Natural Language Processing
Lecture 05:
Named Entity Recognition
and Relation Extraction
Information Extraction
Goal: get simple, unambiguous, structured information by analyzing unstructured text
- Structure:
- relations (database systems)
- knowledge base (ontologies)
- Purpose:
- Organize information so that it's useful for people
- Semantically precise form allows further automated inference
IE systems extract clear, factual information
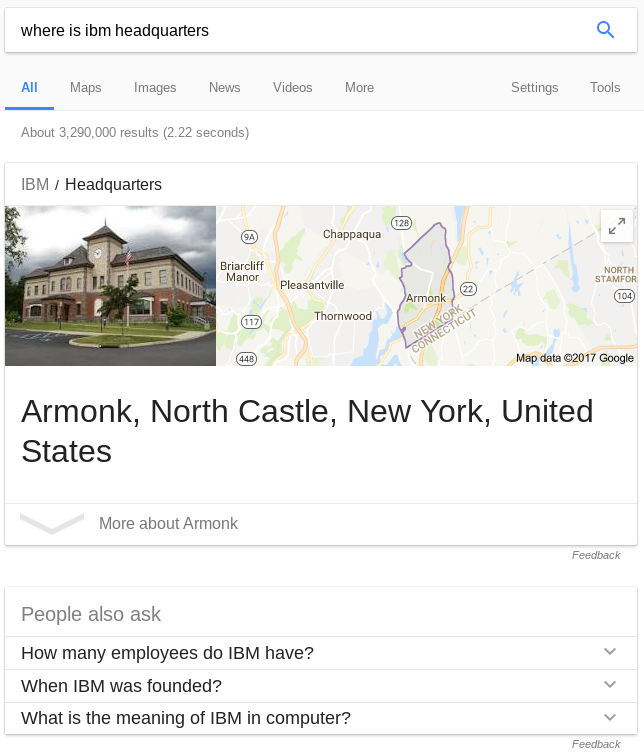
- Gathering earnings, profits, board members, headquarters, etc. from company reports
- "The headquarters of IBM are located in New York, United States"
- headquarters("IBM", "New York, United States")
Low-level information extraction
- Based on regular expressions and lexicons

Mid-level information extraction
High-level information extraction

WikiData link
WikiData link
Message Understanding Conference (MUC, 1987–1998)
Professor John Skvoretz, U. of South Carolina, Columbia, will present a seminar entitled "Embedded commitment", on Thursday, May 4th from 4-5:30 in PH 223D.
| Place | PH 223D |
| Title | Embedded commitment |
| Starting time | 4 pm |
| Speaker | Professor John Skvoretz |
Named Entity Recognition
Goal: find and classify names in text
Goal: find and classify names in text
The decision by the independent MP Andrew Wilkie to withdraw his support for the minority Labor government sounded dramatic but it should not further threaten its stability. When, after the 2010 election, Wilkie, Rob Oakeshott, Tony Windsor and the Greens agreed to support Labor, they gave just two guarantees: confidence and supply.
Goal: find and classify names in text
The decision by the independent MP Andrew Wilkie to withdraw his support for the minority Labor government sounded dramatic but it should not further threaten its stability. When, after the 2010 election, Wilkie, Rob Oakeshott, Tony Windsor and the Greens agreed to support Labor, they gave just two guarantees: confidence and supply.
Goal: find and classify names in text
The decision by the independent MP Andrew Wilkie to withdraw his support for the minority Labor government sounded dramatic but it should not further threaten its stability. When, after the 2010 election, Wilkie, Rob Oakeshott, Tony Windsor and the Greens agreed to support Labor, they gave just two guarantees: confidence and supply.
Person, Organization, DateUses
- NEs can be indexed or linked to data
- Sentiment attribution to companies or products
- Component of Information Extraction (later in lecture)
- Question answering (answers are often NEs)
- Machine Translation (do not translate names)
- Web page entity tagging
Evaluation Metrics
| Foreign | ORG | |
| Ministry | ORG | |
| spokesman | O | |
| Shen | PER | Per entity, not per token |
| Guofang | PER | |
| told | O | |
| Reuters | ORG |
- Precision and recall pose a problem with multi-word expressions
- Boundary errors:
- "First Bank of Chicago announced earnings ..."
- The entity should be First Bank of Chicago
- The system identified Bank of Chicago
- Counts as both a FP and FN
- Selecting nothing would be better
- Other metrics (MUC scorer) give partial credit according to complex rules
- The rules are too complex; in practice, papers tend to ignore this phenomenon and use the simple F1 score
Recognizing named entities
Training
- Collect training documents
- Define entity classes
- Annotate each token for its entity class or "other"
- Select representative features
- Train a sequence classifier
Testing
- Receive a set of testing documents
- Run sequence model inference to label each token
IOB (BILOU) encoding
| Foreign | B-ORG |
| Ministry | I-ORG |
| spokesman | O |
| Shen | B-PER |
| Guofang | I-PER |
| told | O |
| Reuters | B-ORG |
Beginning, Inside, Last, Other (Outside), Unit
Feature selection
- Words
- Current word
- Surrounding words
- Linguistic annotation
- Morphology (proper nouns are usually entities)
- Syntax (subjects and objects are usually entities)
- Semantics (a country is a location)
- Label context (previous, next labels)
Feature selection
- Word substrings
- "Cotrimoxazole": a drug rather than a movie
- "Wethersfield": a place rather than a drug
- Word shapes
simple representations that encode attributes: length, capitalization, numerals, Greek letters, internal punctuation, etc.
| Varicella-zoster | Xx|-xxx |
| mRNA | xXXX |
| CPA1 | XXXd |
Supervised ML
- HMM (Bikel et al., 1997)
- Decision trees (Sekine, 1998)
- Maximim entropy models (Borthwick, 1998)
- SVM (Asahara & Matsumoto, 2003)
- MEMM (Strakova et al., 2013) — NameTag
Sequence models
- See data as a sequence of characters / words / phrases / sentences
- Task: label each item in the sequence

