanciu konkrétnej podtriedy), ale čo horšie, ak sa knižnica bude rozrastať a bude chceť
vytvárať rôzne špecializačné podtriedy triedy Window - napr. triedu IconWindow, ktorá slúži trebárs na vizualizáciu ikoniek vo forme
okienok, narazíme na ťažkosti. V tomto prípade bude od triedy Window odvodená trieda IconWindow, lenže, aby sme dosiahli prenositeľnosť na platformy, každá
platforma bude musieť definovať aj svoju podtriedu triedy IconWindow (XIconWindow, WPFIconWindow). Pridanie ďalšej platformy si vyžiada
pridanie tried pre každý typ okna... To už vedie k pomerne nepraktickému organizovaniu kódu.
Myšlienka návrhového vzoru Bridge je vytvorenie dvoch paralelných hierarchií - jedna bude riešiť otázku platformy, ale ponúkne dostatočnú
sadu elementárnych operácií tak, aby bolo možné vytvárať podtriedy v druhej hierarchii, ktorá už bude od implementácie celkom nezávislá a bude
sa týkať iných aspektov - okienko pre ikonky, dočasné okienko (transient) a pod. Nasledujúci obrázok zachytáva triedny diagram pre opísaný príklad.

Obr. 54: Príklad použitia návrhového vzoru Bridge.
Na pravej strane je hierarchia implementácií pre rozličné okienkové systémy. Abstraktná trieda WindowImp obsahuje všetky potrebné elementárne
operácie, ktoré sú platformovo špecifické. Ostatná funkcionalita frameworku si vytvára vlastnú - platformovo nezávislú hierarchiu, pričom
trieda Window bude len obsahovať referenciu na príslušnú práve využívanú implementáciu.
5.2.3. Composite
Compose objects into tree structures to represent part-whole hierarchies. Composite lets clients treat individual objects and
compositions of objects uniformly.
Tento návrhový vzor je veľmi zrozumiteľný - ide o vytvorenie stromovej štruktúry. Typickým príkladom je grafický editor, kde používateľ
môže kresliť elementárne tvary (kružnica, čiara, obdĺžnik, text), ale editor mu zároveň dovoľuje vytvárať tvary nové, ktoré vznikajú
zoskupovaním existujúcich označených tvarov (funkcia "group"). Takto vytvorené tvary sa zasa správajú ako elementárne a používateľ ich
ďalej môže zoskupovať do väčších tvarov. Vzniká stromová štruktúra obsahujúca elementárne tvary a ich zoskupenia. Triedny diagram
pre opísanú situáciu je zobrazený na nasledujúcom obrázku.
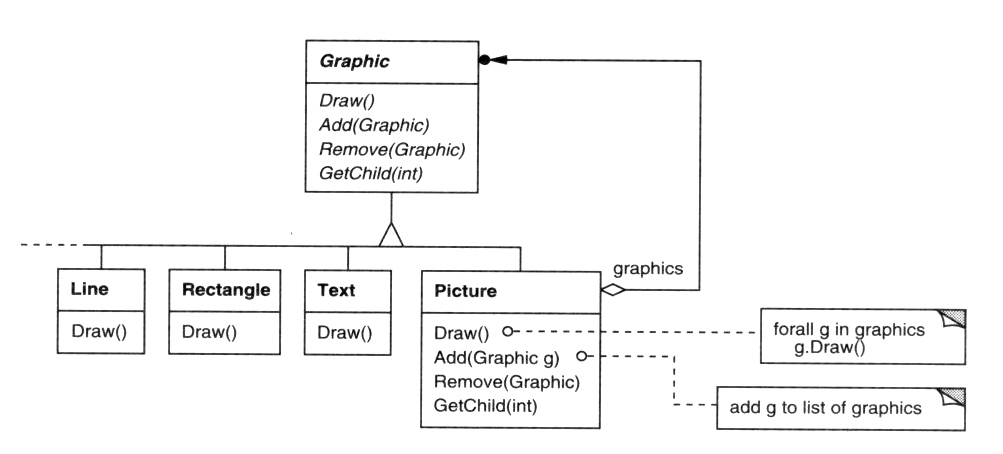
Obr. 55: Príklad použitia návrhového vzoru Composite.
5.2.4. Decorator
Attach additional responsibilities to an object dynamically. Decorators provide a flexible alternative to subclassing for
extending functionality.
Návrhový vzor Decorator je nádhernou ukážkou obmedzení vytvárania hierarchií tried v OOP a príkladom ako sa s nimi dá vysporiadať
iným spôsobom.
Predstavme si ešte raz framework pre okienkový systém, ktorý umožňuje aplikáciám vytvárať pekné GUI a poskytuje na to sadu
tried. Napríklad poskytuje triedu TextView, možno aj triedu ImageView, CalendarView, alebo MapView a podobne. Každá z nich
vytvára okienko s nejakým špecifickým obsahom, ktorý je možné zobraziť pomocou metódy draw(), ako to predpisuje ich spoločná
abstraktná nadtrieda VisualComponent. Neskôr sa autori frameworku rozhodnú pridať k textovému okienku scrollbar
a tak vytvoria podtriedu TextViewWithScrollBar. Táto trieda bude tiež definovať prekrývajúcu metódu draw(), ktorá (zjedodušene povedané)
najskôr nakreslí obsah okienka pomocou super.draw() a potom dokreslí scrollbar. Lenže, samozrejme, ak chcú pridať scrollbar
aj k ostatným typom okienok, tak budú musieť vyrobiť aj podtriedy ImageViewWithScrollBar, CalendarViewWithScrollBar atď.
čo je pomerne nepraktické a zrejme vznikne veľa duplicít. Ešte horšie to začne byť, keď okrem scrollbaru budeme chcieť
pridať špeciálny rámček (TextViewWithBorder), alebo toolbar (TextViewWithToolbar) a nebodaj ešte aj rozličné kombinácie
- so scrollbarom aj toolbarom, s toolbarom a rámčekom atď.
Návrhový vzor Decorator je recept na takéto a podobné situácie. Dovoľuje k existujúcim triedam pridať funkcionalitu oveľa
praktickejším spôsobom: pomocou relácie agregácie. Dobre si pozrite navrhované riešenie na nasledujúcom obrázku:

Obr. 56: Príklad použitia návrhového vzoru Decorator.
V hornej časti je objektový diagram (znázorňuje objekty v pamäti počas behu aplikácie), v dolnej časti triedny diagram (zobrazuje len
vzťahy medzi typmi). Abstraktná trieda Decorator "zastrešuje" všetky typy dekorátorov - čiže tried, ktoré pridávajú určitý typ funkcionality.
Príkladom je ScrollDecorator, ktorý pridáva scrollbar a BorderDecorator, ktorý pridáva rámček. Od pôvodnej triedy, ktorej funkcionalita
je rozširovaná (napr. TextView), nie je odvodená podtrieda - ako sme popisovali vyššie a ako by bolo v OOP bežné.
Namiesto toho dekorátor obsahuje referenciu
na inštanciu, ktorej funkcionalitu rozširuje (premenná component v triede Decorator). Zmena je len malinká - namiesto toho, aby
sa volalo super.draw() sa z Decorator.draw() volá component->Draw(). Čiže aby sa nakreslil obsah okienka sa nezavolá zdedená
verzia draw(), ale trieda draw() komponentu, ktorý práve dekorátor "obaľuje". Príslušná prekrývajúca metóda draw() daného dekorátora
potom dokreslí potrebnú pridanú časť (napr. scrollbar). Obrovskou výhodou je, že v premennej component nemusí byť len TextView, ale
môže tam byť ľubovoľný iný VisualComponent! Takto môžeme jedným ScrollDecoratorom pridať scrollbar podľa potreby ľubovoľnému okienku
nielen TextView. A čo viac, dekorátory môžeme kombinovať navzájom, pretože Decorator je sám tiež VisualComponentom, takže ho iný
decorator môže "obaliť" ďalšou funkcionalitou. Táto situácia je zobrazená v objektovom diagrame hore: objekt aTextView, ktorý je
triedy TextView je časťou objektu aScrollDecorator a spolu vytvárajú textové okienko so scrollbarom a ako celok tvoria VisualComponent,
ten je naďalej časťou objektu aBorderDecorator triedy BorderDecorator.
Veľmi dôležité je uvedomiť si tu, že funkcionalita, ktorú decorátor pridáva, vôbec nemusí byť o grafike, alebo o GUI. Naopak,
môže to byť ľubovoľná funkcionalita pridaná k nejakej existujúcej triede. Typickým príkladom sú vstupné a výstupné streams v jazyku Java.
Trieda InputStream, ktorá dokáže prečítať iba jeden znak metódou read() môže byť obalená dekorátorom ObjectInputStream, ktorá
dokáže na jedno volanie načítať celý serializovaný objekt. ObjectInputStream je ale len dekorátorom nad nejakým iným InputStreamom,
či už je to FileInputStream, SocketInputStream, StringBufferInputStream, alebo iný.
5.2.5. Facade
Provide a unified interface to a set of interfaces in a subsystem. Facade defines a higher-level interface that
makes the subsystem easier to use.
Hoci dom často ukrýva na svojom hospodárskom dvore všeličo, hostia do neho vstupujú cez
malebnú fasádu.
Návrhový vzor Facade je malebnou fasádou nejakého rozsiahlejšieho systému, alebo jeho časti, cez ktorú vstupuje väčšina iných komponentov,
ktorí vystačia s bežným použitím jeho funkcionality.
Príkladom môže byť knižnica, ktorá zabezpečuje funkcionalitu kompilátora nejakého programovacieho jazyka. Pozostáva z viacerých častí
- napr. scanner, parser, typový analyzátor, abstraktný syntaktický strom a podobne, ale pri bežnom použití kompilátora tieto vnútorné
komponenty nie je potrebné oslovovať priamo. Vstupná brána do knižnice umožňuje kompilátoru poslať zdrojový kód na skompilovanie a vráti
program reprezentovaný vo vykonateľnej podobe. Niektoré špecifické aplikácie môžu potrebovať komunikovať s jednotlivými komponentami
priamo - nad rámec rozhrania, ktoré poskytuje fasáda, čo je v prípade potreby tiež možné.
Iným príkladom je dnes populárna microservices architektúra, kde systém poskytuje viacero rozličných služieb, ktoré sú distribuované na rôznych výpočtových uzloch. Pre klientský softvér, ktorý k takejto sade služieb pristupuje externe, je pohodlnejšie ak je zriadená vstupná brána, ktorá presne eviduje na ktorých uzloch sú práve príslušné služby inštalované a dostupné. Niečo podobné zabezpečujú napríklad technológie
Zuul od Netflixu a Spring Cloud Gateway.

Obr. 57: Schématický obrázok porovnávajúci systém "bez fasády" a výsledok po aplikovaní návrhového vzoru Facade.
5.2.6. Flyweight
Use sharing to support large numbers of fine-grained objects efficiently.
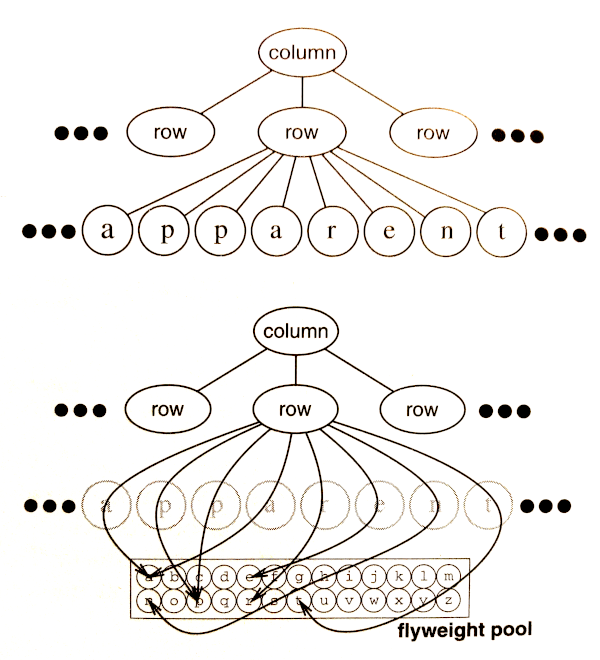
Obr. 58: Situácia, ktorá vedie k využitiu návrhového vzoru Flyweight: znaky v dokumente chceme reprezentovať objektami, ale majú veľa spoločných vlastností, preto na rovnaký znak použijeme ten istý objekt.
V niektorých systémoch sa určité typy objektov vyskytujú vo veľkom množstve. Pritom, určité vlastnosti majú všetky
objekty daného typu spoločné a v niektorých sa líšia. Ak spoločné vlastnosti zdieľané skupinou objektov vytiahneme
von do samostatného zdieľaného objektu (ktorý sa označuje Flyweight),
tak môžeme potenciálne ušetriť množstvo zdrojov. Pri vytváraní nového objektu sa vždy zistí, či už zodpovedajúci
flyweight existuje, alebo nie. Ak nie, tak sa vytvorí a zaradí sa do "poolu" aktívnych flyweights, inak iba použije
referencia na existujúci flyweight z poolu. Flyweighty v pooli
nedokážu vykonať väčšinu operácií samostatne, pamätajú si len tzv. intrinsic state - informácie spoločné pre všetky
objekty, ktoré príslušný flyweight zdieľajú a ten nestačí. Preto tieto operácie dostávajú zvyšné údaje
(nezdieľané, extrinsic state) vo svojom argumente (pozri metódu Operation(extrinsicState) na obrázku).

Obr. 59: Triedny a objektový diagram pre štruktúru návrhového vzoru Flyweight.
5.2.7. Proxy
Provide a surrogate or placeholder for another object to control access to it.
Proxy alebo zástupca je objekt, ktorý slúži ako náhrada pre skutočný objekt. Dôvody, prečo chceme použiť náhradu môžu
byť veľmi rôzne. Proxy je vo väčšine vlastností neodlíšiteľný od skutočného objektu, ale v niečom sa líši - niečo pridáva,
upravuje, vylepšuje, mení. Príkladom proxy je objekt, ktorý môžeme použiť namiesto obrázka zaradeného do dokumentu.
Úlohou objektu je daný obrázok udržiavať, ale napr. pri otvorení dokumentu, alebo nejakej stránky, keď je potrebné
rozsiahly obrázok načítať zo súboru alebo počítačovej siete, by sme potrebovali, aby sa nezdržovalo čakaním
na úplné načítanie a zobrazenie obrázka. Namiesto toho sa použije proxy, ktorý sa postará, aby sa obrázok natiahol
a zobrazil hneď ako to bude možné, ale metóda, ktorý tento objekt vytvorila nemusí čakať. Postará sa o to proxy.
Iný príklad použitia proxy môže byť logovanie prístupu k nejakému objektu, prípadne obmedzenie takéhoto prístupu
podľa privilégií. Príklad na obrázku zobrazuje triedu ImageProxy, ktorá vie vrátiť rozmery obrázka bez toho,
aby bol obrázok načítaný. V prípade, že obrázok nebude treba nikdy zobraziť (napr. sa nachádza v neviditeľnej
časti dokumentu za hranicou displeja), tak nikdy nebude načítaný a ušetria sa zdroje. Ak bude vyžadovaný samotný
obsah obrázka, tak až v tom čase sa načíta zo súboru.

Obr. 60: Príklad využitia návrhového vzoru Proxy.
5.3. Behavioral Patterns
5.3.1. Chain of Responsibility
Avoid coupling the sender of a request to its receiver by giving more than
one object a chance to handle the request. Chain the receiving objects
and pass the request along the chain until an object handles it.
V mnohých aplikáciách komponenty reagujú na udalosti, ktoré vznikajú v iných komponentoch.
Vtedy je vždy potrebné vytvoriť mechanizmus na odovzdanie notifikácie komponentom,
ktoré na udalosť chcú reagovať. Jednou možnosťou je priama notifikácia:
ak komponent vie, ktoré všetky komponenty má pri tej-ktorej udalosti
notifikovať, môže napríklad zavolať ich dohodnutú metódu.
Často to tak nie je. V čase návrhu komponentu, kde udalosť vzniká,
nie je známe, v ktorých komponentoch sa bude spracovávať.
Môže sa to aj dynamicky meniť, v závislosti od toho, kde a ako
sa príslušný komponent používa. Napríklad, predstavme si
systém na riešenie porúch. Jednotlivé servisné prvky systému dokážu
riešiť rôzne druhy porúch, ale vopred to nie je dané, priebežne
pribúdajú nové servisné prvky, alebo nahrádzajú staré.
Keď vznikne porucha - informácie o nej sa zabalia
do objektu reprezentujúcu poruchovú udalosť a pošlú sa prvému
prvku v reťazi, ten posúdi, či poruchu vie vyriešiť úplne, čiastočne,
alebo vôbec. V posledných dvoch prípadoch prepošle udalosť ďalšiemu
prvku v reťazi. V inom príklade si predstavme
dialógové okno, v ktorom je viacero ovládacích prvkov rozložených
do hierarchickej štruktúry - panely, podpanely, skupiny rádiobuttonov
a pod. Pri kliknutí myši potrebujeme, aby na túto udalosť zareagoval
ten správny komponent, na ktorý sa kliklo. Podobne, ak je časť
dialógového okna dočasne zakrytá a po odkrytí sa má znovu
aktuálne nakresliť - netreba kresliť celé okno, ale len tie
podčasti, ktoré majú prienik s oblasťou, ktorá sa má prekresliť.
Postupnosť komponentov vytvorí reťaz, cez ktorú sa udalosť o kliknutí/prekreslení oblasti bude postupne preposielať, až kým nedosiahne ten komponent,
ktorý sám vie, že má udalosť spracovať.
V takýchto situáciách potrebujeme nejaký univerzálny mechanizmus
na doručovanie notifikácií o udalostiach.
Návrhový vzor Chain of Responsibility rieši takéto prípady.
Všetky komponenty, ktoré majú záujem spracovávať udalosti z nejakého
zdroja, sú zoradené v reťazi "handlerov". Zdroj, ktorý notifikáciu
o udalosti generuje, má len referenciu na prvý handler v reťazi.
Ten udalosť buď spracuje, alebo ju pošle ďalšiemu handleru v reťazi.
Hovoríme, že notifikácia nemá explicitný (zreteľne uvedený) cieľ,
ale má len implicitného adresáta (takého, čo vyplynie z aktuálne
platnej reťaze handlerov). Handler sa môže rozhodnúť, či udalosť
spracoval kompletne, alebo či na ňu síce nejak zareaguje, ale
pošle ju aj ďalším handlerom v reťazi, alebo či sa ho netýka
a iba ju pošle ďalej. V princípe sa môže stať,
že na niektoré udalosti žiaden handler nezareaguje - je na
návrhu a implementácii, aby boli všetky potrebné prípady pokryté
korektne. Návrhový vzor nepredpisuje, či sa reťaz handlerov
má vytvoriť pomocou novo-zadefinovaných referencií (ako ukazuje
obrázok nižšie), alebo či sa využije už nejaká existujúca hierarchická
štruktúra handlerov - ako by to mohlo byť v prípade hierarchických
grafických ovládacích prvkov v dialógovom okne.

Obr. 61: Štruktúra návrhového vzoru Chain of Responsibility.
5.3.2. Command
Encapsulate a request as an object, thereby letting you
parameterize clients with different requests, queue or log
requests, and support undoable operations.
Ako sme uviedli v predchádzajúcom, princípy OOP vychádzajú
z myšlienky dekompozície na základe dát, čiže informácií.
Údaje, ktoré prirodzene patria spolu vytvárajú uzavreté
štruktúry dát - objekty.
V niektorých situáciách môže byť takouto informáciou (dátami) aj
inštrukcia (príkaz). To je aj prípad návrhového vzoru
Command, kde objekt triedy Command nesie informáciu o tom,
aký príkaz sa má vykonať, resp. sa už vykonal. To nám umožňuje
generovať požiadavky na vykonanie príkazov bez toho, aby
sme vedeli o aké príkazy ide, alebo evidovať zoznam vykonaných
príkazov počas nejakej postupnosti príkazov (session).
Predstavme si framework na vytváranie používateľského menu.
Tento framework by mal aplikácii dovoliť pohodlne konfigurovať
priradenie príkazov k jednotlivým položkám menu. Namiesto
toho, aby sme to realizovali cez nejaké číselné kódy príkazov
a potom v dlhej podmienke v štýle switch...case... rozlíšili
podľa čísla o aký príkaz ide, môžeme frameworku priamo posunúť
inštanciu nejakej podtriedy triedy Command, ktorá bude
implementovať metódu execute(). Po zvolení zpodpovedajúcej
položky menu framework zavolá metódu execute() nášho objektu
a tá zabezpečí že sa vykoná požadovaný príkaz. Ak by sme
do rozhrania pridali aj metódu undo(), postupnosť vykonávaných
príkazov by framework mohol evidovať (história operácií)
a po požiadavke používateľa
na vykonanie kroku späť (undo), prípadne viacnásobného
návratu (undo-undo-undo...) by sa len volali metódy undo()
na objektoch zodpovedajúcich príkazom vykonaným v predchádzajúcich
krokoch. Podobne by sme mohli pridať redo(), aby sa dalo
v histórii presúvať oboma smermi.

Obr. 62: Príklad využitia návrhového vzoru Command vo frameworku na vytváranie použivateľského menu
Skombinovaním vzoru Command so vzorom Composite je možné vytvárať makrá.
5.3.3. Interpreter
Given a language, define a representation for its grammar
along with an interpreter that uses the representation to
interpret sentences in the language.
Na chvíľu urobme malú nepovinne-informatívnu odbočku do teoretickej
informatiky - ak sa čitateľ ešte nestretol s formálnymi gramatikami,
súrodencami formálnych automatov.
Jazyk je nejaká množina
slov,
ktoré sú postupnosťami
symbolov z
abecedy, množiny
povolených symbolov.
Napríklad, nech abeceda pozostáva iba z jedného symbolu
Σ1 = {a}.
Jazyk
L1, ktorý obsahuje všetky možné slová vytvorené z párneho počtu
symbolov
a (skrátene môžeme zapísať
L1 = {a2n; n > 0}), sa dá
vygenerovať takouto gramatikou:
γ => aa
γ => aaγ
Ako vidíme, gramatika používa aj iné symboly ako sú v abecede,
sú to pracovné symboly z abecedy
Γ1 = {γ} (tzv. neterminálne symboly),
ktoré sa môžu počas budovania slov jazyka využiť, ale nakoniec sa
musia zmeniť na terminálne symboly z gramatiky
Σ1, iba také sa môžu vyskytovať v slovách jazyka.
γ je počiatočný symbol, z ktorého začína odvádzanie každého slova.
V každom kroku odvodenia použijeme jedno z pravidiel gramatiky,
čím nahradíme nejaký neterminál na ľavej strane pravidla reťazcom
na pravej strane pravidla. V našom prípade teda druhé pravidlo
vygeneruje o jedna menej dvojíc symbolov
a, ako je potrebný počet a nakoniec
sa neterminál
γ zmení prvým pravidlom na dvojicu symbolov
a.
Podobne by sme pre abecedu
Σ2 = {a,b} a jazyk
L2 = {anbm; n,m > 0} mohli napísať gramatiku:
γ => aγ
γ => aβ
β => bβ
β => b
Zaujímavejšie to začne byť napr. pri jazyku
L3 = {anbn},
obsahujúcom všetky slová pozostávajúce z nejakého počtu symbolov
a na začiatku
slova nasledovaných rovnakým počtom symbolov
b. Tento jazyk sa už
takouto
gramatikou vygenerovať nedá. Pod
takouto máme na mysli
regulárne gramatiky,
kde na ľavej strane môže byť iba jeden neterminál
a na pravej strane môže byť buď jeden terminál, alebo jeden terminál a jeden
neterminál. Regulárne gramatiky majú rovnakú vyjadrovaciu silu ako konečné stavové automaty
- množina jazykov, ktoré generujú, resp. rozpoznávajú je rovnaká (poteším sa, keď sa zamyslíte
nad tým, prečo je to tak). Pre
L3 môžeme
zostrojiť gramatiku:
γ => aγb
γ => ab
takáto gramatika je bezkontextová - čo znamená, že na ľavej strane je vždy práve
jeden neterminál. Aj takáto gramatika naráža na svoje hranice, napr. jazyk
L4 = {(a*b*)*, počet symbolov
a, b je rovnaký} - čiže jazyk,
v ktorom sú všetky slová s ľubovoľne pomiešanými symbolmi
a, b, ale zastúpené
v rovnakom počte, napr.
abbbaa, babbbaaa, baba. Tu si môžeme pomôcť frázovou
gramatikou, ktorá dovoľuje aj na ľavej strane pravidla viac ako jeden neterminál:
γ => αγβ
γ => αβ
αβ => βα
α => a
β => b
prvé dva riadky vygenerujú jazyk so slovami s neterminálmi vo formáte
αnβn
a tretí riadok dovolí symbolom
β
podľa potreby predbehnúť symboly
α, nakoniec sa všetky neterminály
α, β
zmenia na
a, b.
Gramatiky podľa svojej vyjadrovacej sily tvoria tzv. Chomského hierarchiu (regulárne -> bezkontextové -> kontextové -> frázové).
Frázová gramatika generuje jazyk, ktorý je rozpoznateľný nejakým Turingovým strojom (sú to ekvivalentné formalizmy).
Pre iniciatívneho čitateľa so záujmom o prémiové body ponúkame na precvičenie nasledujúce príklady:
- vytvorte čo najjednoduchšiu gramatiku pre generovanie anglických viet v nasledujúcich formátoch: Podmet prísudok, Podmet prísudok prísl.určenie, Prívlastok podmet prísudok prísl.určenie, kde podmet môže byť John, Student, Man, Box, prísudok môže byť works, sits, looks, stands, prívlastok môže byť foreign, nice, busy, crazy a príslovkové určenie môže byť safe, high, low, late.
- čo najjednoduchšiu gramatiku pre jazyk {w=anbncn; n > 0}, napr. slová abc, aabbcc, aaaabbbbcccc
- ...pre jazyk {w=ai; i=2n; n >= 0}, čiže napr. a, aa, aaaa, aaaaaaaa, aaaaaaaaaaaaaaaa
- ...pre jazyk {w=axby; kde y > 0 je deliteľné
bezo zvyšku x > 0}, napr. abb, aaabbbbbbbbb, aabbbbbb
- ...pre jazyk {w={0..9}*; w je deliteľné 3}, napr. 3,6,9,12,15,123,309
Originálne riešenia (môžu byť aj v LaTeXu) nahrajte do zodpovedajúcej zostavy.
Hoci tu uvedené jazyky sú pomerne jednoduché, podobným spôsobom je možné zadefinovať aj gramatiku pre ľubovoľný
programovací jazyk, kde terminálmi sú jednotlivé kľúčové slová, operátory a ostatné syntaktické prvky jazyka.
Často sa pri tom používa
gramatika v štýle BNF.
Za týmito prvkami jazyka sa skrýva aj sémantika - aký majú reálny význam (napr. operátor + vykonáva sčítanie svojich argumentov).
V kontexte uvedenej vsuvky si predstavme nejaký jednoduchý špecializovaný jazyk - napr. na programovanie pohybov robotického
ramena pripojeného k vesmírnej stanici. Návrhový vzor Interpreter rieši tento druh situácie, pričom účelom interpretra
môže byť buď len sparsovanie programov zapísaných v jazyku a vybudovanie abstraktného syntaktického stromu (AST) k vstupnému
programu, za účelom ďalšej analýzy a spracovania, prípadne vykonania, alebo môže byť úlohou interpretra rovno zadaný program
aj vykonať. Pre danú gramatiku môžeme vybudovať hierarchiu tried zodpovedajúcich jednotlivým druhom pravidiel a pravidlám
ako takým. V prípade zložitejších gramatík sa odporúča radšej použiť externé nástroje na parsovanie.