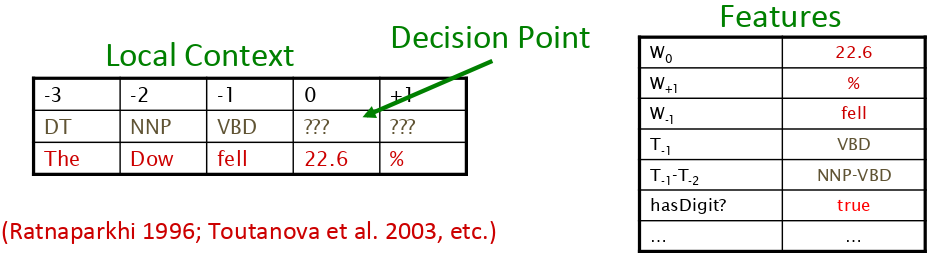
Maximum Entropy Markov Model (MEMM)
- Also known as Conditional Markov Model (CMM)
- Makes a single decision at a time, conditioned on the current observation and previous label (or in broader neighborhood)
MEMM: Formal definition
- Given the sequence of observations $O_1, ..., O_n$
we try to find the labels $S_1, ..., S_n$
that maximize the conditional probability $P(S_1, ..., S_n | O_1, ..., O_n)$ - This probability is factored into Markov transition probabilities
- $$P(S_1, ..., S_n | O_1, ..., O_n) = \prod_{t=1}^{n} P(S_t | S_{t - 1}, O_t)$$
- For each possible previous label value $s^\prime$, the probability of label $s$ is modeled as in MaxEnt classifier:
- $$P(s | s^\prime, o) = P_{s^\prime}(s | o) = \frac{exp(\sum_{i} \lambda_i f_i(s, o))}{Z(o, s^\prime)}$$
- where $f_i(s, o)$ is a feature function and $Z(o, s^\prime)$ is a normalization term.
Example: POS Tagging
- Features:
- Current, previous, next words
- Previous one, two, three tags
- Word-internal features: word types, suffixes, dashes, ...
Inference in Systems

Greedy Inference

- Greedy inference
- We start at the left and use our classifier at each position to assign a label
- The classifier can depend on previous labels as well as observed data
- Advantages
- Fast, no extra memory requirements
- Very easy to implement
- With rich features (incl. future observations) it may perform well
- Disadvantage
- Greedy - once we make a mistake, we cannot recover
Beam Inference
- Beam inference
- At each position keep the top k complete sequences
- Extend each sequence in each local way
- The extensions compete for the k slots at the next position
- Advantages
- Fast; beam sizes of 3-5 are almost as good as exact inference
- Easy to implement (no dynamic programming)
- Disadvantage
- Inexact: the globally best sequence can fall off the beam
Viterbi Inference
- Viterbi inference
- Dynamic programming or memoization
- Requires small window of state influence (e.g. past two states)
- Advantage
- Exact: the global best sequence is returned
- Disadvantage
- Harder to implement long-distance state-state interactions (beam inference tends not to support this anyway)
Viterbi Inference
Speech and Language Processing (3rd ed. draft)
- For MEMM use
Example: NameTag
Straková et al., 2013: A New State-of-The-Art Czech Named Entity RecognizerStraková et al., 2014: Open-Source Tools for Morphology, Lemmatization, POS Tagging and Named Entity Recognition