Obr. 63: Príklad hierarchie tried pri použití návrhového vzoru Interpreter - objektová reprezentácia vyjadrujúca jedno pravidlo regulárneho výrazu "((cats|dogs) repeat) and raining".
5.3.4. Iterator
Provide a way to access the elements of an aggregate object
sequentially without exposing its underlying representation.
Iterator je jeden z najbežnejšie používaných návrhových vzorov, ktorý umožňuje postupne prechádzať cez všetky
prvky združené v nejakom objekte, ktorý združuje množinu prvkov. Podstatné je, že interface iterátora je univerzálny,
a použiteľný pre rozličné zbierky prvkov rôzneho typu. Dnešné moderné jazyky obsahujú zabudované
syntaktické štruktúry na automatické vytváranie a používanie iterátorov, ale v tomto prípade máme na mysli
používateľom definované agregované štruktúry, cez ktoré má zmysel potenciálne iterovať univerzálnym spôsobom nezávisle od vnúrornej reprezentácie objektu, ktorý interface iterátora spĺňa.
Iterator predpisuje operácie posunutia sa na nasledujúci prvok, prezretia aktuálneho prvku, test na koniec procesu
iterovania a prípadne reset na začiatočný prvok. Iterátor môže postupovať buď v náhodnom poradí, alebo podľa nejakého
operátora usporiadania.

Obr. 64: Štruktúra návrhového vzoru Iterator. V roli Aggregate je nejaký abstraktný interface pre kolekcie, v roli ConcreteAggregate je nejaká konkrétna kolekcia, napr. HashSet, ConcreteIterator je potom taký iterátor, ktorý dokáže prechádzať prvky toho konkrétneho HashSetu, pre ktorý bol vytvorený.
5.3.5. Mediator
Define an object that encapsulates how a set of objects
interact. Mediator promotes loose coupling by keeping
objects from referring to each other explicitly, and it lets you
vary their interaction independently.
Na dosiahnutie netriviálnej funkcionality pomocou OOP je vždy potrebné, aby viaceré
objekty navzájom interagovali a spolupracovali. Ak je táto interakcia "zadrôtovaná"
priamo v nich, vzniká množstvo závislostí, znižuje sa znovupoužiteľnosť a flexibilita.
Návrhový vzor mediátor odporúča vytvoriť samostatnú triedu, ktorej objekt
má na starosti koordináciu viacerých objektov, vďaka čomu medzi nimi nevznikajú
pevné väzby v čase návrhu - čiže sa môžu vyvíjať nezávisle na sebe. Mediator je
objekt, ktorý konfiguruje prepojenie objektov v danej konkrétnej situácii.
Príkladom môže byť dialógové okno, v ktorom je použitých viacero kontroliek
- tlačidlá, listboxy, editovacie okienka, textové popisy, obrázky a podobne.
Všetky tieto objekty ponúkajú univerzálny interface na prácu s nimi a jeden
objekt (mediátor) má na starosti správne skĺbenie ich funkcionality. Napríklad
dialógové okienko na výber fontu textu môže obsahovať zoznam fontov, výber
hrúbky písma (light, medium, bold, heavy), štýlu (normálny, kurzíva),
veľkosti v bodoch, možnosť úspornej šírky, obsahuje náhľad krátkeho textu
vo zvolenom štýle, ktorý sa automaticky aktualizuje pri akejkoľvek zmene
nastavenia. Niektoré fonty však neposkytujú všetky možnosti, takže
pri vybratí fontu v listboxe sa nedostupné možnosti automaticky skryjú.
Mediátor má na starosti komunikáciu s rozhraniami všetkých čiastkových
objektov dialógu a poskytuje jednoduchý interface na riadenie dialógu navonok.
Jednotlivé objekty sa na seba priamo neodkazujú, akúkoľvek interakciu
riešia cez mediátora.

Obr. 65: Príklad interakcie objektov využitím návrhového vzoru Mediator.
5.3.6. Memento
Without violating encapsulation, capture and externalize an
object's internal state so that the object can be restored to
this state later.
Hoci z princípov OOP vyplýva, že podrobnosti svojho vnútorného stavu
má objekt pred ostatnými objektami skrývať (enkapsulácia), niekedy
je vhodné, aby sme vnútorný stav objektu vedeli odložiť, uchovať
a neskôr v prípade potreby použiť na to, aby objekt svoj pôvodný
stav zrekonštruoval do podoby v čase uchovania jeho vnútorného stavu.
Takto získaný vnútorný stav sa označuje Memento. Od objektu sa
očakáva, že bude obsahovať metódu na získanie Mementa - odtlačku
jeho aktuálneho stavu a na nastavenie jeho stavu podľa odtlačku
získaného niekedy predtým. Celú situáciu obhospodaruje nejaký
iný objekt - Caretaker. Je znázornená v triednom diagrame na obrázku.
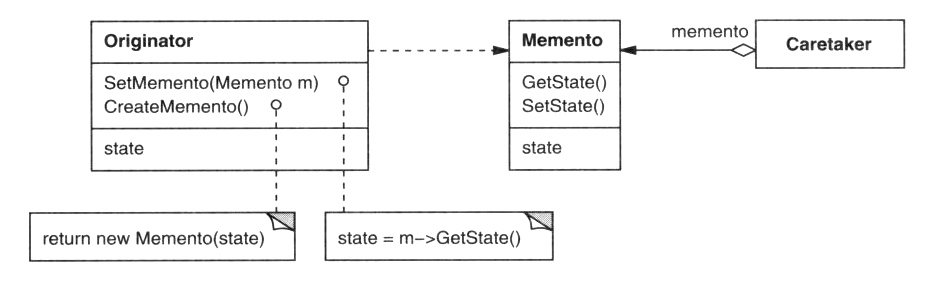
Obr. 66: Triedny diagram pre návrhový vzor Memento.
5.3.7. Observer
Define a one-to-many dependency between objects so that
when one object changes state, all its dependents are notified
and updated automatically.
Observer opisuje základný mechanizmus ako sa v systémoch založených na udalostiach šíria
notifikácie od zdroja udalosti, kde nastala zmena stavu, k objektom, ktoré sú na príslušnej
udalosti závislé. Návrhový vzor definuje univerzálny interface, pomocou
ktorého sa môžu objekty zaregistrovať ako odoberatelia notifikácií o zmene stavu
nejakého konkrétneho objektu. Objekt, ktorého zmena stavu je pozorovateľná,
musí splniť rozhranie Subject, s dvomi metódami Attach(Observer) a Detach(Observer),
pomocou ktorých sa ľubovoľný objekt spĺňajúci rozhranie Observer môže zaregistrovať.
Pozorovaný objekt (Subject) udržuje zoznam všetkých svojich observerov a v prípade,
že sa jeho stav zmení, notifikuje volaním Update() všetkých observerov. Situácia
je znázornená v triednom diagrame na obrázku. V niektorých prípadoch je vhodné
metóde Update() pridať aj argument - referenciu na objekt, ktorého stav sa zmenil.
To potom umožní, aby sa observer zaregistroval u viacerých subjektov a využíval
tú istú metódu Update(). V niektorých situáciách je vhodné, aby notifikácia nenastávala
po každej čiastkovej zmene, ale až po ukončení postupnosti za sebou nasledujúcich
zmien, preto treba pri implementácii Subjectu zvážiť, kedy a odkiaľ volať metódu notify(),
aby bol návrh efektívny a aby nedošlo k notifikáciám v okamihoch, keď stav nie je
konzistentný.
Samostatnú pozornosť si vyžaduje rušenie subjektov a observerov. Observer, ktorý je
rušený, by sa mal detach-núť zo všetkých subjektov, kde sa zaregistroval. Subject,
ktorý je rušený, by mal upovedomiť všetkých observerov, aby u nich neostali visieť
referencie na zrušený objekt. Notifikácia observerov môže obsahovať aj kompletnú
informáciu o zmenenom stave (push model), alebo len minimum informácií, pričom observer
si môže vyžiadať podrobnosti v prípade potreby (pull model). V prípade, že
stav subjektu je členitý, observeri sa môžu zaregistrovať len na notifikácie
o zmenách jednotlivých častí jeho stavu. Ak je sémantika notifikácií
zložitá, je možné pre ňu vyhradiť samostatný objekt, ktorý podrobne definuje
stratégiu notifikácií observerov (ChangeManager).
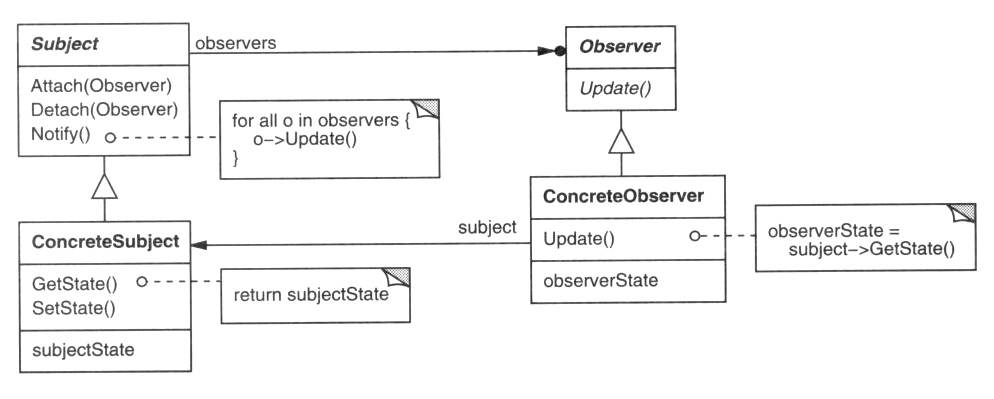
Obr. 67: Triedny diagram pre návrhový vzor Observer.
5.3.8. State
Allow an object to alter its behavior when its internal state
changes. The object will appear to change its class.
Návrhový vzor State je jednoduchý príklad na využitie polymorfizmu.
Predstavme si, že nejaký komponent A vie spracovať nejakú požiadavku
pričom na to využíva nejaký komponent B. Komponent A je trvácny a prijíma
požiadavky vždy rovnakým spôsobom, ale v závislosti od toho, v akom
kontexte sa systém práve nachádza, je potrebné na tú istú požiadavku
reagovať raz jedným spôsobom, inokedy iným spôsobom. Komponent B,
na ktorom sa požiadavka realizuje, sa teda v rozličných kontextoch
správa inak. Preto vytvoríme rôzne verzie komponentu B (budú to
rôzne podtriedy zastrešujúcej abstraktnej nadtriedy). V okamihu,
keď dôjde ku zmene kontextu, tak objekt v roli komponentu B vymeníme
- za inštanciu jeho sesterskej podtriedy.
Ako príklad si predstavme kresliaci editor, kde sa kurzor myši
vie prepnúť medzi tromi rôznymi režimami - posúvací, editovanie
detailov a pridávanie komentárov. Handler, ktorý spracováva
udalosť klinutia alebo ťahania myšou (komponent A), deleguje
spracovanie tejto udalosti príslušnému nástroju (komponent B),
ktorý sa mení podľa výberu režimu používateľom.
Iný príklad predstavuje objekt, ktorý zabezpečuje spojenie cez TCP sockety.
Toto spojenie môže byť z dôvodu šetrenia zdrojmi zdieľané medzi viacerými komponentami
a môže sa v danom okamihu nachádzať v rozličnom stave - nevytvorené, nadviazané, uzavreté, ...
Ak nový komponent požiada o otvorenie spojenia, akcia, ktorá sa v skutočnosti
vykoná, závisí od toho, v akom stave sa spojenie práve vtedy nachádza.
Pre každý možný stav TCP spojenia je vytvorená trieda. Využitím polymorfizmu
sa pri pokuse o otvorenie spojenia zavolá správna metóda open(), namiesto
toho, aby sme museli stav rozlišovať sériou podmienok testujúcich nejakú stavovú premennú.
Situácia je znázornená na obrázku.

Obr. 68: Príklad využitia návrhového vzoru State.
5.3.9. Strategy
Define a family of algorithms, encapsulate each one, and
make them interchangeable. Strategy lets the algorithm vary
independently from clients that use it.
Strategy je ďalší návrhový vzor založený na využití polymorfizmu a hoci jeho štruktúra je takmer identická ako pri návrhovom vzore State,
plní odlišný účel, podobný ako pri návrhovom vzore Builder. V tomto prípade nie je cieľom vybudovanie štruktúrovaného objektu
pomocou čiastkových operácií (ako pri vzore Builder), ale jednoducho abstrahovanie nad nejakým algoritmom, ktorý môže byť implementovaný
rozličnou stratégiou. Jednoduchým príkladom môže byť abstraktná trieda Sorter (rola Strategy) s metódou sort() a jej podtriedy BubbleSorter,
MinSorter, QuickSorter, MergeSorter (všekty sú v roli ConcreteStrategy). Niektoré triediace algoritmy zachovávajú poradie rovnakých
prvkov, iné nezachovávajú. Príklad: utrieďme zoznam dvojíc (3,3), (1,4), (3,2), (2,1) podľa prvého prvku v dvojici. Algoritmus zachovávajúci
poradie rovnakých prvkov musí vrátiť utriedený zoznam v poradí: (1,4), (2,1), (3,3), (3,2), hoci iný algoritmus, tiež korektne triediaci,
ale nezachovávajúci poradie rovnakých prvkov môže vratiť zoznam v poradí: (1,4), (2,1), (3,2), (3,3). V určitom kontexte potrebujeme
použiť napr. MinSorter, ktorý poradie zachová, hoci nie je taký rýchly ako QuickSorter, ktorý použijeme v kontexte, keď na zachovaní
poradia nezáleží, ale naopak potrebujeme rýchlu odozvu.
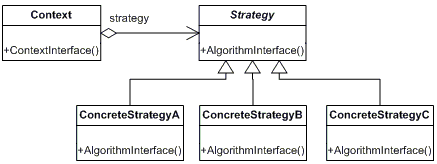
Obr. 69: Štruktúra návrhového vzoru Strategy.
5.3.10. Template Method
Define a skeleton of an algorithm in an operation, deferring
some steps to subclasses. Template Method lets subclasses
redefine certain steps of an algorithm without changing the
algorithm's structure.
V jednej zo zásad čistého kódu sa hovorí, že ak sa v našom zdrojovom kóde opakovane nachádzajú
podobné časti, tak kód ešte nie je dostatočne čistý. Zrejme sme nenašli nejaký spôsob abstrakcie,
ktorý dokáže spoločné časti podobných úsekov zjednodiť v abstraktnej podobe a vytvoriť dve
špecializácie, ktoré budú obsahovať len to, čím sa navzájom od seba odlišujú. Spôsoby vytvárania
takýchto abstrakcií sú veľmi rôznorodé a návrhový vzor Template Method je jeden z nich.
Myšlienka spočíva vo vytvorení spoločnej šablóny metódy v abstraktnej nadtriede (to je tá template method)
a zadefinovanie abstraktných metód v tejto abstraktnej triede, ktoré budú špecializované v každej
podtriede inak. Týmto pádom budú spoločné časti kódu uvedené len raz a vďaka polymorfizmu a generalizácii
sa odlišné časti doplnia v závislosti na tom, na akej konkrétnej inštancii sa daná šablónová metóda
zavolá.
Príklad, ktorého triedny diagram je zobrazený na obrázku, je o frameworku na vytváranie aplikácií
s dokumentami. Každá špecifická aplikácia si vytvára vlastnú podtriedu odvodenú od frameworkovej
triedy Application a definuje vlastný typ dokumentu odvodený od frameworkovej triedy Document.
Frameworková trieda Application obsahuje už naprogramovanú šablónovú metódu OpenDocument(),
ktorá vytvorí nový dokument a zaradí ho do zoznamu dokumentov príslušnej aplikácie. Táto metóda
sa najskôr pokúsi vytvoriť novú inštanciu, do ktorej sa dáta dokumentu načítajú a ak sa to
podarí, tak súbor s dokumentom otvorí a načíta ho do novo-vytvorenej inštancie. Na tieto jednotlivé
kroky využíva metódy, ktoré si aplikácia zadefinuje prekrytím abstraktných metód frameworkovej
triedy Application.
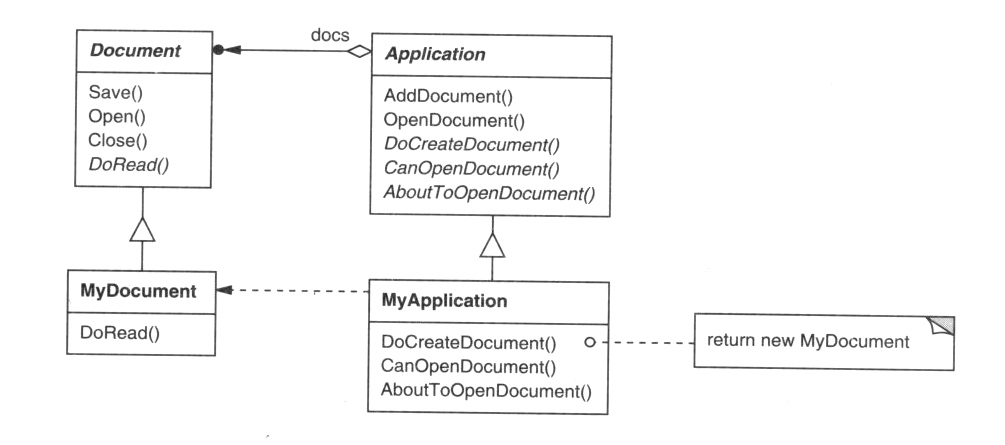
Obr. 70: Príklad využitia návrhového vzoru Template Method.
5.3.11. Visitor
Represent the operation to be performed on the elements of
an object structure. Visitor lets you define a new operation
without changing the classes of the elements on which it
operates.

Predstavme si stromovú adresárovú štruktúru súborov na disku, ktorá je načítaná v nejakom
štruktúrovanom objekte v pamäti. Tento objekt dovoľuje prechádzať cez danú štruktúru
univerzálnym spôsobom. Podľa typu položky zavolá rôznu metódu: v prípade, že položka
je typu podadresár, zavolá metódu spracujPodadresar(), ak ide o spustiteľný súbor,
zavolá spracujProgram() a inak zavolá spracujSubor(). Tieto metódy volá na nejakom
objekte v roli Visitor, ktorý určuje, čo sa na jednotlivých položkách má robiť.
Napr. ak naším cieľom je vypísať stromovú štruktúru na výstup, všetky metódy
budú vypisovať názvy položiek, prípadne vypočítavať odsadenie podľa úrovne vnorenia
do podadresárov. V prípade, že chceme len spočítať počet súborov v celej stromovej
adresárovej štruktúre, metódy spracujProgram() a spracujSubor() budú zvyšovať
interné počítadlo visitora.
Návrhový vzor Visitor teda umožňuje prechádzať položky nejakej zložitej
štruktúry s tým, že operácie, ktoré sa nad jednotlivými typmi položiek
majú vykonať, určí príslušná inštancia podtriedy spĺňajúcej rozhranie, ktoré
je pre visitora pre daný typ štruktúrovaného objektu predpísané. Visitor
má možnosť dané položky nielen čítať, ale ak je potrebné priamo do stromovej
štruktúry pristupovať a upravovať ich. Mohli by sme povedať, že ide o trochu
štruktúrovanejší iterátor.
Tento návrhový vzor sa typicky používa pri rôznych parseroch stromových alebo
sekvenčných štruktúr - napr. pri parsovaní XML dokumentov v jazyku Java EE
týmto spôsobom pracuje
SAX parser,
kde v roli visitora je ContentHandler.
Na obrázku je príklad využitia návrhového vzoru Visitor pri prechádzaní
cez syntaktické prvky nejakého programu. Visitor má zadefinované metódy,
ktorými spracováva rozličné syntaktické prvky - napr. jedna metóda
spracováva príkaz priradenia (VisitAssignment), iná spracováva odkaz
na nejakú premennú (VisitVariableRef). Program pozostáva z mnohých
prvkov (Node), ktoré sú inštancie špecializácií triedy Node a každá
z nich definuje metódu, ktorá má na starosti interagovanie s Visitorom
správnym spôsobom - t.j. napr. ak určitý Node reprezentuje príkaz
priradenia, tak visitora osloví vhodnou metódou VisitAssignment().

Obr. 71: Príklad využitia návrhového vzoru Visitor.
6. Integrácia aplikácií
S prudkým rozvojom informačných technológii v posledných dekádach 20. storočia nastalo
nekoordinované nasadzovanie špecializovaných informačných systémov na rôzne čiastkové úlohy
v mnohých organizáciách. Hoci aplikácie zjednodušili a zrýchlili prácu, čoskoro sa
narazilo na problém: aplikácie navzájom nespolupracujú. Rovnaké údaje boli často
uložené duplicitne vo viacerých systémoch, bežné procesy organizácie znamenali
použitie viacerých systémov a viacnásobné vypĺňanie rovnakých dát, činnosti, ktoré
by mohli byť plne automatizované, vyžadovali ručnú obsluhu, ktorá vstupy, výstupy
a akcie jedného systému iba koordinovala so vstupmi, výstupmi a akciami ostatných systémov.
Tento stav vo veľkej miere pretrváva dodnes a bude aktuálny vždy, pretože jednak
vyvinúť obrovský systém, ktorý rieši všetky potreby organizácie, je priveľmi nákladné
a ťažko realizovateľné a po druhé, všetko súvisí so všetkým, takže nejaký zmysel sa bude
dať nájsť v prepájaní takmer všetkých aplikácií vždy. Naviac, pri efektívnom riadení
organizácie si často na každý podproblém vyberáme najlepší dostupný nástroj,
namiesto jedného veľkého univerzálneho riešenia, ktoré trpí nedostatkami v každej
konkrétnej aplikácii. Iný príklad nutnosti integrácie aplikácií: dôjde k zlúčeniu
dvoch organizácií (akvizícia) a pravidlá jednej firmy, ktorá používala iný softvér,
zrazu začnú platiť cez celú spoločnosť.
Integrácia aplikácií teda znamená proces prepájania rozličných aplikácií tak,
aby mohli vzájomne spolupracovať na definovanej funkčnosti. Výsledkom je
integračné riešenie.
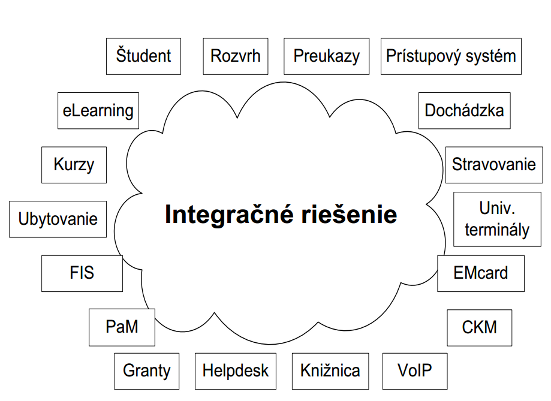
Obr. 72: Integračné riešenie.
Slovo integrácia ako také označuje proces začleňovania nejakej menšej jednotky do väčšieho
celku. Poznáme známe príklady integrácie krajiny do Európskej Únie, alebo iných medzinárodných
štruktúr, integrácia handicapovaných ľudí do bežnej spoločnosti, integrácia menšín do
spoločnosti. Vo všetkých prípadoch vidíme spoločnú črtu: integrácia si vyžaduje
úsilie jednak od menšej jednotky, ktorá sa integruje, ale podobne veľké úsilie sa vykonáva
aj na strane celku, do ktorého sa jednotka integruje. Napríklad v prípade integrácie
menšiny do spoločnosti bez úsilia väčšiny ide o asimiláciu, ktorej sa civilizovaná spoločnosť
snaží vyhnúť, pretože potiera práva začleňovanej menšiny.
Prepájanie aplikácií je netriviálny proces, pretože často nejde len o obyčajný export
a následný import do druhej aplikácie. Jednotlivé programy používajú rozličné dátové
modely - napr. v jednom môže byť meno a priezvisko uložené zvlášť, druhý obsahuje
len jeden atribút MenoPriezvisko. V jednom systéme môže atribút Adresa znamenať korešpondenčnú
adresu kontaktnej osoby organizácie, v druhom môže znamenať oficiálnu adresu organizácie,
s ktorou je zaregistrovaná na Štatistickom úrade SR. Rozdiely môžu spočívať napríklad
aj vo formálnej zodpovednosti za správnosť evidovaných údajov, ktorá sa nesmie porušiť
bez toho, aby sa nezmenili vnútorné predpisy organizácie.
Integrácia sa realizuje jednak úpravou existujúcich aplikácií (ak je to vôbec možné)
alebo vytváraním nových komponentov, ktoré komunikujú s jednotlivými aplikáciami.
Kľúčovým pojmom, okolo ktorého sa točí celá integrácia aplikácií, je tzv. voľná väzba,
v kontraste s pevnou väzbou. Rozlišujeme voľnú väzbu v čase návrhu a v čase behu.
Obr. 73: Voľná a pevná väzba v čase behu.
Voľná väzba v čase behu znamená, že integračné riešenie nevyžaduje, aby komunikujúce
aplikácie boli v činnosti súčasne. Voľná väzba v čase návrhu nevyžaduje, aby prepojené
systémy boli vyvíjané súčasne. Integračné riešenia s voľnou väzbou uprednostňujeme
pred tými, ktoré vyžadujú pevnú väzbu, keďže umožňujú väčšiu flexibilitu.