- Uses BILOU NE encoding
- F-score: 82.82 CZ, 89.16 EN
- English Dataset: CoNLL-2003 shared task
- Czech Dataset: CNEC (Czech Named Entity Corpus)
- For comparison, the best result is 90.80 for EN (regularized averaged perceptron, 2009)
Information Extraction
Goal: get simple, unambiguous, structured information out of text
Relation Extraction
- Input: document, set of detected named entities
- Output: set of (NE1, R, NE2) triples
Information extraction in triples
Ľ. Štúr Institute of Linguistics of the Slovak Academy of Sciences is a primary institution in the Slovak Republic that focuses on basic research of standard and non-standard variants of the Slovak language. The institute was established in 1943 and named the Institute of Linguistics of the Slovak Academy of Sciences and Arts (Slovak shortening SAVU), ... The research focuses also on the theoretical questions of general linguistics, language culture, professional terminology and onomastics.
Information extraction in triples
Ľ. Štúr Institute of Linguistics of the Slovak Academy of Sciences is a primary institution in the Slovak Republic that focuses on basic research of standard and non-standard variants of the Slovak language. The institute was established in 1943 and named the Institute of Linguistics of the Slovak Academy of Sciences and Arts (Slovak shortening SAVU), ... The research focuses on the theoretical questions of general linguistics, language culture, professional terminology and onomastics.
| Ľ. Štúr Institute… | PART-OF | Slovak Academy of Sciences |
| Ľ. Štúr Institute… | LOC-IN | Slovak Republic |
| Ľ. Štúr Institute… | FOUNDED-IN | 1943 |
| Ľ. Štúr Institute… | EQ | Institute of Linguistics of… |
| Slovak Academy of Sciences and Arts | ABBR | SAVU |
| Ľ. Štúr Institute… | RSRCH-IN | general linguistics |
| Ľ. Štúr Institute… | RSRCH-IN | language culture |
| Ľ. Štúr Institute… | RSRCH-IN | professional terminology |
| Ľ. Štúr Institute… | RSRCH-IN | onomastics |
UMLS: Unified Medical Language System
| Injury | disrupts | Physiological Function |
| Bodily Location | location-of | Biologic Function |
| Anatomical Structure | part-of | Organism |
| Pharmacologic Substance | causes | Pathological Function |
| Pharmacologic Substance | treats | Pathologic Function |
Doppler echocardiography can be used to diagnose left anterior descending artery stenosis in patients with type 2 diabetes.
| Echocardiography, Doppler | diagnoses | Acquired stenosis |
Goal: get simple structured information out of text
Why?
- Organize information so that it is useful for people
- Put it in a semantically precise form allowing machines to query and infer new facts
How?
- Store the extracted information in triplestores (RDF/OWL)
- May be queried using SPARQL
Ontology
Formal conceptualization of entities and relations between them
- Individuals
- Concepts
- Attributes
- Relations
- Function terms
SPARQL
PREFIX ex: <http://example.com/exampleOntology#>
SELECT ?capital ?country
WHERE {
?x ex:cityname ?capital ;
ex:isCapitalOf ?y .
?y ex:countryname ?country ;
ex:isInContinent ex:Africa .
}
Uses
- Create new knowledge bases
- Medicine (SNOMED, ...)
- Digital Humanities
- Terminology database
- Question answering
- Expert systems (medicine, …)
- Digital Humanities (Stanford Encyclopedia of Philosophy, ...)
- Linked data
Linked data