Obr. 74: Voľná a pevná väzba v čase návrhu.
Integrácia aplikácií je problematika, ktorá by si zaslúžila aj samostatný kurz, aby
sme do nej aspoň z časti nahliadli, zamerajme sa na klasifikáciu integrácie z troch
rôznych hľadísk: klasifikácia podľa A) poskytovanej funkčnosti, B) spôsobu komunikácie
s aplikáciami a C)vnútornej komunikácie v rámci integračného riešenia.
6.1 Klasifikácia integrácie podľa poskytovanej funkčnosti
Za integračné riešenie na nulovej úrovni by sme mohli považovať sekretárku, ktorá
sedí za počítačom s viacerými aplikáciami a najčastejšie klávesy, ktoré
používa sú ALT-Tab, CTRL-C a CTRL-V. Ak integračné riešenie poskytuje niečo viac,
tak hovoríme o integrácii prostredníctvom portálu, o agregácii dátových entít,
alebo o integrácii procesov.
Integrácia prostredníctvom portálu
Do všetkých aplikácií integračného riešenia sa používateľ prihlási na jeden raz.
Okná všetkých aplikácií vidí naraz na obrazovke (alebo sa medzi nimi jednoducho prepína).
V niektorých prípadoch sa informácie aj automaticky aktualizujú medzi jednotlivými aplikáciami.
Typické technológie, ktoré v takomto prípade využívame sú adresárové služby - napr. prostredníctvom
štandardu X.500. Prihlasovanie a aktualizácia používateľského profilu sa deje na jednom zdieľanom
serveri, ktorý využívajú všetky aplikácie. Isto ste sa už stretli s možnosťou prihlásiť sa
do nejakej aplikácie tretej strany pomocou vášho účtu pre aplikácie firmy Google (GMail a podobne).
Agregácia dátových entít
Toto riešenie ide ďalej a stará sa o vytvorenie jednotného pohľadu - dátového modelu, ktorý
čerpá z dátových modelov jednotlivých aplikácií. Jednotlivé polia výsledného modelu sú namapované
(s prípadnými úpravami po ceste) na novú dátovú entitu, ktorú definuje integračné riešenie.
Nové aplikácie, ktoré do integračného riešenia pridávame, sa môžu odkazovať na tieto nové dátové
entity, ktoré vznikli agregovaním (spájaním, zlučovaním) jednotlivých dátových entít.
V tomto prípade ale integračné riešenie ešte samostatne nevykonáva žiadne aktivity.
Integrácia procesov
V tomto prípade integračné riešenie samostatne vykonáva interakcie medzi aplikáciami, aby
zabezpečilo realizovanie stanovených požiadaviek. Napríklad vie vykonať mesačnú mzdovú
uzávierku pre všetkých zamestnancov tak, že z rôznych systémov zistí potrebné informácie:
koľko dní bol pracovník PN, na dovolenke a na pracovnej ceste, kedy nastúpil do zamestnania,
aké sú aktuálne platné tabuľkové mzdy, aká je jeho aktuálna kvalifikácia, či je členom odborov,
či má okrem bežnej mzdy príjem aj z nejakých projektových grantov, či si odkladá v druhom
a treťom pilieri na dôchodok, atď. a na základe toho vyráta jeho mesačnú mzdu, na koľko
stravných lístkov má nárok a aké sumy treba odviesť do rozličných poisťovní a tieto platby
aj realizuje bez toho, aby mzdová učtáreň tieto údaje musela do systému vkladať:
pracovnú dochádzku zadá sekretárka na jeho katedre do systému dochádzky, kvalifikáciu
a odpracované roky vypočíta systém personalistického oddelenia, informácie o projektoch zadá
centrum projektovej podpory, aktuálne tabuľkové mzdy sa vytiahnu zo systému ministerstva financií,
podrobnosti o dôchodkoch prídu každý mesiac automatickou správou zo sociálnej poisťovne a o členstve
v odboroch a aktuálnom odborárskom členskom odpovie informačný systém odborárov.
6.2 Klasifikácia integrácie podľa spôsobu komunikácie s aplikáciami
Na dosiahnutie spolupráce medzi aplikáciami musíme zabezpečiť, aby dokázali navzájom automaticky
komunikovať, hoci pôvodne s komunikáciou takýmto spôsobom nepočítali (ak áno, tak integračné
riešenie získame takmer "zadarmo" správnym nastavením konfiguračných súborov - čo je ideálny prípad).
S aplikáciou môžeme automaticky komunikovať na troch rôznych úrovniach: A) na úrovni aplikačnej logiky,
B) na úrovni perzistentných údajov, C) na úrovni používateľského rozhrania.
Komunikácia na úrovni aplikačnej logiky
Komunikácia na úrovni aplikačnej logiky znamená, že aplikácia poskytuje nejaký spôsob, akým
sprístupňuje svoju funkcionalitu a dáta automatickým spôsobom - že už tak vopred bola naprogramovaná.
Spôsobov existuje veľmi veľa, napríklad k aplikácii je pribalená dynamická knižnica a dokumentácia
jej funkcií (API), webová aplikácia môže definovať REST-ovské URL adresy, ktoré reagujú požadovanými
údajmi, akciami, aplikácia môže počúvať na nejakom TCP sockete a odpovedať na prijaté požiadavky,
alebo aspoň obsahuje povel na vygenerovanie exportu alebo načítanie importovaných údajov vo formáte
CSV, XML, alebo JSON.
Komunikácia na úrovni aplikačnej logiky je jednoznačne najlepší z uvedených troch prístupov,
najmä preto, že je podporovaný priamo autormi aplikácie, takže je oveľa menšia
pravdepodobnosť, že sa dopustíme nejakej chyby kvôli tomu, že nepoznáme vnútorné mechanizmy
aplikácie. Pri vydaní novej verzie systému môžeme očakávať menšie zmeny a prípadnú podporu
migrácie pre integrátorov ako je to v prípade používateľského rozhrania alebo databázy.
Spravidla tým máme k dispozícii automatickú validáciu správnosti vstupných údajov a autorizácie
(používateľ, ktorý by sa k určitým údajom nemal dostať sa k nim nedostane). Bežné systémy
na úrovni aplikačnej logiky vyžadujú pevnú väzbu, avšak existujú aj systémy s automatickou
odpoveďou cez e-mail, prípadne iné technológie s voľnou väzbou - napríklad Java Message
Service (JMS). Hlavnou nevýhodou komunikácie na úrovni aplikačnej logiky je to,
že často jednoducho nie je k dispozícii. Často nie sú k dispozícii ani zdrojové súbory aplikácie
alebo spoločnosť, ktorá systém vyvinula, už neexistuje.
Komunikácia na úrovni perzistentných údajov
Takmer každá aplikácia ukladá svoje údaje do nejakej všeobecne známej a podporovanej databázy,
ku ktorej po získaní prístupových údajov môže automaticky pristupovať aj integračné riešenie,
obídením pôvodnej aplikácie. Na jednej strane je toto riešenie efektívne - dotazy optimalizuje
databáza, môžeme prenášať veľké objemy dát, alebo robiť modifikácie priamo pomocou dotazovacieho
jazyka, máme k dispozícii všetky údaje v databáze. Na druhej strane integrátori nemusia
kompletne odhaliť dátový model a ľahko môžu porušiť integritu dát a pôvodnú aplikáciu tým
aj celkom znefunkčniť. K tomu môže dojsť veľmi ľahko, ak by sme chceli integračné riešenie
používať súčasne s pôvodnou aplikáciou, ktorá údaje môže dočasne odkladať do svojej lokálnej cache,
alebo zamykať prístup k záznamom. Ďalej strácame automatickú validáciu vstupov - do databázy môžeme
uložiť aj také údaje, ktoré pôvodný program ani nevie interpretovať, pokiaľ validácia nie je
implementovaná priamo v databáze. Nie je tiež správne, že obchádzame systém prístupových oprávnení,
lebo takto omylom môžeme dať prístup používateľom, ktorí by ho nemali mať (to je údajne napr.
prípad pôvodnej verzie knižnice Fajr, alternatívneho prístupu k údajom univerzitného AISu),
ktorý bol urobený práve tak, ako by sa integrácia aplikácií robiť nemala.
Komunikácia na úrovni používateľského rozhrania
Všetky aplikácie majú svoje používateľské rozhranie. Niektoré bežia na webe, takže vypĺňanie
formulárov určených pre bežného používateľa môžeme nahradiť priamymi automatickými HTTP requestami
typu POST, niektoré sa dajú ovládať z príkazového riadku (command line interface, CLI) a v najhoršom
prípade sa dá nahrať aj makro (resp. vytvoriť jeho ekvivalent), ktoré za nás automaticky kliká
na tlačidlá v dialógových oknách a vypĺňa editboxy. Výhodou je, že integračné riešenie takto
nemôže urobiť nič viac ako bežný používateľ, takže je zabezpečená integrita údajov a validácia
vstupov. Veľkou nevýhodou je nízka robustnosť - aj malá zmena používateľského rozhrania - napr. pri
dodaní novej verzie spôsobí problémy. Neočakávaná situácia, ktorá zobrazí informatívne dialógové
okno, alebo správu v príkazovom riadku tiež ľahko rozbije takéto integračné riešenie. Naviac
údaje musíme aplikácii prezentovať a interpretovať ako používateľ, čiže napr. konvertovať vypísané
pole reálnych čísel oddeľovaných čiarkami z textovej do binárnej podoby.
6.3 Klasifikácia integrácie podľa vnútornej komunikácie v rámci integračného riešenia
V tomto prípade sa zaoberáme vnútornou architektúrou integračného riešenia, ktorá môže využiť
široké spektrum rozličných architektúr informačných systémov. Jeden z podstatných atribútov
tejto architektúry ale je, či komunikácia v integračnom riešení prebieha A) synchrónne, alebo
B) asynchrónne.
Synchrónna komunikácia
V prípade synchrónnej, čiže súčasnej, koordinovanej komunikácie (zo starej Gréčtiny: syn:spolu,
chronos: časy), počítame s tým, že sa obe komunikujúce strany zapájajú do komunikácie v tom istom
čase, čím vzniká pevná väzba. Využívajú sa tu technológie ako RPC (remote procedure call),
RMI (remote method invocation), HTTP, CORBA (starší protokol na platformovo-nezávislú komunikáciu
aplikácií), alebo SOAP (protokol pre výmenu štruktúrovanej informácie). Takéto aplikácie často
využívajú všeobecný návrhový vzor SOA (Service-Oriented Architecture), a významnými parametrami
takejto služby sú potom: priemerná očakávaná doba medzi dvoma výpadkami (mean time between failures),
priemerná doba potrebná na opravu v prípade výpadku (mean time to repair/recovery). Takéto
parametre sa nastavujú v dohode medzi poskytovateľom služby a klientom (SLA=service level
agreement, dohoda o úrovni poskytovaných služieb).
Asynchrónna komunikácia
V opačnom prípade pripúšťame, že integračné riešenie sa postará o zabezpečenie spojenia a prenos
informácií aj vtedy, keď komunikujúce strany nie sú činné v rovnakom čase. Získavame voľnú väzbu.
Komunikácia sa väčšinou zabezpečuje posielaním správ cez komunikačné kanály, pričom môžeme
využiť buď architektúru založenú na decentralizovaných dátovodoch a filtroch (výhodné z hľadiska
dobrej modifikovateľnosti) alebo na centrálnom komponente, ktorý riadi komunikáciu cez všetky
dátové kanály.
7. Anotácie
V tejto kapitole sa spoločne pozrime na jednu technológiu využívanú pri vývoji informačných
systémov, ktorá získava na popularite: anotácie v zdrojových súboroch.
Stačí na naprogramovanie aplikácie poznať jeden programovací jazyk?
V minulosti platilo, že celá aplikácia sa
naprogramovala pomocou jedného jazyka a jednej technológie. Dnes to funguje zriedka.
Aplikácia potrebuje ukladať údaje do externej databázy, ktorá má vlastný dotazovací jazyk.
Aplikácia prezentuje informácie používateľovi na webovej stránke, vytvorenej v samostatnom
prezentačnom hypertextovom jazyku. Aplikácia komunikuje s inými aplikáciami využívajúc
kanály s platformovo-nezávislým protokolom. Vývojári navrhujú aplikácie a vytvárajú používateľské
rozhranie a dokumentáciu, pričom sa automaticky generujú zdrojové kódy, alebo naopak.
Na zjednodušenie prepojenia programu s uvedenými (a mnohými ďalšími) službami a nástrojmi sa v zdrojových kódoch objavujú nejaké "značky", resp. komentáre v dohodnutom
formáte, ktoré sú často nad rámec pôvodných vylastností programovacieho jazyka.
Takéto značky v zdrojových kódoch nazývame anotácie.
Sú inštrukciami pre externé nástroje alebo rozšírenia jazyka.
Automaticky rozširujú funkcionalitu vytváraného programu.
Napríklad v programovacom jazyku Java poznáme anotácie vo forme dokumentačných komentárov, ktoré
sa môžu umiestňovať pred definície identifikátorov (tried, metód, premenných...) a pomocou
automatického nástroja na generovanie dokumentácie API (javadoc) z nich vygenerovať technickú
dokumentáciu vo formáte HTML. Zdrojový kód metódy
java.lang.System.lineSeparator()
vyzerá takto:
/**
* Returns the system-dependent line separator string. It always
* returns the same value - the initial value of the {@linkplain
* #getProperty(String) system property} {@code line.separator}.
*
* On UNIX systems, it returns {@code "\n"}; on Microsoft
* Windows systems it returns {@code "\r\n"}.
*/
public static String lineSeparator() {
return lineSeparator;
}
a takto vyzerá výsledná
vygenerovaná HTML dokumentácia:

Ešte zaujímavejšie sú anotácie zapísané pomocou zavináča a nejakého identifikátora. Java
samotná pozná takéto anotácie, napríklad anotácia
@Override pred definíciou metódy
spracuj(String hodnota) znamená, že táto metóda prekrýva rovnakú metódu nejakej svojej
nadtriedy. Načo je to dobré? Jednak pri čítaní kódu programátor hneď vie, že v
nadtriede existuje rovnaká metóda a nemusí to kontrolovať v zdrojovom kóde nadtriedy.
Okrem toho: kompilátor program neskompiluje, ak
sme sa náhodou pomýlili a v prekrývajúcej metóde použili
argument typu
String
namiesto argumentu typu
int, ktorý je v prekrývanej metóde v nadtriede.
Bez tejto anotácie by bol program bez problémov skompilovaný,
lenže volanie
spracuj(6) by spôsobilo volanie metódy v nadtriede a možno by
sme si to ani nikdy nevšimli, len program by robil niečo iné, ako má. Anotácia
pomáha skontrolovať, že úmysel prekryť metódu nadtriedy sa naozaj podaril.
To ale stále nie je veľa, čo ešte @-anotácie dokážu? Veľmi veľa!
Príklad 1: automatické testovanie jednotkovými testami (JUnit).
Anotácia
@Test (a skupina ďalších anotácií, ktoré zavádza JUnit), umožňuje napísať kód, ktorý nie je
bežný program, ale obsahuje jednotkové testy určené na otestovanie nejakého iného nášho vytváraného programu. Vývojové prostredia
(ako napr. Eclipse, Netbeans) potom umožňujú spustiť jednotkové testy k nášmu vytváranému kódu bez
toho, aby sme si museli vyrábať vlastné testovacie skripty a v prípade zlyhania testov zobrazia
podrobný protokol. Jedným kliknutím sa vieme preniesť na miesto v programe, kde
test zlyhal. Príklad automatického JUnit testu:
import org.junit.*;
import static org.junit.Assert.*;
public class TestPolska
{
static double eps = 0.0000000001;
@Test
public void zoZadania()
{
String ex = "div sub div add div mul 6 4 3 1 3 2 2";
double v = Polska.vyhodnot(ex);
assertTrue("prvy priklad zo zadania" , eps > Math.abs(0.5 - v));
}
@Test
public void dalsie()
{
ex = "div div sub 10 7 add -5 7 div -1 -4";
v = Polska.vyhodnot(ex);
assertTrue("vysledok nesedi pre vstup '" + ex + "'", eps > Math.abs(6 - v));
}
}
Príklad 2: Mapovanie objektov v pamäti na relačnú databázu.
Relačné databázy vznikli v čase, keď objektovo-orientované programovanie neexistovalo, resp.
nepoužívalo sa.
Prečo sa volajú relačné databázy relačné? Pretože sú medzi tabuľkami vzťahy - relácie?
Nie preto. Tabuľka ako taká je relácia. Spomeňme si z diskrétnej matematiky, čo je to relácia!
Relácia
R na množine
A je podmnožinou karteziánskeho súčinu
A x A.
Relácia medzi množinami
A a
B bude pomnožinou karteziánskeho súčinu
A x B.
Takže tabuľka so zoznamom študentov s poliami
meno:string, ročník:int, odbor:string
je podmnožinou karteziánskeho súčinu
string x int x string, čiže množina trojíc
(meno, ročník, odbor), kde
meno je
string,
ročník je
int
a
odbor je
string.
Postupne síce vznikli aj objektovo-orientované databázy, ale veľmi sa neuchytili.
V praxi sa skôr používajú relačné databázy
a namapovanie objektov na ich tabuľky. V Jave EE (Enterprise Edition) to môžeme urobiť takto:
package daba.db;
import java.io.Serializable;
import javax.persistence.*;
@Entity
@Table(name = "AISStudent")
public class Student implements Serializable {
@Id
private Long ID;
@OneToOne(cascade = CascadeType.ALL) @MapsId("ID")
private Person person;
private String DIRECTION;
public Person getPerson() { return person; }
public static Student newStudent(String firstname,
String lastname,
long yearStarted,
String direction)
{
Student newst = new Student();
newst.person = Person.newPerson(firstname, lastname, yearStarted);
newst.DIRECTION = direction;
return newst;
}
public Long getId() { return ID; }
public void setId(Long id) { this.ID = id; }
public String getDirection() { return DIRECTION; }
public void setDirection(String direction) { this.DIRECTION = direction; }
// ...
}
Anotácia
@Entity robí z triedy
Student automaticky triedu, ktorej
inštancie (objekty) sa dajú ukladať do relačnej databázy ako záznam jednej
tabuľky, rovnako opačne - objekt sa dá jedným príkazom inicializovať z nejakého
záznamu uloženom v tabuľke. Anotácia
@Table túto triedu mapuje na konkrétnu
tabuľku v databáze (aj bez nej by však už bola namapovaná na tabuľku s rovnakým
menom - čiže
Student). Anotácia
@Id určuje, že premenná
ID
zodpovedá primárnemu kľúču tabuľky a túto hodnotu bude generovať priamo databáza pri uložení
nového záznamu, relácia
@OneToOne v kombinácií s premennou
person triedy
Person (ktorá je tiež
@Entity - a je namapovaná na inú tabuľku) umožňuje vytvoriť
automatické prepojenie viacerých databázových tabuliek reláciou one - to - one,
s tým, že vymazanie alebo vytvorenie záznamu v jednej tabuľke automaticky
vymaže alebo vytvorí záznam aj v druhej tabuľke. Premenná
DIRECTION je automaticky
namapovaná na rovnomenný stĺpec v tabuľke
AISStudent. V programe nám potom
stačí napísať:
objectToInsert = Student.newStudent("Janko", "Hraško", 2014, "AIN");
entityManager.persist(objectToInsert);
alebo:
Student s = (Student)entityManager.find(Student.class, personId);
entityManager.remove(s);
na vytvorenie nového alebo vymazanie záznamu, ale hlavná výhoda spočíva v tom,
že údaje načítané z databázy nemusíme nijak transformovať do našej internej
reprezentácie dát v pamäti, ale sa načítavajú automaticky.
Príklad 3: Context and dependency injection - automatické aktualizovanie referencií s rozličnou platnosťou
Java EE je populárny a silný nástroj na tvorbu webových aplikácií, v ktorých serverovská časť
je implementovaná v Jave a stránky, ktoré sa zobrazujú v klientskom webovom prehliadači, sú
napísané pomocou jazyka JSF (Java Server Faces). Na rozdiel od tradičného modelu skriptovaných
stránok v PHP, kde program v jazyku PHP generuje HTML kód zobrazovaný v prehliadači,
JSF umožňuje prepojiť jednotlivé prvky webstránky (editboxy, checkboxy a podobne) s premennými
nejakého objektu Javovského programu, ktorý beží na serveri a stará sa o spracovanie požiadaviek
klienta. Takéto objekty, hovorí sa im "beany" - kávové fazuľky, môžu mať
rozličnú životnosť a prepojenie na rozličné služby: niektoré existujú len po dobu spracovania
jedného HTTP requestu, iné existujú počas celej session jedného konkrétneho používateľa,
ďalšie sú spoločné pre celú aplikáciu - vytvárajú sa po nainštalovaní (deploy) aplikácie
na server a existujú až po jej odinštalovanie (undeploy). Pomocou anotácie
@Inject môžeme
napríklad do beanu, ktorý má životnosť jedného HTTP requestu, "injectnúť" bean so životnosťou
celej používateľovej session. Java EE sa stará o to, aby bola táto referencia jedného beanu
na druhý vždy správne aktualizovaná:
import java.io.Serializable;
import javax.inject.Inject;
import javax.inject.Named;
import javax.enterprise.context.SessionScoped;
@Named
@SessionScoped
public class Guess
{
// ...
}
@Named
@RequestScoped
public class Userguess implements Serializable
{
@Inject
Guess guess;
// ...
}
Anotácia
@Named zabezpečí, že na premenné zadefinované v bean-e
Guess s platnosťou celej
používateľovej session sa môžeme na JSF stránkach tejto aplikácie odkazovať pomocou
Expression Language a do stránky priamo vkladať aktuálnu hodnotu z javového objektu,
ktorá bude po vstupe od používateľa automaticky v javovom objekte na strane servera aktualizovaná:
Enter here: <h:inputText id="guessinput" value="#{guess.newguess}" />
a anotácia
@Inject znamená, že z metód triedy
Userguess môžeme priamo voľať metódy
triedy
Guess, cez premennú
guess, napríklad:
guess.restart(), pričom sa
zavolajú na inštancii, ktorá patrí tej správnej používateľovej session, hoci aplikáciu naraz používa
viacero používateľov a pre každého server automaticky udržuje jeho vlastný session bean.
Jazyk Java vývojárom dovoľuje vytvárať celkom nové anotácie s významom aký sa im
hodí. Takto si vývojárske firmy môžu vytvoriť vlastné rozšírenia frameworkov a podstatne
urýchliť a zjednodušiť vývoj aplikácií. Ak vás téma zaujala, pozrite si jednoduchú
ukážku ako vytvárať vlastné anotácie:
Creating
Custom Annotations and Using Them.
8. Čistý kód
Tvorba zdrojového kódu (programu) je síce v niektorých prípadoch mechanická a priamočiara činnosť,
často je to však veľmi náročný a tvorivý proces, pri ktorom dochádza k opakovaným vylepšeniam,
úpravám, preskupeniam, reorganizácii a podobne. Vo všetkých týchto prípadoch na to, aby sme
zapísali jeden riadok nového kódu musíme v priemere prečítať 10 riadkov existujúceho kódu.
Ak bude náš kód napísaný zrozumiteľne a čitateľne (čisto), tak aj proces jeho tvorby sa zrýchli
a hlavne - jeho životnosť vzrastie. Životnosť zdrojového kódu môžeme určiť ako dobu, po ktorej
uplynutí už ďalšie úpravy nie sú možné bez toho, aby sa celý program neprepísal odznova, pretože
program je už priveľmi komplikovaný. Čistota kódu nespočíva v nejakom jednom zázračnom pravidle,
ale dosahuje sa poctivou disciplínou a vytrvalým procesom založeným na množstve drobných zásad.
Formulovanie a pripomínanie si týchto zásad znovu a znovu má pre vývojárov veľký význam.
Podujal sa na to autor knihy Clean code, Robert C. Martin a my z nej vyberáme aspoň niekoľko
informácií.
8.1. Definície čistého kódu od popredných informatikov
Bjarne Stroustrup, autor jazyka C++: Chcem, aby môj kód bol elegantný a účinný.
Logika by mala byť priamočiara, aby sa chyby nemali kde skrývať, s minimálnymi
závislosťami, aby údržba bola jednoduchá, kompletné ošetrenie chýb v súlade s jasne
formulovanou stratégiou a s výkonom blízkym optimu, aby ľudia neboli v pokušení zavádzať
do kódu neporiadok pomocou svojvoľných optimalizácií. Čistý kód plní svoju funkciu dobre.
Grady Booch, autor známej metódy objektovo-orientovanej analýzy a návrhu:
Čistý kód je jednoduchý a priamočiary. Čistý kód sa číta ako dobre napísaná próza. Čistý
kód nikdy nezatemňuje zámer návrhára, ale je plný jasných a presvedčivých abstrakcií a
priamych tokov riadenia.
David Thomas, pôvodný vedúci vývojového tímu nástroja Eclipse:
Čistý kód je čitateľný a môže ho vylepšovať aj iný vývojár ako jeho pôvodný autor. Má jednotkové a
akceptačné testy. Používa zmysluplné názvy. Umožňuje radšej jeden spôsob vykonania úlohy,
ako viacero. Obsahuje minimálny počet závislostí, ktoré sú jasne definované. Používa API
zrozumiteľne a v minimálnej miere. Kód by mal byť kultivovaný (s dokumentačnými komentármi),
pretože všetky potrebné informácie sa nedajú vyjadriť len v samotnom kóde.
Michael Feathers, autor nástroja CPPUnit pre jednotkové testy jazyka C++:
Mohol by som vymenovať všetky dobré vlastnosti, ktoré som si u čistého kódu všimol, ale jedna z nich
je zastrešujúca a vedie ku všetkým ostatným. Čistý kód vyzerá vždy tak, ako keby ho písal niekto
poriadny a starostlivý. Neexistuje nič samozrejmého, čo môžete urobiť, aby ste ho zlepšili. O všetkých
týchto záležitostiach už autor kódu premýšľal a ak sa pokúsite uvažovať o nejakých vylepšeniach, dovedie
vás to naspäť tam, kde práve ste. Oceňujete kód, ktorý vám niekto zanechal - niekto, kto bol v tomto
odbore veľmi poriadny a skláňate sa pred ním.
Ward Cunningham, autor prvej Wiki:
To, že pracujete s čistým kódom, spoznáte podľa toho, že každá
procedúra, cez ktorú prechádzate sa ukáže byť tým, čo ste do značnej miery
predpokladali. Kód môžete označiť za nádherný, keď to vyzerá tak, ako keby
bol použitý programovací jazyk pre daný problém stvorený.
8.2. Vybrané zásady čistého kódu
1. krátke funkcie
Pri písaní textov, článkov, publikácií sa treba usilovať o krátke vety. Jedna veta by mala vyjadrovať iba jednu myšlienku. Analogia k vetám v texte sú pri písaní zdrojového kódu funkcie. Mali by byť krátke a vyjadrovať jednu myšlienku. Tento najzákladnejší princíp udržiavania
prehľadného kódu použijeme vždy, keď je to možné. Vždy keď sa z nejakej funkcie dá vytiahnuť zmysluplná časť kódu von do samostatnej funkcie, tak to treba urobiť. Výsledkom sú funkcie, ktoré sú veľmi krátke - často obsahujú len tri riadky, nevnárajú sa viac ako o dve úrovne odsadenia (napr. vnorené cykly, podmienky).
2. funkcie robia jednu vec
3. funkcie pracujú na jednej úrovni abstrakcie
4. všetky identifikátory sú výstižné pomenované, mená ktoré jasne hovoria čo robia, na čo sú určené
5. funkcie nemajú viac ako 3 argumenty
6. vyhýbame sa výstupným argumentom funkcií
7. nepoužívame boolovský argument funkcie, ktorý určuje/prepína dve alternatívne činnosti
8. funkcie nemajú mať bočné efekty
9. funkcia by mala buď niečo robiť (command) alebo niečo zisťovať (query), ale nie oboje naraz
10. ak používame výnimky, pokúsime sa kód spracovávajúci chybu oddeliť do samostatnej funkcie
11. snažíme sa písať kód tak čisto, že komentáre v zdrojových kódoch nie sú potrebné
12. zakomentovaný a mŕtvy kód (t.j. taký, ktorý je v programe, ale nikdy nebeží) odstraňujeme čo najskôr
13. snažíme sa v jednom súbore používať iba jeden programovací jazyk
14. ak poznáme názov funkcie, jej telo nás nesmie prekvapiť - malo by obsahovať zhruba to, čo podľa názvu očakávame
15. dbáme na pokrytie všetkých aj hraničných prípadov vstupov
16. kedykoľvek objavíme duplicitu v kóde, snažíme sa spoločné veci vytiahnuť do spoločnej abstraktnej nadtriedy
17. snažíme sa vyhýbať kľúčovému slovu static (v Jave)
18. v kóde nepoužívame číselné konštanty ale nahradíme ich symbolickými
19. snažíme sa vyhnúť záporom v názvoch identifikátorov
20. pri používani automatických jednotkových testov si skontrolujeme aká veľká časť kódu je testami pokrytá.
9. Agilné metódy
Ako sme v úvode naznačili, tvorba informačných systémov je veľmi dynamický proces, kde
zákazníci - zadávatelia často nevedia sformulovať svoje predstavy dostatočne presne
a vývojári ich nevedia dostatočne zastúpiť, pretože dostatočne nerozumejú oblasti,
pre ktorú informačný systém vyvíjajú.
Tento obrovský problém môžu prekonať vyššou flexibilitou a postupným približovaním sa
a zlaďovaním svojich predstáv smerom k budovanému výsledku. Takto to riešia evolučné
a inkrementálne modely vývoja informačných systémov. Prínosom je aj metóda prototypovania
v oboch jej verziách.
Úplné odtrhnutie sa od rigidných postupov pri vývoji informačných systémov zavádzajú
agilné metódy, ktoré samé o sebe ani nie sú samostatným plnohodnotným modelom vývoja IS,
ako skôr súhrnom odporúčaní a princípov pre bezbolestnejší proces vývoja.
Medzi tieto princípy patrí:
- Uprednostnenie prispôsobenia sa pred predvídaním
- Radšej flexibilita ako záväzné formulácie
- Používanie relatívne jednoduchých postupov
- Opakovaná možnosť uchopiť smerovanie projektu
- Nevyžaduje sa extrémne kvalitný návrh
- Zameranie sa na situácie z reálneho sveta a priemerné tímy
Princípy agilných metód si možno osvojiť aj len čiastočne, do určitej miery.
Dokument "Manifesto agilného vývoja softvéru"
(agilemanifesto.org), ktoré vydali poprední experti na informačné systémy, hovorí:
Ľudia a komunikácia sú viac než procesy a nástroje.
Funkčný softvér je viac než vyčerpávajúca dokumentácia.
Spolupráca so zákazníkom je viac než dojednávanie zmluvy.
Radšej reagovať na zmenu než sa držať plánu.
Aj keď časť napravo je dôležitá, viac si ceníme ľavú časť.
Pretavené do 12 princípov agilného vývoja manifesto uvádza:
Našou najvyššou prioritou je uspokojiť zákazníka skorým a sústavným dodávaním hodnotného softvéru.
Zmeny požiadaviek sú vítané dokonca aj v neskorých fázach vývoja. Agilné procesy dokážu pretaviť zmenu na konkurečnú výhodu zákazníka.
Dodávame funkčný softvér často, od niekoľkých týždňov po niekoľko mesiacov, s uprednostnením čo najkratších intervalov.
Ľudia z biznisu a vývojári musia denne spolupracovať počas celého projektu.
Postavte projekty na motivovaných ľuďoch. Poskytnite im prostredie, podporu a dôverujte im, že svoju úlohu splnia.
Najlepším spôsobom odovzdávania informácií vývojovému tímu a v tíme je osobný rozhovor.
Základným ukazovateľom napredovania je funkčný softvér.
Agilné procesy podporujú trvalo udržateľný rozvoj. Sponzori, vývojári a užívatelia by mali byť schopní trvalo udržať konštantné tempo.
Sústavný dôraz na technickú vyspelosť a kvalitný návrh podnecujú agilitu.
Jednoduchosť - umenie vykonať naozaj len to potrebné, je nevyhnutnosť.
Samoorganizované tímy vytvárajú najlepšie koncepty, požiadavky a návrhy riešení.
Tím v pravidelných intervaloch vyhodnocuje sám seba s cieľom byť efektívnejší a prispôsobuje tomu svoje správanie.
V praxi by dodržiavanie týchto zásad malo znamenať:
- extra námaha, ktorú si vyžaduje plánovanie je drahá a neefektívna
- treba sa zamerať na nasledujúci krok a vybrať najjednoduchší design ako sa dá
- nezameriavať sa na veci, ktoré budú potrebné neskôr - nadhľad sa získa postupne a je možné, že sa veci časom zmenia
- design sa musí s vývojom projektu meniť - evolúcia vs. ideálny výtvor
Jedna z najpopulárnejších agilných metód vývoja softvéru je SCRUM, ktorá sama seba vychvaľuje takto:
- Scrum je agilný proces, ktorý umožňuje zamerať sa na dodanie čo najlepšieho výsledku v najkratšom čase.
- Dovoľuje rýchlo a opakovane kontrolovať vytváranú fungujúcu verziu vyvíjaného softvéru (každé 2-4 týždne).
- Priority stanovuje obchodný zámer. Tímy sa organizujú zdola a samé určujú najlepší spôsob ako dodať nové črty najvyššej priority.
- Každé dva-štyri týždne vidieť verziu fungujúceho softvéru a je možnosť rozhodnúť sa, či ju dodať v takej podobe akú má, alebo ju zlepšiť v ďalšom šprinte.
Na rozdiel od klasických rigidných metód vývoja softvéru nie je stanovené poradie v ktorom sa
jednotlivé činnosti vykonávajú ako ukazuje nasledujúci obrázok.

Obr. 75: Pri vývoji metódou SCRUM sa vykonávajú všetky aktivity (označené na obrázku rôznymi farbami) naraz (na x-ovej osi je čas).
Nasledujúci obrázok zachytáva väčšinu podstatných čŕt metódy SCRUM:
Product Backlog je zoznam
aktuálne známych požiadaviek na systém, resp. úloh, ktoré tím musí splniť. Vývoj napreduje inkrementálne
po cykloch, ktoré sa nazývajú šprinty (
sprint) a trvajú väčšinou 2-4 týždne. Pred každým šprintom sa
zorganizuje schôdza "
Sprint Planning Meeting", kde sa z product backlogu vyberie skupina
požiadaviek, ktoré chce tím stihnúť realizovať v nasledujúcom šprinte: tvoria spolu
Sprint Backlog
a počas trvania šprintu je sprint backlog zafixovaný, požiadavky v ňom sa nemenia. Položky v backlogu
by mali byť formulované z uhla pohľadu "čo nové to prinesie zákazníkovi?".

Obr. 76: (Skoro) celý scrum v jednom obrázku.
Počas šprintu sa tímy stretávajú každých 24 hodín na krátkej 15-30 minútovej schôdzi -
"
Daily Scrum Meeting", kde každý zodpovedá na tri otázky: "Čo som urobil včera?", "Čo budem robiť dnes?",
"Čo mi stojí v ceste?". Na konci každého šprintu sa organizuje schôdza "
Sprint Review", kam sú
pozvaní všetci stakeholderi, ktorí majú záujem a kde tím prezentuje výsledky práve uskutočneného
šprintu. Výsledkom každého nového šprintu je nová verzia softvéru s novými črtami, ktorá je
pripravená na dodanie. Po každom šprinte sa organizuje spoločenské podujatie alebo schôdza
"
Sprint Retrospective", kde sa vývojári majú možnosť neformálne porozprávať o procese vývoja,
rozdelení práce a rolí akýchkoľvek ťažkostiach ktorým čelia, vymeniť si skúsenosti a nápady.
Napríklad môže každý pomenovať, čo by chcel začať robiť, čo by chcel prestať robiť a v čom by
chcel pokračovať (Start/Stop/Continue). Pre lepšiu orientáciu o množstve potrebnej a vykonanej
práce (väčšinou udávanej v hodinách) si tým vytvára tzv.
Burndown Charts.
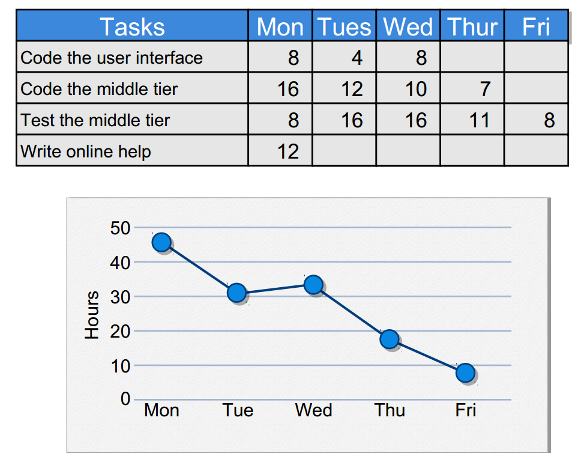
Obr. 77: Scrum burndown chart.
V metóde SCRUM existujú tri základné role, ktorých význam je potrebné si dobre uvedomiť:
- Product owner, ktorý zodpovedá za stanovenie čŕt systému a ich priorít podľa ich hodnoty pre zákazníkov a upravuje
ich pri každej iterácii, určuje termín dodania softvéru a jeho obsah, zodpovedá za rentabilitu vývoja, preberá alebo
zamieta výsledky práce.
- Scrum master, stará sa o chod projektu, o dodržiavanie pravidiel a zásad metódy SCRUM,
odstraňuje prekážky, stará sa o to, aby tím bežal na plný výkon, bol produktívny, a napomáha
úzkej spolupráci všetkých rolí, ochraňuje tím pred prerušeniami z vonka.
- Team, pozostáva z 5-9 ľudí, pokrýva všetky druhy činností (programátori, testeri, návrhári
používateľského rozhrania, atď), členovia pracujú na plný úväzok, organizujú sa zdola, členovia
tímov sa môžu meniť iba na konci šprintov.