What is needed (in general)
- Collect training documents
- Define relation classes
- Annotate each relation between named entities
- Build a classifier (hand-made / machine learning)
- Rule-based
- Supervised learning
- Semi-supervised learning
- Unsupervised learning
Rule-based systems
Agar is a substance prepared from a mixture of red algae, such as Gelidium, for laboratory or industrial use.
| Y such as X ((, X)* (, and|or) X) |
| such Y as X |
| X or other Y |
| X and other Y |
| Y including X |
| Y, especially X |
Richer relations using named entities
- located-in (ORGANIZATION, LOCATION)
- founded (PERSON, ORGANIZATION)
- cures (DRUG, DISEASE)
Problem
- DRUG cures DISEASE
- DRUG prevents DISEASE
- DRUG causes DISEASE
- Plus
- Hand-made patterns: high precision
- Can be tailored to specific domains
- Minus
- Hand-made patterns: low recall
- A lot of manual work for each relation class
- Low accuracy
Supervised machine learning
- Choose the set of relations to extract
- Choose the set of relevant named entities
- Find and label relations between entities
- Select representative features
- Train a classifier
- Maximum entropy
- Naïve Bayes
- SVM
Classification in supervised RE
- Find all pairs of named entities
- Decide if 2 entities are related
- If yes, classify the relation
- Faster classification training by eliminating most pairs
- Can use distinct feature-sets appropriate for each pair-type
Features for Relation Extraction
Word features
American Airlines, a unit of AMR, immediately matched the move, spokesman Tim Wagner said.
- Mention 1: American Airlines
- Mention 2: Tim Wagner
- Headwords of M1 and M2, and combination
- Airlines, Wagner, Airlines-Wagner
- Words or bigrams left and right of mentions
- M2: -1 spokesman
- M2: +1 said
- Bag of words or bigrams between the entities
- {a, AMR, of, immediately, matched, move, spokesman, the, unit}
Features for Relation Extraction
Named entity features
American Airlines, a unit of AMR, immediately matched the move, spokesman Tim Wagner said.
- Named entity types or their concatenation
- M1: ORG
- M2: PERSON
- CONCAT: ORG-PERSON
- Entity level of M1 and M2 (NAME, NOMINAL, PRONOUN)
- M1: NAME ("it" or "he" would be PRONOUN)
- M2: NAME ("the company" would be NOMINAL)
Features for Relation Extraction
Parse features
American Airlines, a unit of AMR, immediately matched the move, spokesman Tim Wagner said.
- Base syntactic chunk sequence from M1 to M2
- NP → NP → PP → VP → NP → NP
- Constituent path through the tree from one to the other
- NP ↑ NP ↑ S ↑ S ↓ NP)
- Dependency path
- Airlines ←subj matched ←comp said →subj Wagner
Features for Relation Extraction
Gazetteer and trigger word features
- Trigger list for family: kinship terms
- parent, wife, husband, grandparent, etc.
- Gazetteer
- List of useful geographical or geopolitical words
- Country name list
- Other sub-entities
- Plus
- Can achieve high accuracy with enough data
- Minus
- Needs a large corpus of hand-labeled data
- Supervised models do not generalize well to different genres
Semi-supervised machine learning
For each relation, do
- Gather a set of seed entity pairs
- Iterate:
- Find sentences with these pairs
- Look at the context and create a pattern
- Use the patterns to find more pairs
Start with 5 seed pairs
| Isaac Asimov | The Robots of Dawn |
| David Brin | Startide Rising |
| James Gleick | Chaos: Making a New Science |
| Charles Dickens | Great Expectations |
| William Shakespeare | The Comedy of Errors |
- Find instances of the seed pairs
- The Comedy of Errors, by William Shakespeare, was
- The Comedy of Errors, by William Shakespeare, is
- The Comedy of Errors, one of William Shakespeare's, earliest attempts
- The Comedy of Errors, one of William Shakespeare's most
- Extract patterns (group by middle, take longest common prefix/suffix
- ?x, by ?y
- ?x, one of ?y's
- Iterate with expanded pattern set
Snowball
E. Agichtein and L. Gravano 2000- Similar iterative algorithm
- Group instances with similar prefix, middle, suffix; extract patterns
- Require that X and Y be named entities
- Compute confidence for each pattern
| Organization | Headquarters |
|---|---|
| Microsoft | Redmond |
| Exxon | Irving |
| IBM | Armonk |
.69 ORGANIZATION {'s, in, headquarters} LOCATION
.75 LOCATION {in, based} ORGANIZATION
- Plus
- Can achieve high accuracy
- A few seeds are easy to define
- Minus
- Supervised models do not generalize well to different genres
- Difficult to evaluate
Unsupervised machine learning
Extract relations from the web; no training data, no list of relations
- Use parsed data to train a "trustworthy tuple" classifier
- Extract all relations between NPs, keep if trustworthy
- Assessor ranks relations based on text redundancy
Tesla invented coil transformer
Evaluation of Semi-supervised and Unsupervised Relation Extraction
- Extracted relations are new, there is no test set
- Cannot compute precision (don't know which ones are correct)
- Cannot compute recall (don't know which ones were missed)
- Use approximation of precision: draw a random sample, check manually
- Can also compute precision at different levels of recall
- Precision for top $10^3$, $10^4$, ... new relations
- In each case taking a random sample of that set
- No way to evaluate recall
- Plus
- No training set or seeds needed
- Generalizes well to different genres
- Minus
- Little control of the model
- Difficult to evaluate
Summary
A lot of work to do…
- Select representative set(s) of named entities
- Select representative set(s) of relations
- Hand-label named entities
- Construct seed pairs
…but definitely worth it
- Useful in plenty of NLP and corpus linguistics tasks
- A huge step forward in text processing and AI