Obr. 78: Scrum - celkový prehľad.
10. Soft Skills
Okrem sady odborných poznatkov z informatiky musí úspešný člen vývojového tímu efektívne zvládať
spoločenskú a tímovú komunikáciu, uvedomovať si svoju rolu v tíme a role ostatných, poznať
silné stránky všetkých členov tímu a vedieť, čo od nich môže očakávať, mať predstavu o tom,
ako funguje riadenie v spoločnosti, kde pracuje a ešte veľa ďalších schopností a zručností, ktoré
sa niekedy označujú termínom "soft skills". Napriek tomu, že sa nerodí každý s prirodzenou
charizmou, pri troche kontroly a sebaovládania sa každý môže rovnocenne podieľať na tímovej
spolupráci a prispievať k nej svojím rovným dielom.
10.1. Spôsoby riadenia v spoločnosti
Každá spoločnosť má nejakú vnútornú firemnú kultúru - sadu písaných a nepísaných pravidiel,
podľa ktorých funguje. Podľa najzákladnejšieho rozdelenia organizácie práce a riadenia firmy
rozlišujeme spoločnosti s rôznym spôsobom riadenia:
Silné líniové riadenie, kde sú pracovníci začlenení do jednotlivých oddelení zameraných
na konkrétny druh práce a úzko sa špecializujú. Napríklad tam môžeme nájsť oddelenie
analytikov, ktorí komunikujú so zákazníkmi pri špecifikácii systémov, návrhárov, ktorí
na základe špecifikácie vytvárajú návrh, programátorov ďalej rozdelených podľa rozličných
platforiem, testerov, dokumentačné oddelenie, správcov, ekonomické oddelenie, oddelenie
stykov z verejnosťou, oddelenie ľudských zdrojov a podobne. Ak spoločnosť začína riešiť nový
projekt, na projekt vyčlenia potrebný počet analytikov, návrhárov, programátorov, testerov,
správcov, atď., ktorí pracujú zo svojho oddelenia zaradeného do celkovej riadiacej štruktúry
firmy, prípadne projekt posúvajú z oddelenia na oddelenie ako prechádza fázami vývoja.
Výhodou je jasné rozdelenie kompetencií a zodpovednosti, dosah na realizovateľnosť,
jasný kariérny postup v organizácii, rýchla komunikácia. Pracovníci, ktorí sa venujú
jednému typu úloh získavajú v danej oblasti bohatšie skúsenosti a môžu byť produktívnejší
a efektívnejší - to si ale vyžaduje veľkú firmu s množstvom projektov.
Nevýhodou je centralizácia, ťažko sledovateľné náklady konkrétnych realizovaných úloh,
veľké množstvo administratívnych pracovníkov, flexibilnosť, a zvádza k mocenskému prístupu
k riadeniu.
Silné projektové riadenie, kde majú pracovníci priradenú svoju množinu schopností
a zručností a sú zaraďovaní na jednotlivé projekty podľa potreby. Po zaradení na projekt
podliehajú priamo vedúcemu projektu, ktorý už priamo podlieha vedeniu spoločnosti,
bez toho, aby boli pracovníci zaradený v zložitej hierarchickej štruktúre. Pracovník
môže zastávať rozličné úlohy a vykonávať v rozličných projektoch iné činnosti.
Výhodou je flexibilita pri rôznom type úloh v organizácii, sledovanie nákladov a zodpovedností,
lepšia motivácia pracovníkov.
Nevýhodou je, že si vyžaduje vyššiu kvalitu manažérov, niekedy je dosah na členov tímu problémový,
efektivita a spoľahlivosť je ohrozená, pretože tímy nie sú stabilné.
10.2. Základné postoje pri tímovej práci a v rozhodovaní/osobnostný profil
Teória o základných postojoch pri tímovej práci hovorí, že človek je kombináciou základných
profilov:
- Orientácia na základy a istoty: ide o človeka, ktorý je dobrý rutinér, spoľahlivý,
dochvilný, je každý deň v práci od 8 do 16 hodiny, má rád poriadok a jasne zadefinovanú prácu.
- Orientácia na výsledky: vysoko motivovaný jedinec, ktorý musí cítiť, že je
produktívny, každý deň, týždeň, mesiac musí za sebou vidieť zodpovedajúci kus práce, hľadá
spôsoby ako zefektívniť prácu seba i svojho tímu, motivujú ho dosiahnuté ciele, odmena a uznanie.
- Orientácia na rozvoj: človek, ktorého najviac baví objavovať nové, učiť sa,
stále sa posúvať k novým obzorom, študovať a zlepšovať seba i svoje okolie, je ochotný venovať
a obetovať veľa úsilia a zdrojov pre rozširovanie svojich vedomostí a schopností.
- Orientácia na spoluprácu: veľmi cenný člen kolektívu, ktorý dobre vychádza
so všetkými jeho členmi, zmierňuje a rieši konflikty, dobre komunikuje a má radosť predovšetkým
zo spoločného úspechu a spoločnej práce.
Obr. 79: Základné postoje pri tímovej práci - charakteristické vlastnosti a osobnostný profil.
Každý človek je v každom z uvedených štyroch smerov nejakým spôsobom
rozvinutý - podľa toho na príslušnej osi zvolíme bod: čím viac smerom
k rohu obdĺžnikového obrazca, tým viac je rozvinutý v príslušnom
kvadrante. Pospájaním takto nájdených bodov vzniká zelený štvoruholník,
ktorý tvorí osobnostný profil danej osoby.
10.3. Tímové role
Predstavme si skupinu ľudí, ktorej zadáme nejakú náročnú úlohu (napríklad
skupina na brehu rieky Dunaj pri hrade Devín má za úlohu dostať sa na druhý breh
do Rakúska) a budeme pozorovať, ako sa tejto úlohy chopia. V priebehu niekoľkých chvíľ
sa v skupine vyprofilujú určité základné charakteristické triedy správania, ktoré by sme
mohli rozdeliť na nasledujúce:
- Šéf (vedúci, koordinátor) - manažér
- kľudný, dominantný, stabilný, uznávaný
- koordinuje tím, vedie ho k spolupráci a k dosiahnutiu cieľov
- v diskusii nedominuje, jeho príspevkom je položenie správnych otázok
- jeho vedenie spočíva predovšetkým v sociálnej rovine, má osobné kúzlo a autoritu
- Navrhovateľ (režisér, konštruktér)
- činorodý, impulzívny, dominantný, extrovertný
- navrhuje a riadi práce v tíme
- vyžaduje akciu, poháňa tím k vyššej produktivite
- je spoločensky orientovaný, netrpezlivý, temperamentný
- Novátor (chrlič nápadov)
- inteligentný, individualistický, dominantný, introvertný
- prichádza s novými nápadmi a podnetmi, vyhľadáva problémy a originálnym spôsobom ich rieši
- má veľkú predstavivosť a je zdrojom inšpirácie pre celý tím
- zaujímajú ho len globálne náhľady, žiadne detaily
- Upozorňovateľ (overovateľ, rypák)
- racionálny, stabilný, skeptický, inteligentný
- hodnotí nápady, posudzuje riešenie, varuje pred chybami, hrá rolu diablovho advokáta
- dokáže jasne a zrozumiteľne analyzovať a argumentovať
- nie je príliš nadšený, ale vďaka tomu je najobjektívnejším členom tímu a je veľmi dôležitý
- Organizátor (ťahač)
- svedomitý, disciplinovaný, výkonný, stabilný
- stará sa, aby nápady a rozhodnutia boli transformovateľné do konkrétnych úloh a zaisťuje, aby boli realizované
- pracuje systematicky, má rád pevné štruktúry
- býva nepružný a potrebuje impulz - ak ho dostane, dotiahne veci do konca
- Objavovateľ (zháňač, vyhľadávač zdrojov)
- spoločenský, čulý, priateľský, dominantný
- zhromažďuje informácie a nápady, nadväzuje kontakty, získava podporu zvonku
- najlepšie sa mu darí pod tlakom, rýchlo sa nadchne, ale nadšenie ho rýchlo opustí
- je dobrý improvizátor
- Podporovateľ (hasič, strážca atmosféry)
- citlivý, mierny, extrovertný, nedominantný
- je priateľský, vie dobre vnímať a počúvať, tlmí konflikty, podporuje ostatných a stará sa o dobré vzťahy v tíme
- rozvíja nápady, všíma si potreby a problémy ostatných
- Dokončovateľ (doťahovač)
- tichý, starostlivý, úzkostlivý, introvertný
- má rád jasné pokyny
- stará sa o dodržiavanie poriadku a časových plánov
- do detailov všetko kontroluje a dáva pozor, aby sa na nič nezabudlo
- je starostlivý, občas až veľmi
- nerád deleguje prácu na ostatných
Pochopiteľne ľudia nie sú vždy presne vyhranení v jednej konkrétnej roli, ale kombináciou niekoľkých viacerých.
11. Informačné systémy v štátnej správe
Zavádzanie informačných systémov do štátnej správy a verejných služieb je obrovská výzva, ktorá
má svoje špecifiká - zadávateľom nie je súkromný zákazník, ktorý bude systém používať, ale
štátni úradníci. Formulácie požiadaviek podliehajú politickým prioritám, ktoré sa s každou
vládou mierne menia spolu s celkovou "firemnou kultúrou" riadenia krajiny a verejných projektov.
Napriek tomu si všetci politici a zodpovední úradníci uvedomujú nevyhnutnosť informatizácie
a zachovávajú aspoň čiastočnú kontinuitu. Asi najperspektívnejšie zákazky vznikajú v súlade
s národnou stratégiou, ktorú nám dáva vypracovať Európska Únia.
Slovenská Republika vstúpila do Európskej Únie 1.mája 2004 a zapojila sa tak do finančných schém
tejto inštitúcie. Tie sú pomerne komplikované a keďže sa naša krajina vzdala časti právomocí
v prospech tejto nadnárodnej inštitúcie, je dobré si urobiť o nich aspoň krátky prehľad.
Financovanie EÚ sa deje v sedemročných tzv. programových obdobiach. Predchádzajúce programové
obdobie trvalo v rokoch 2007-2013, ale v našom regióne dobieha dlhšie, vďaka výnimke, ktorú
sme dostali vzhľadom na pomalé čerpanie prostriedkov vyhradených pre krajiny v našom regióne.
Ďalšie obdobie má trvať v rokoch 2014-2020.
Obrovský objem výdavkov tvoria štrukturálne a investičné fondy (predtým nazývané štrukturálne
a kohézne), ktorých je 5 a viaceré sú zamerané na vyrovnávanie rozdielov medzi členskými krajinami.
Rozdeľovanie týchto prostriedkov zväčša riadia národné vlády a agentúry:
Európsky fond regionálneho rozvoja (EFRR)
Európsky sociálny fond (ESF)
Kohézny fond (KF)
Európsky poľnohospodársky fond pre rozvoj vidieka (EPFRV)
Európsky námorný a rybársky fond (ENRF)
Najväčšie množstvo financií EÚ prúdi do poľnohospodárskych dotácií.
Okrem toho má EÚ rôzne priame výdavky a asi 800 grantových programov rôzneho rozsahu, pričom
pre nám blízku oblasť výskumu a vzdelávania je relevantný najmä Rámcový program pre výskum
a inovácie (HORIZON 2020, 80 miliárd Eur na celé obdobie 2014-2020). Mnohé z týchto programov
riadi a prostriedky rozdeľuje priamo EÚ.
Jednotlivé krajiny si pre využívanie fondov formulujú svoje Operačné programy (OP), ktoré
zodpovedajú ich špecifickým prioritám stanoveným v Národnom rozvojovom pláne (NRP) a financujú
ich zo zdrojov zo štrukturálnych a kohéznych fondov. Operačné programy vyplývajú z konkrétnej
špecifikácie v
Národnom strategickom referenčnom rámci (NSRR), ktorý na celé programové
obdobie vypracováva a schvaľuje národná vláda a potom po konzultáciách vlády s Európskou Komisiou
(EK) a vyžiadaných úpravách ho definitívne schvaľuje EK.
Na Slovensku existovali v období 2007-2013 tieto OP:
1. Regionálny operačný program
2. Životné prostredie
3. Doprava
4. Informatizácia spoločnosti
5. Výskum a vývoj
6. Konkurencieschopnosť a hospodársky rast
7. Vzdelávanie
8. Zamestnanosť a sociálna inklúzia
9. Zdravotníctvo
10. Technická pomoc
11. Bratislavský kraj
Napokon sa dostávame k téme našej kapitoly, keďže 4. operačný program bol zameraný na informatizáciu
spoločnosti (OPIS -
operačný program informatizácia spoločnosti).
Financovanie cez OP podrobne definuje príslušný schválený dokument. OPIS určuje štyri prioritné
osi:
1. ELEKTRONIZÁCIA VEREJNEJ SPRÁVY A ROZVOJ ELEKTRONICKÝCH SLUŽIEB
2. ROZVOJ PAMÄŤOVÝCH A FONDOVÝCH INŠTITÚCIÍ A OBNOVA ICH NÁRODNEJ INFRAŠTRUKTÚRY
3. ZVÝŠENIE PRÍSTUPNOSTI K ŠIROKOPÁSMOVÉMU INTERNETU
4. TECHNICKÁ POMOC
V operačnom programe sú k dispozícii obrovské prostriedky a nepochybne existuje potenciál
na zlepšenie ich čerpania. Zoznam schválených projektov s výškou nenávratného finančného
príspevku pre jednotlivé prioritné osi čitateľ nájde na webstránke Ministersva financií SR
venovanej
informatizácii spoločnosti, alebo
priamo na stránkach
operačného programu IS, linka na
konkrétnu stránku:
Schválené
a neschválené žiadosti o nenávratný finančný príspevok projektov prioritnej osi 1 a 3,
resp.
Prijímatelia
pomoci v 2. prioritnej osi.
Z projektov pre zaujímavosť vyberáme, na stránkach prioritných osí sú uvedené podrobnosti.
Os 1 a 3:
Elektronizácia služieb matriky, Ministerstvo vnútra SR
Elektronizácia služieb Sociálnej poisťovne, Sociálna poisťovňa
Elektronické služby Ministerstva práce, sociálnych vecí a rodiny SR na úseku výkonu správy štátne sociálne dávky, sociálna pomoc a pomoc v hmotnej núdzi, Ministerstvo práce, sociálnych vecí
a rodiny SR
IS Registra fyzických osôb, Ministerstvo vnútra SR
Elektronické služby pre osvedčenie o evidencii vozidla, Ministerstvo vnútra SR
Dátové centrum obcí a miest, DataCentrum elektronizácie územnej samosprávy Slovenska
Elektronizácia služieb Mestského úradu v Žiline, Mesto Žilina
Os 2:
Digitálna galéria, Slovenská národná galéria
Digitálny pamiatkový fond, Pamiatkový úrad Slovenskej republiky
Dokumentačno-informačné centrum rómskej kultúry, Štátna vedecká knižnica v Prešove
Digitálna knižnica a digitálny archív, Slovenská národná knižnica
Digitálna audiovízia, Slovenský filmový ústav
{kind=link}
{kind=link}